手把手教你使用Python爬取西刺代理数据(上篇)
2021-02-06 09:15
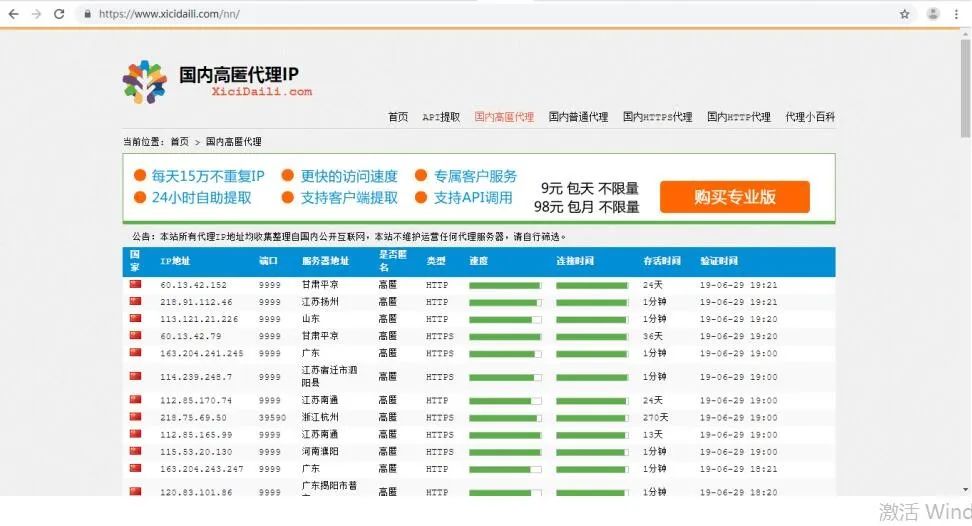
标签:为我 构建 strip blank link ali 免费 spl 推出 /1 前言/ 细心的小伙伴应该知道上次小编发布了一篇关于IP代理的文章,基于Python网络爬虫技术,主要介绍了去IP代理网站上抓取可用IP,并且Python脚本实现验证IP地址的时效性,如遇到爬虫被禁的情况就可以用文章中的办法进行解决。如果没有来得及上车的小伙伴,可以戳这篇文章看看:手把手教你用免费代理ip爬数据。 接下来小编要推出的三篇文章,分别从代理网站的介绍和反爬措施介绍、数据抓取、数据可视化操作三方面进行展开,各个方面独占一文,希望对大家的学习有帮助。接下来小编先介绍代理网站及其反爬措施。 /2 简介/ 西次代理网站是国内收录国内代理的网站,实时数量达到数十万条,上面有很多的代理IP,有的是免费的,有的是付费的。免费的一般是不可用的,即便当时好用,但是也挺不了多久,就会凉凉。 /3 反爬虫措施/ 本文主要内容为使用 Python 对该网站数据进行爬取,其中爬虫主要利用 requests 库,下面先针对反爬虫措施进行简介。 经过前期测试时发现,该网站反爬虫处理措施很多,测试到有以下几个: 直接使用** requests** 库,在不设置任何 header 的情况下,网站直接不返回数据。 同一个 ip 连续访问 40 多次,直接封掉 ip,起初我的** ip** 就是这样被封掉的。 为了解决这两个问题,最后经过研究,使用以下方法,可以有效解决: 通过抓取正常网络流量,获取正常的 构建代理池,首先从其他网站获取一批初始代理,利用这些代理在爬取该网站的代理数 据时将爬取到的代理实时加入进来,每次爬取时随机选择一个代理池中的代理,同时,及时将那些失效或者被封的代理移出代理池。这样,我们就不用担心一个ip用久了就被封掉。 