并发编程之java内存模型
2021-02-09 22:16
标签:stack 线程池 code 放大 工作方式 环境 java方法 静态 反射 JVM虚拟机在类被调用的时候启动 先启动JVM线程---> 其他线程(main线程) 主要存放classloader加载的类信息、常量、静态变量、JIT即时编译的代码 实现信息共享 Class.forName 反射的操作区域 OOM内存溢出可能 存放大量的实例对象 A a = new A(); new A() 存放在堆区 实现信息共享 GC 工作区域 OOM内存溢出可能 采用数据结构栈 java方法在运行时的内存模型 私有数据,只能该方法访问,无法进行数据共享 虚拟机栈存放满了 会导致内存溢出(递归调用就是方法不停进栈,没有出栈) OOM内存溢出可能 存放java线程的私有数据,这个数据就是执行下一条指令的地址 主要与native方法有关,本地方法 JMM是一种规范,是一个抽象的概念。 存放的为共享的信息 也是快内存区域,存放线程的私有信息 工作空间对应着JVM虚拟机模型中的虚拟机栈与程序计数器 Cpu先到寄存器中找数据,没有再去高速缓存中找数据,没有最后在内存中找数据。 并发处理的数据不同步 解决方案 1、总线加锁(BUS) :把总线只提供一个CPU使用,其他CPU无法访问,降低CPU的吞吐量。 2、 缓存一致性协议: (MESI协议) 单CPU情况下,采用的是时间分片算法。 多CPU情况如图上述,任务经过线程池,分配给线程处理,线程受OS内核的调度,进行执行,最终映射至硬件进行处理。 交叉线为数据可能存在的位置 交叉会存在数据不一致 java内存模型的作用:规范内存数据和工作空间数据的交互 不可分隔,转账:要么同时成功,要么同时失败。 线程只能操作自己工作空间中的数据,自己的工作空间数据不对其他线程可见。 程序中的代码执行顺序,不一定就是程序执行的顺序。 如果对结果的运行没有影响,cpu会发生重排序 x=10 写操作 原子性 y=x 无原子性 i++ 无原子性 z=z+1 没有原子性 多个原子性操作,合并起来就不具备原子性 保证原子性的方式 在jmm内存模型上实现MESI协议 volatile对修饰的代码不允许重排序 加锁 保证只能一个线程访问 lock也是一种锁 as-if-serial 语义的意思是:所有的操作均可以为了优化而被重排序,但是你必须要保证重排序后执行的结果不能被改变,编译器、runtime、处理器都必须遵守 as-if-serial 语义。