目标检测算法-YOLO算法纵向对比理解
2021-02-05 18:18
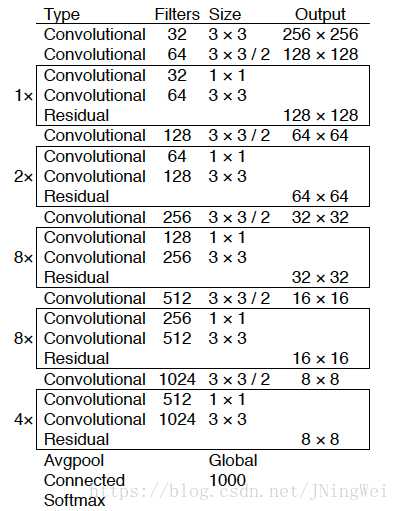
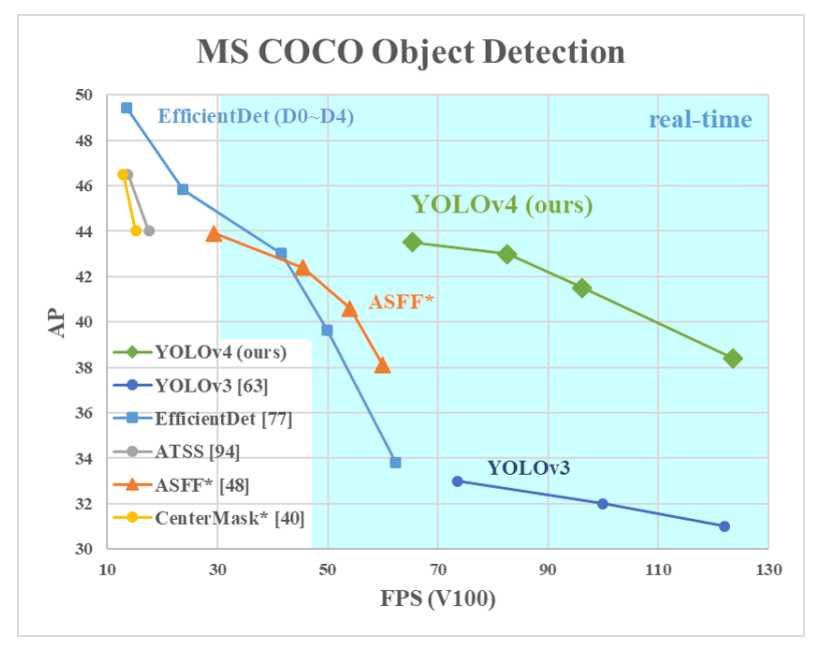
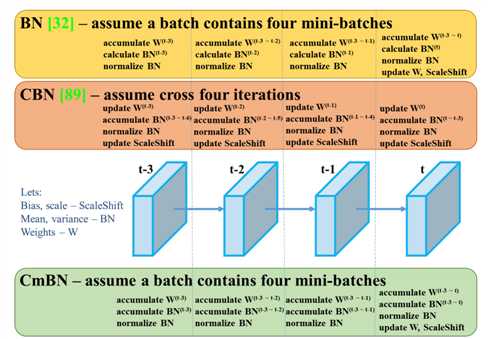
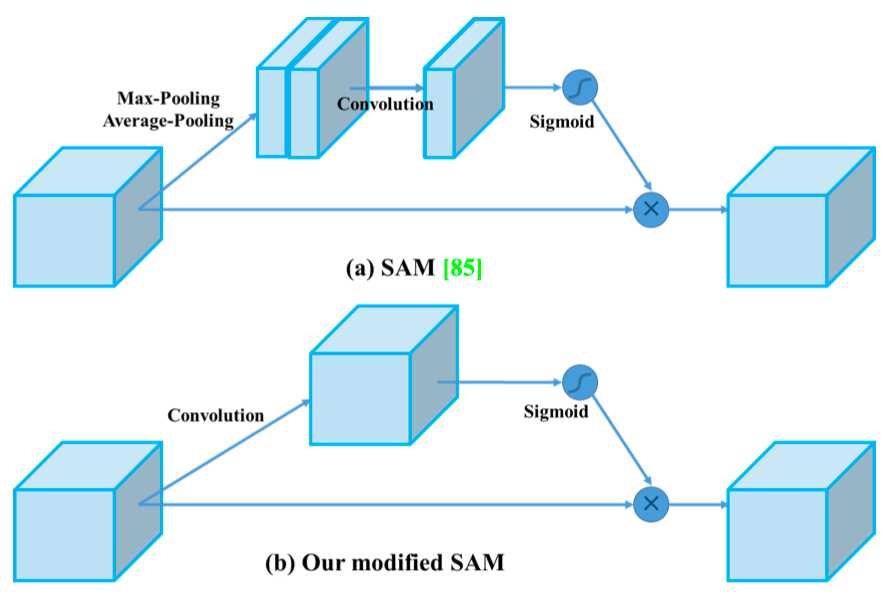
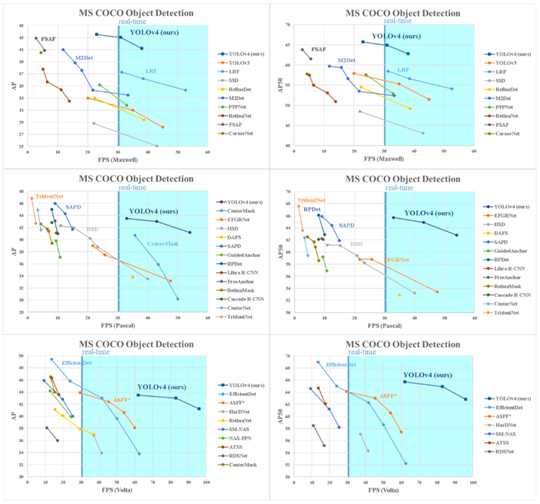
标签:nta mina evel 研究 abs ict 速度 fine 改进 目标检测算法-YOLO算法纵向对比理解 DeepLearning的目标检测任务主要有两大类:一段式,两段式 其中两段式主要包括RCNN、FastRCNN、FasterRCNN为代表, 一段式主要包括YOLO,SSD等算法 由于一段式直接在最后进行分类(判断所属类别)和回归(标记物体的位置框框),所以现在一段式大有发展。 YOLO v1 论文地址:You Only Look Once: Unified, Real-Time Object Detection YOLOv1是one-stage detector鼻祖、real-time detector鼻祖。 所谓one-stage,即不需额外一个stage来生成RP,而是直接分类回归出output: YOLOv1直接将整张图片分成 S×S的小格子区域,每个小格子区域生成 B个bbox(论文中B=2),每个bbox用来预测中心点落在该格的物体。但是每个格子生成的所有B个bbox共享一个分类score YOLOv1最后一层的输出是一个S×S×(B∗5+C) 的tensor YOLO v1包括24个conv layer + 2 fc layer YOLOv1采用了山寨版的GoogleNet作为backbone,而不是VGG Net; 在第24层时,每个单点对应原图的感受野达到了782×782。而原图只有448×448,覆盖了整张原图。也就意味着, 到了第24层的时候,每个单点都能看到整张原图。更不要提第25、26层是两个fc操作了。 另外,快速版本的YOLO v1:Fast YOLOv1=9×Conv+2×FC。速度更快,但精度也略低。 这里提供一个感受野计算神器: https://fomoro.com/research/article/receptive-field-calculator#3,1,1,VALID;2,2,1,VALID;3,1,1,VALID;2,2,1,VALID;3,1,1,VALID;3,1,1,VALID;2,2,1,VALID YOLO v2 论文地址:YOLO9000: Better, Faster, Stronger 2.0版本的算法作者发明的一系列骚操作(Dimension Clusters、Direct location prediction、Multi-Scale Training、DarkNet-19) Dimension Clusters (维度聚类) 。