为了正常的获取 提取数据之后,将该数据封装成 requests 库可以识别的 header 字典, 供其调用,这样通过使用正常的数据包,我们就不用担心网站使用头部校验了。在代码中,专门定义一个函数,只需要调用该函数就可以得到该字典: 然后在 至此,针对反爬虫的措施我们已经提前做好了准备,下一步将进行网页结构的分析以及网页数据的提取,具体实现咱们下篇文章进行详解。 /4 小结/ 本文主要内容为对代理网站进行了基本简介,而后对代理网站的反爬虫措施进行简介。之后使用抓包工具 Fiddler 对该网站的数据包进行抓取,基于 Python 中的爬虫库 requests ,提前部署了请求头,模拟浏览器。下篇文章将带大家进行网页结构的分析以及网页数据的提取,敬请期待~~ 手把手教你使用Python爬取西刺代理数据(上篇) 标签:为我 构建 strip blank link ali 免费 spl 推出 原文地址:https://www.cnblogs.com/dcpeng/p/12784322.html
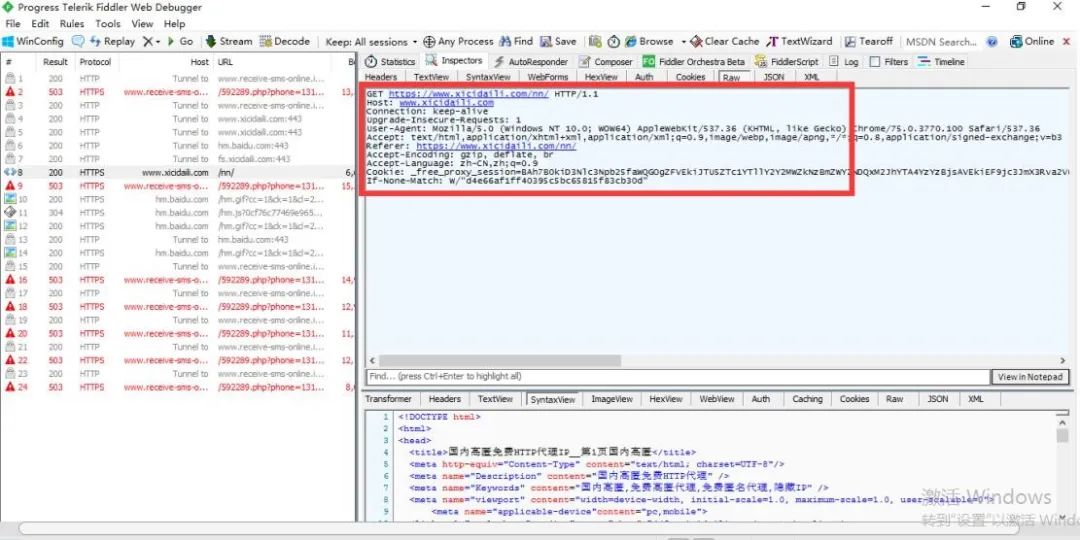
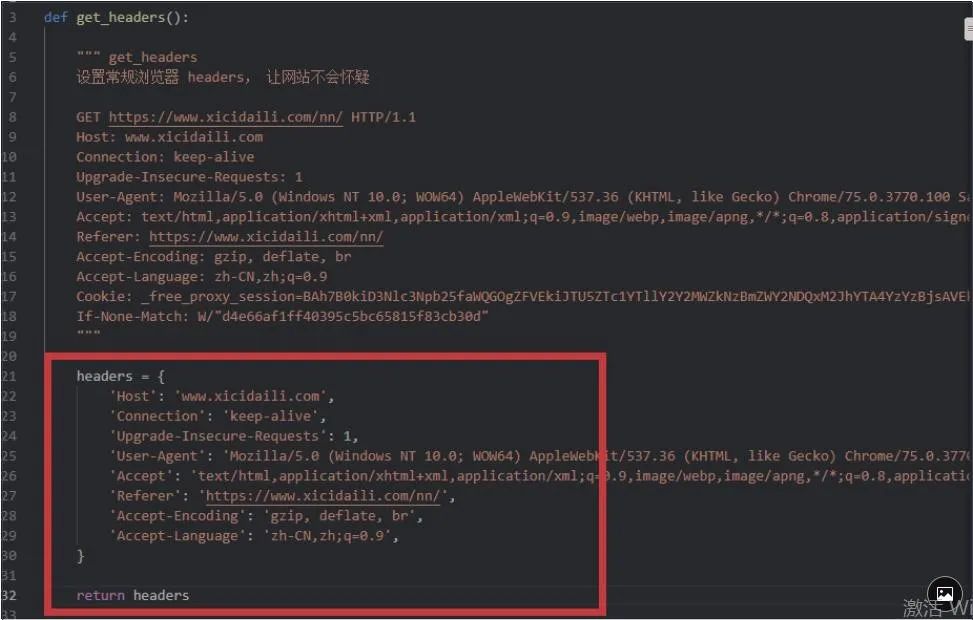
http 请求头(header),并在 requests 请求时设置这些常规的 http 请求头,这样的目的是让目标网站认为我们发出的请求是正常通过浏览器发起而非使用程序自动发起的。这样就可以解决第一个痛点。http 请求头,使用抓包工具 Fiddler 对正常浏览器访问该网站的数据包进行抓取,如图:requests 请求网站的时候, 设置这个头部即可, 代码如下:
上一篇:37 守护线程是什么?
下一篇:python MD5加密
文章标题:手把手教你使用Python爬取西刺代理数据(上篇)
文章链接:http://soscw.com/index.php/essay/51674.html