爬虫之selenium和webdriver—基础(一)
2021-02-07 12:17
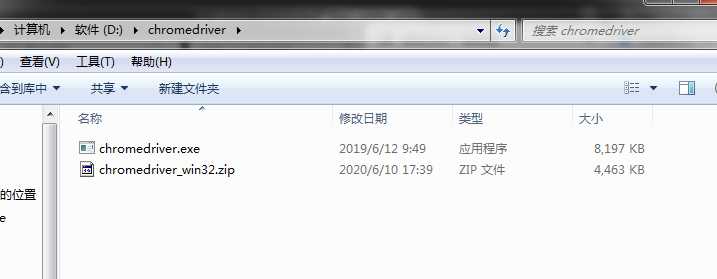
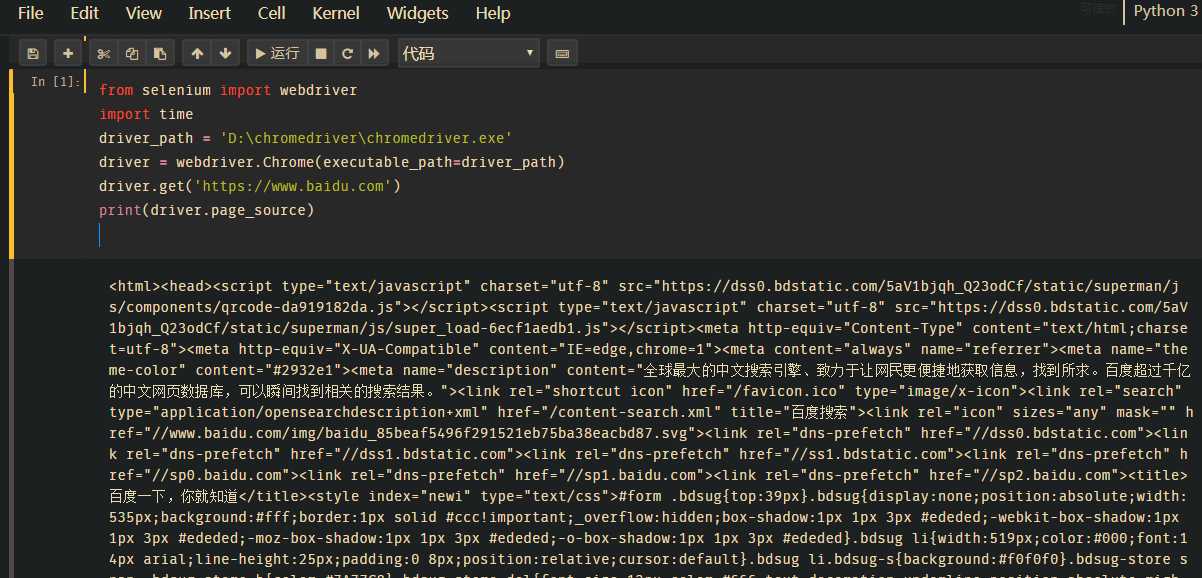
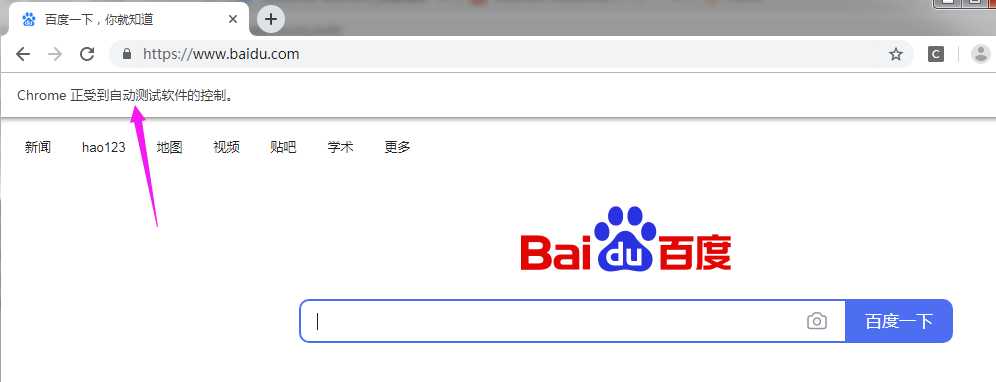
标签:ror 32位 target get 没有 操作 自己 mic too 在爬取一些网页的时候,会发现网页的有些内容是通过JS动态加载的,也就是说是ajax数据,如下图。整个如果需要查看更多的文章,就需要【阅读更多】按钮,这时页面就会加载更多的文章,但是此时网页的网址是不会改变的,没有类似page这种表示页数的参数。这种加载方式就是ajax数据。这种数据通过普通的爬虫是获取不了的,因为查看网页源代码,你会发现,通过【阅读更多】按钮加载出来的文章并没有出现在网页源代码中。这时候据需要用到一个第三方库selenium和一个工具webdriver。 selenium库可以模拟鼠标和键盘在网页上面的操作,比如输入内容,鼠标点击等操作。 首先安装selenium库:pip install selenium. 如果安装速度特别慢可以加一个国内的镜像源:pip install selenium -i https://mirrors.aliyun.com/pypi/simple/ –trusted-host mirrors.aliyun.com 下载对应自己电脑上浏览器的webdriver,将压缩包解压,放在不需要权限的纯英文目录下就可以了。常见的webdriver如下: chrom浏览器:http://npm.taobao.org/mirrors/chromedriver/ firefox(火狐浏览器):https://github.com/mozilla/geckodriver/releases