经过对VOC数据集和COCO数据集中bbox的k-means聚类分析,将anchor机制中原本惯用的 9 anchor 法则 删减为仅保留最常出现的 5 anchor 。其中,狭长型的anchor是被保留的主体。 Direct location prediction (直接位置预测) 。用新的位置预测算法来缩小参数范围,使之更容易学习,也使得网络更加稳定。 引入Batch Normalization,涨0.2。 训练分类的阶段,每10个epoch就在448×448的高像素图片上fine-tune一下,使之能更好地适应高像素的输入图像。该操作对mAP涨0.4。 抛弃后段的FC层,改用anchor机制来预测bbox。该操作虽然使得mAP从69.5降至69.2,但是召回率从81暴涨至88。 Dimension Clusters (维度聚类) 。经过对VOC数据集和COCO数据集中bbox的k-means聚类分析,将anchor机制中原本惯用的 9 anchor 法则 删减为仅保留最常出现的 5 anchor 。其中,狭长型的anchor是被保留的主体。 在 26×26 size层设置了通道层接至 13×13 size层。号称保留了更多的位置信息,从而提升细粒度分类的能力。本质上即为single-scale上处理two-scale的feature map信息。该操作涨点1。 Multi-Scale Training (多尺度训练) 。每10个batch就在 320,352,...,608(均为32整数倍)320,352,...,608(均为32整数倍) 中随机选择一个新的input size,该操作据说能锻炼对多尺度input的预测能力。个人感觉这就是集成学习。 作者嫌弃主流backbone VGG-16计算量太大(224×224的图像需要计算30.69 billion次浮点运算),于是自己发明了DarkNet-19出来。 softmax嵌套softmax,从而实现分级语法树,带有分级语法树的YOLOv2,进化为了YOLO9000 YOLO v2结构 YOLOv2的网络架构,22卷积层,global average pooling替代了FC(全连接层) YOLO v3 论文地址:YOLOv3: An Incremental Improvement backbone从darknet-19玩到了darknet-53 该文章继承了YOLOv2的bbox预测任务的方法,对bbox分类任务进行了修改 (用简单的logistic替换下softmax) YOLO v3结构 且大大改善了YOLO之前的一大弊病:小物体漏检。