Python urllib3模块详解
2021-02-03 10:18
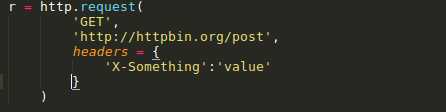
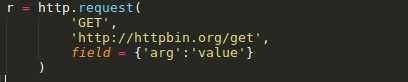
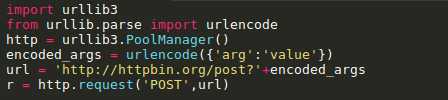
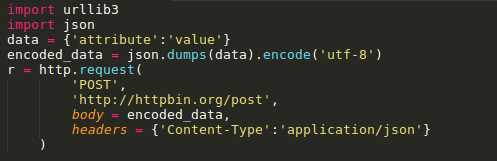
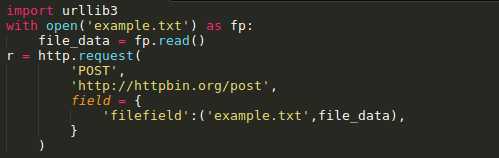
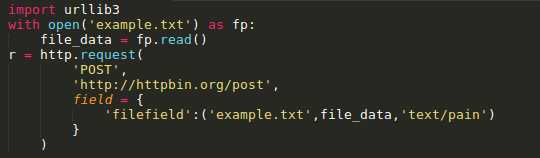
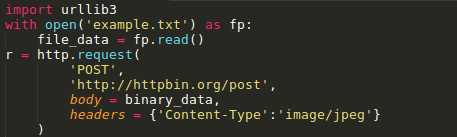
标签:log manager 文件的 load for ssl 操作 线程 开始 Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3。Urllib3提供了很多python标准库里所没有的重要特性: 1、 线程安全 2、 连接池 3、 客户端SSL/TLS验证 4、 文件分部编码上传 5、 协助处理重复请求和HTTP重定位 6、 支持压缩编码 7、 支持HTTP和SOCKS代理 8、 100%测试覆盖率 Urllib3功能非常强大,但是用起来却十分简单: 安装: Urllib3 能通过pip来安装: $pip install urllib3 你也可以在github上下载最新的源码,解压之后进行安装: $git clone git://github.com/shazow/urllib3.git $python setup.py install urllib3的使用: 生成请求(request): 首先,你必须导入urllib3模块: 然后你需要一个PoolManager实例来生成请求,由该实例对象处理与线程池的连接以及线程安全的所有细节,不需要任何人为操作: 通过request()方法创建一个请求: request()方法返回一个HTTPResponse对象。 你还可以通过request()方法向请求(request)中添加一些其他信息,如: 请求(request)中的数据项(request data)可包括: Headers: 在request()方法中,可以定义一个字典类型(dictionary),并作为headers参数传入: Query parameters: 对于GET、HEAD和DELETE请求,可以简单的通过定义一个字典类型作为fields参数传入即可: 对于POST和PUT请求(request),需要手动对传入数据进行编码,然后加在URL之后: Form data: 对于PUT和POST请求(request),urllib3会自动将字典类型的field参数编码成表格类型. JSON: 在发起请求时,可以通过定义body 参数并定义headers的Content-Type参数来发送一个已经过编译的JSON数据: Files & binary data: 使用multipart/form-data编码方式上传文件,可以使用和传入Form data数据一样的方法进行,并将文件定义为一个元组的形式 (file_name,file_data): 文件名(filename)的定义不是严格要求的,但是推荐使用,以使得表现得更像浏览器。同时,还可以向元组中再增加一个数据来定义文件的 MIME类型: 如果是发送原始二进制数据,只要将其定义为body参数即可。同时,建议对header的Content-Type参数进行 stream流式响应的处理 设置: Timeout : 使用timeout,可以控制请求的运行时间。在一些简单的应用中,可以将timeout参数设置为一个浮点数: 要进行更精细的控制,可以使用Timeout实例,将连接的timeout和读的timeout分开设置: 如果想让所有的request都遵循一个timeout,可以将timeout参数定义在PoolManager中: 或者 当在具体的request中再次定义timeout时,会覆盖PoolManager层面上的timeout。 请求重试(retrying requests): Urllib3 可以自动重试幂等请求,原理和handles redirect一样。可以通过设置retries参数对重试进行控制。Urllib3默认进行3次请求重 试,并进行3次方向改变。 给retries参数定义一个整型来改变请求重试的次数: 关闭请求重试(retrying request)及重定向(redirect)只要将retries定义为False即可: 关闭重定向(redirect)但保持重试(retrying request),将redirect参数定义为False即可: 要进行更精细的控制,可以使用retry实例,通过该实例可以对请求的重试进行更精细的控制。 例如,进行3次请求重试,但是只进行2次重定向: 如果想让所有请求都遵循一个retry策略,可以在PoolManager中定义retry参数: 或者 当在具体的request中再次定义retry时,会覆盖 PoolManager层面上的retry。 Python urllib3模块详解 标签:log manager 文件的 load for ssl 操作 线程 开始 原文地址:https://www.cnblogs.com/lincappu/p/12801817.html

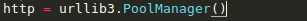


>>> import urllib3
>>> http = urllib3.PoolManager()
>>> r = http.request(‘GET‘, ‘http://httpbin.org/bytes/1024‘, preload_content=False)
>>> for chunk in r.stream(32):
... print(chunk)
...
>>> r.release_conn()
注意:preload_content=False表示流式处理响应数据。
处理stream()方法读取响应数据之外,还可以使用read()方法,示例如下:
>>> import urllib3
>>> http = urllib3.PoolManager()
>>> r = http.request(‘GET‘, ‘http://httpbin.org/bytes/1024‘, preload_content=False)
>>> r.read(4)
b‘\x88\x1f\x8b\xe5‘
>>> r.release_conn()










文章标题:Python urllib3模块详解
文章链接:http://soscw.com/index.php/essay/50378.html