Edge:https://developer.microsoft.com/en-us/micrsosft-edage/tools/webdriver Safari:https://webkit.org/blog/6900/webdriver-support-in-safari-10/ 以chrome为例(这里虽然显示是32位的,但是64位也可以使用),解压出来就OK,不需要去运行exe文件。 安装好以后,测试一下安装成功没有.代码运行后,会自动打开一个Chrome页面,并且自动访问百度页面。 driver.close()是关闭一个页面。 driver.quit()是关闭整个浏览器。 爬虫之selenium和webdriver—基础(一) 标签:ror 32位 target get 没有 操作 自己 mic too 原文地址:https://www.cnblogs.com/GouQ/p/13092470.html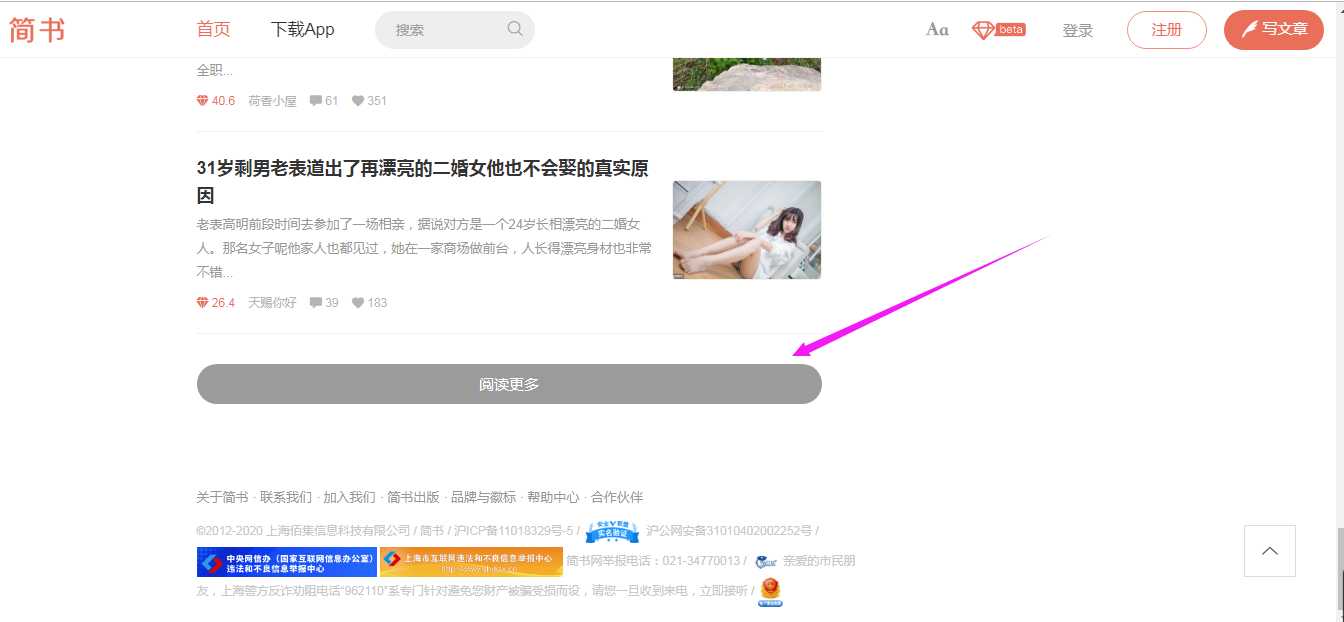
一、安装selenium和webdriver
二、selenium关闭页面和浏览器
1 from selenium import webdriver
2 import time
3 driver_path = ‘D:\chromedriver\chromedriver.exe‘
4 driver = webdriver.Chrome(executable_path=driver_path)
5 driver.get(‘https://www.baidu.com‘)
6 time.sleep(5)
7 driver.close()
8 time.sleep(5)
9 driver.quit()
文章标题:爬虫之selenium和webdriver—基础(一)
文章链接:http://soscw.com/index.php/essay/52175.html