使之在APs这一单项上能够达到和 FPN 同级别,且仅逊于RetinaNet的程度 YOLO v4 论文地址:YOLOv4: Optimal Speed and Accuracy of Object Detection 代码地址:https://github.com/AlexeyAB/darknet 作者对比了 YOLOv4 和当前最优目标检测器,发现 YOLOv4 在取得与 EfficientDet 同等性能的情况下,速度是 EfficientDet 的二倍!此外,与 YOLOv3 相比,新版本的 AP 和 FPS 分别提高了 10% 和 12%。笔者刚撸完EfficientDet,结果更牛又出来了。。。 作者创新之处 加权残差连接(WRC) Cross-Stage-Partial-connection,CSP Cross mini-Batch Normalization,CmBN 自对抗训练(Self-adversarial-training,SAT) Mish 激活(Mish-activation) Mosaic 数据增强 DropBlock 正则化 CIoU 损失 YoloV4 的基本目标是提高生产系统中神经网络的运行速度,同时为并行计算做出优化,而不是针对低计算量理论指标(BFLOP)进行优化。YoloV4 的作者提出了两种实时神经网络: 对于 GPU,研究者在卷积层中使用少量组(1-8 组):CSPResNeXt50 / CSPDarknet53; 对于 VPU,研究者使用了分组卷积(grouped-convolution),但避免使用 Squeeze-and-excitement(SE)块。具体而言,它包括以下模型:EfficientNet-lite / MixNet / GhostNet / MobileNetV3 YOLOv4 包含以下三部分: backbone网络:CSPDarknet53 Neck:SPP、PAN Head:YOLOv3 具体而言,YOLO v4 使用了: 用于骨干网络的 Bag of Freebies(BoF):CutMix 和 Mosaic 数据增强、DropBlock 正则化和类标签平滑; 用于骨干网络的 Bag of Specials(BoS):Mish 激活、CSP 和多输入加权残差连接(MiWRC); 用于检测器的 Bag of Freebies(BoF):CIoU-loss、CmBN、DropBlock 正则化、Mosaic 数据增强、自对抗训练、消除网格敏感性(Eliminate grid sensitivity)、针对一个真值使用多个锚、余弦退火调度器、优化超参数和随机训练形状; 用于检测器的 Bag of Specials(BoS):Mish 激活、SPP 块、SAM 块、PAN 路径聚合块和 DIoU-NMS。 