获取html内容之后,如何提取信息:使用正则表达式筛选
2021-02-05 19:18
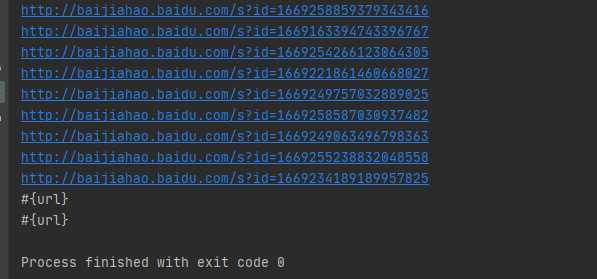
标签:区别 html 内容 load reg pytho gen 数据量 firefox 在能够获取到网页内容之后,发现内容很多,那么下一步要做信息的筛选,就和之前的筛选图片那样 而在python中可以通过正则表达式去筛选自己想要的数据 1.首先分析页面内容信息,确定正则表达式。例如想获取下面这些内容的链接 可以通过筛选出符合 2.在python中用正则表达式去筛选数据,在python中有两种方法实现: 第一种: 第二种: 这两种方法都能实现数据的筛选,他们的区别主要是:是否使用re.compile()。这个实际影响到的是大数据量级时的性能,目前仅作了解。 另外,关于正则学习的内容可以参考这里:https://www.runoob.com/regexp/regexp-tutorial.html 最后是简单的筛选href内容的代码和结果,结果里看出有些href内容并不是http链接,这个时候可以做二次处理。例如,判断是否包含"http"字符串等: 获取html内容之后,如何提取信息:使用正则表达式筛选 标签:区别 html 内容 load reg pytho gen 数据量 firefox 原文地址:https://www.cnblogs.com/blackAlice/p/13122329.html
import re
import urllib.request
# 设置headers和URL
url = "https://news.baidu.com/"
headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0‘}
req = urllib.request.Request(url=url, headers=headers)
# 请求指定URL,获取内容
html = urllib.request.urlopen(req).read().decode(‘UTF-8‘, ‘ignore‘)
#筛选出href内容并打印
reg = r‘
上一篇:PHP配置文件www.conf
下一篇:JS继承
文章标题:获取html内容之后,如何提取信息:使用正则表达式筛选
文章链接:http://soscw.com/index.php/essay/51474.html