python爬取优美图库海量图片,附加代码,一键爬取
2021-02-08 00:19
标签:编码 web 文件名 xpath 准备 extra 附加 pychar ase 优美高清图片为大家提供高清美女套图赏析,非高清不录入,大家的网速要给力。 今天教大家爬取优美图库网站中高质量的图片!! 简单易上手哦~ Python 3.6 pycharm requests parsel xpath 1、系统分析目标网页 2、html标签数据解析方法(xpath) 3、海量图片数据一键保存 1、确定爬取的url路径,headers参数 2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据 3、析数据 -- parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理 4、保存数据 如果你处于想学Python或者正在学习Python,Python的教程不少了吧,但是是最新的吗?说不定你学了可能是两年前人家就学过的内容,在这小编分享一波2020最新的Python教程。获取方式,私信小编 “ 资料 ”,即可免费获取哦! python爬取优美图库海量图片,附加代码,一键爬取 标签:编码 web 文件名 xpath 准备 extra 附加 pychar ase 原文地址:https://www.cnblogs.com/python0921/p/12772859.html
使用工具:
相关环境:
主要内容:
爬虫的一般思路:
代码如下:
import requests
import parsel
# 1、确定爬取的url路径,headers参数
base_url = ‘https://www.umei.cc/meinvtupian/meinvxiezhen/‘
headers = {‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36‘}
# 2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
response = requests.get(base_url, headers=headers)
response.encoding = response.apparent_encoding # 自动识别响应对象的编码
html = response.text
# print(html)
# 3、解析数据 -- parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理
# 3、1 转换数据类型
parse = parsel.Selector(html)
# 3、2 解析数据
href_list = parse.xpath(‘//div[@class="TypeList"]/ul/li/a/@href‘).extract()
# print(href_list)
for href in href_list:
# print(href)
# 再次发送图片请求
href_data = requests.get(href, headers=headers).text
# 解析图片数据
img = parsel.Selector(href_data)
img_src = img.xpath(‘//div[@class="ImageBody"]/p/a/img/@src‘).extract_first()
# print(img_src)
# 发送图片的url
img_data = requests.get(img_src, headers=headers).content
# 4、保存数据
# 1、准备文件名
file_name = img_src.split(‘/‘)[-1]
# print(file_name)
# 3、保存文件
with open(‘img\\‘ + file_name, ‘wb‘) as f:
print(‘正在保存文件:{}‘.format(file_name))
f.write(img_data)
效果如下:
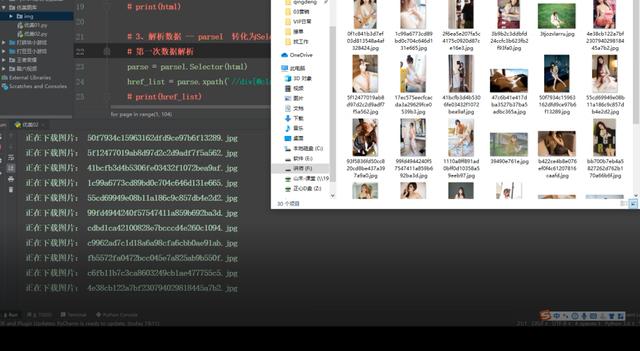
文章标题:python爬取优美图库海量图片,附加代码,一键爬取
文章链接:http://soscw.com/index.php/essay/52405.html