为了使检测器更适合在单个 GPU 上进行训练,研究者还做出了以下额外的设计与改进: 提出新型数据增强方法 Mosaic 和自对抗训练(SAT); 在应用遗传算法时选择最优超参数; 新型数据增强方法 Mosaic 混合了 4 张训练图像,而 CutMix 只混合了两张输入图像。 自对抗训练(SAT)也是一种新的数据增强方法,它包括两个阶段。第一个阶段中,神经网络更改原始图像;第二阶段中,训练神经网络以正常方式在修改后的图像上执行目标检测任务。 CmBN 是 CBN 的改进版,它仅收集单个批次内 mini-batch 之间的统计数据。 还将 SAM 从空间注意力机制(spatial-wise attention)修改为点注意力机制(point-wise attention),并将 PAN 中的捷径连接替换为级联: YOLO v4 与其他 SOTA 目标检测器的对比结果如下图示。从图上可以看出,YOLOv4 位于帕累托最优曲线上,并在速度和准确性上都优于最快和最精准的检测器。 reference: [1] https://blog.csdn.net/jningwei/article/details/80010567 [2] https://zhuanlan.zhihu.com/p/73606306?from_voters_page=true [3] https://cloud.tencent.com/developer/article/1347518 [4] https://blog.csdn.net/jningwei/article/details/80022603 [5] https://tech.sina.com.cn/roll/2020-04-24/doc-iircuyvh9580271.shtml 目标检测算法-YOLO算法纵向对比理解 标签:nta mina evel 研究 abs ict 速度 fine 改进 原文地址:https://www.cnblogs.com/nanmi/p/12785770.html


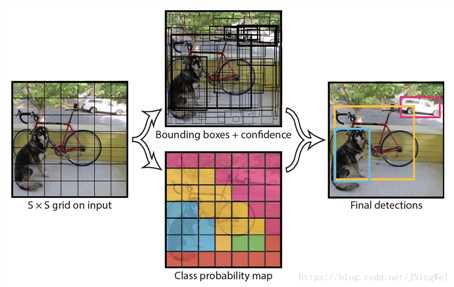
其中,S为每维的格子段数,B为每格生成的bbox数,C为前景类别数。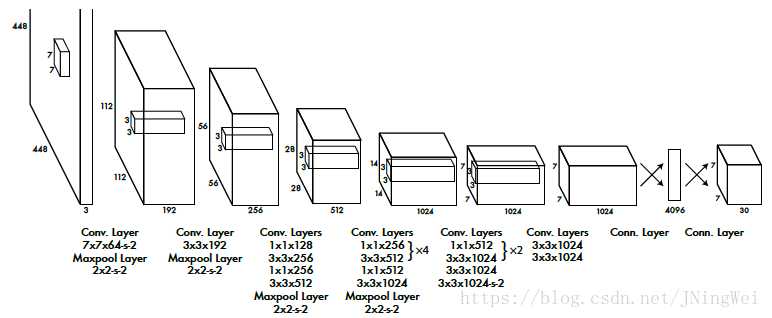
新的 encode/decode机制 —— Direct location prediction (直接位置预测) 。号称用新的位置预测算法来缩小参数范围,使之更容易学习,也使得网络更加稳定。然而现在看来并没有什么影响力,大家主流用的还是Faster R-CNN中设计好的那一套encode/decode机制。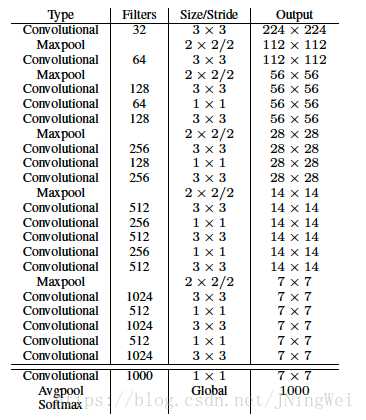

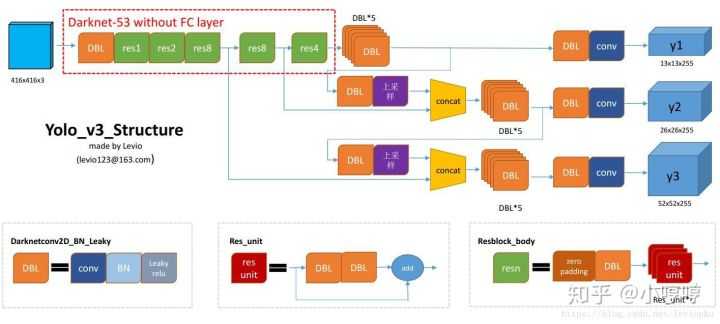

文章标题:目标检测算法-YOLO算法纵向对比理解
文章链接:http://soscw.com/index.php/essay/51453.html