The Anatomy of a Large-Scale Hypertextual Web Search Engine
2021-02-08 19:15
标签:文件 运行 很多 获得 make url 发送 压缩 help The Google search engine has two important features that help it produce high precision results. First, it makes use of the link structure of the Web to calculate a quality ranking for each web page. This ranking is called PageRank and is described in detail in [Page 98]. Second, Google utilizes link to improve search results. Google搜索引擎具有两项重要功能,可帮助它产生高精度结果。 首先,它利用Web的链接结构来计算每个网页的质量等级。 该排名称为PageRank,在[页98]中有详细描述。 其次,Google利用链接来改善搜索结果。 图1.谷歌整体架构 在Google中,网络爬行(网页的下载)是由很多分布的爬行器(crawlers)来做的。由一个URL服务器(URLserver)来向爬行器发送URL列表。被抓取下来的网页就被送到存储服务器(store The Anatomy of a Large-Scale Hypertextual Web Search Engine 标签:文件 运行 很多 获得 make url 发送 压缩 help 原文地址:https://www.cnblogs.com/shilipojianshen/p/13066368.html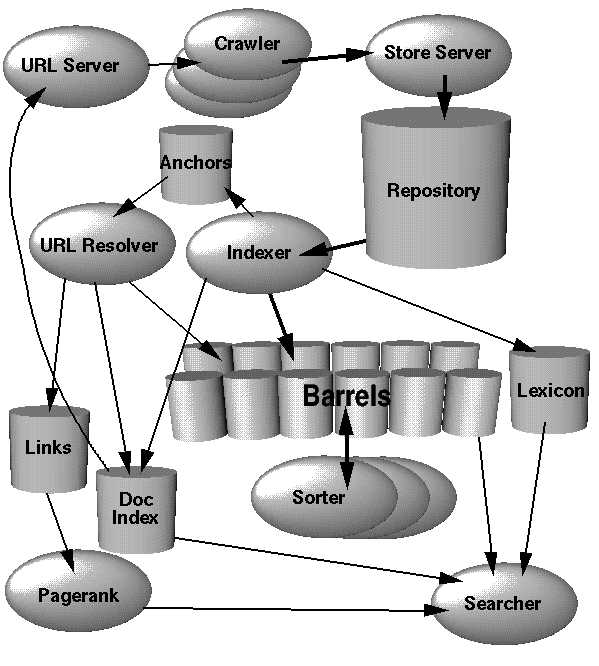
server)上。存储服务器再把网页压缩并存储在仓库(repository)里。每一篇网页都有唯一一个与之相关联的ID号,称作docID,每当有一个新的URL被分析出来的时候都会被赋予一个docID。索引函数由索引器(indexer)和整理器(sorter)在执行。索引器会执行若干个函数。它会读取仓库、解压文档并分析它们。每一篇文档都被转化为词汇出现情况的集合,被称为hits。hits记录了词汇、在文档中的位置、对字号的估计和大小写。索引器将这些hits分发到一些“桶”(barrels)的集合中,创建部分整理好的前向索引。索引器还要执行另一个重要的函数。它要分析出每一篇网页中的链接然后将关于它们的重要信息存储在一个链接(anchors)文本文件中。这个文件包含了足够的信息,可以判断每个链接分别是从哪里到哪里,还有链接上的文本。
URL分解器(URLresolver )读取链接文件(anchors),并将其中相对URL转化为绝对URL,然后转化成docID。它将链接文本放入前向索引中,将链接所指向的docID与之关联起来。它还要生成一个docID键值对的链接数据库(links)。链接数据库是用来给所有文档计算PageRank的。
整理器(sorter)获得以docID整理过的桶(barrels),再根据docID进行整理,生成倒排索引。为了使这个操作几乎不需要临时空间,这一步要在一个特定的地方执行。整理器在倒排索引中产生wordID和偏移量的列表。一个叫DumpingLexicon的程序将这个列表和由索引器生成的词典(lexicon)比较构造出搜索器所用的新词典。搜索器由网络服务器运行,利用由DumpingLexicon构造的词典和倒排索引还有PageRank来回应查询。
上一篇:homestead的laravel项目错误:Use of undefined constant JSON_INVALID_UTF8_SUBSTITUTE - assumed ‘JSON_INVAL
文章标题:The Anatomy of a Large-Scale Hypertextual Web Search Engine
文章链接:http://soscw.com/index.php/essay/52764.html