注意,as-if-serial 只保证单线程环境,多线程环境下无效。 在单线程中,重排后不影响执行的结果. 多线程下程序在运行中发生了重排,不影响结果 后一次加锁,必须等前一个解锁 volatile 修饰的代码不能进行重排序 传递原则 a在b之前,b在c之前 可以的到a在c之前执行。 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。 两个操作之间存在happens-before关系,并不意味着一定要按照happens-before原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行的结果一致,那么这种重排序并不非法。 并发编程之java内存模型 标签:stack 线程池 code 放大 工作方式 环境 java方法 静态 反射 原文地址:https://www.cnblogs.com/wilsonsui/p/12747353.html1、基本概念
2、JVM与线程
3、JVM内存区域
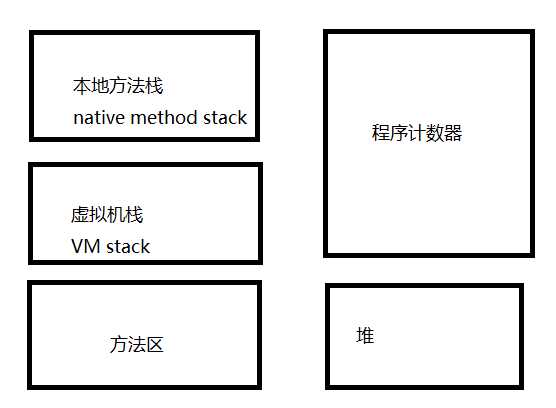
方法区
java堆
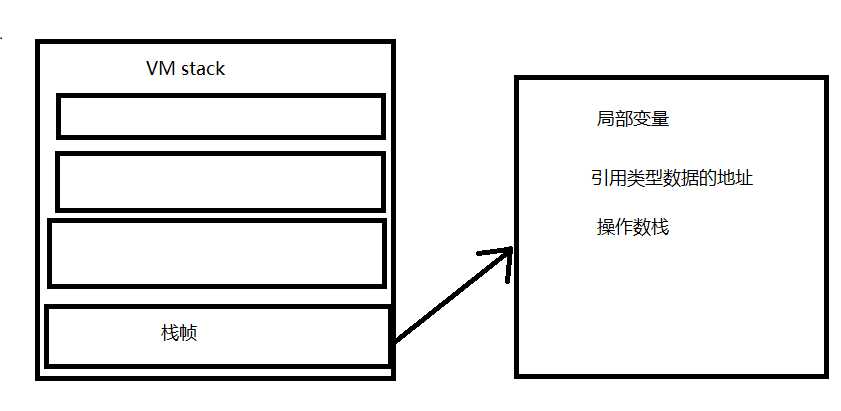
VM stack 虚拟机栈
程序计数器
本地方法栈
4、Java内存模型-JMM
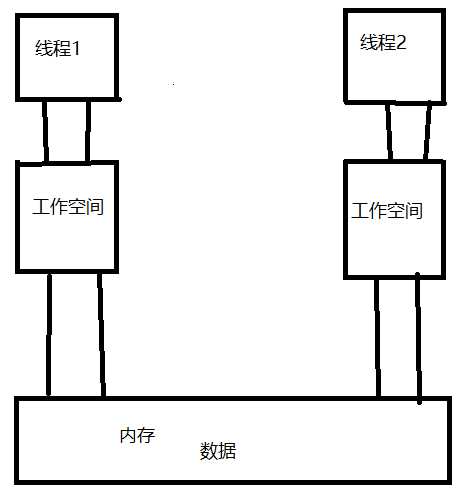
主内存
工作内存(线程的自己的内存)
工作方式
5、硬件内存架构与java内存模型
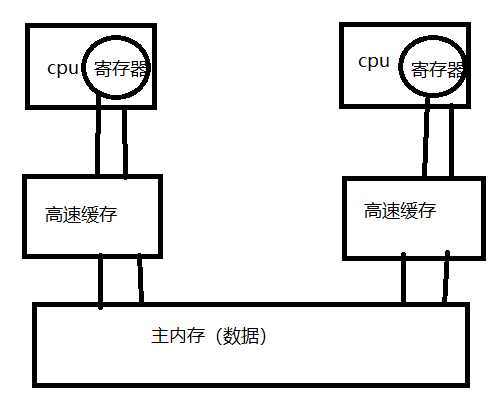
CPU缓存存在数据不一致性问题
当cpu在缓存中操作数据时,如果该数据是共享变量,数据在缓存中读到寄存器中,进行修改并更新内存数据,并且把cache line缓存行置为无效,其他cpu发现cache line无效,则直接从内存中读数据java线程与硬件处理器
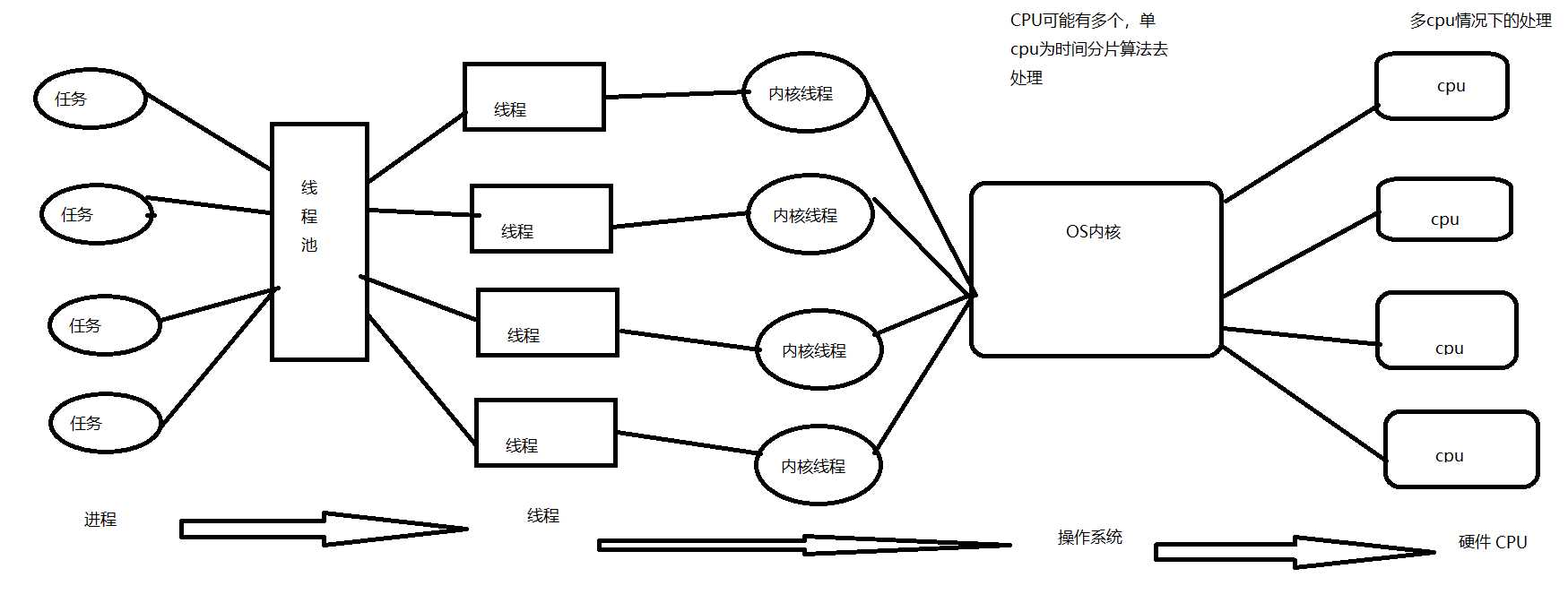
java内存模型与硬件内存架构的关系
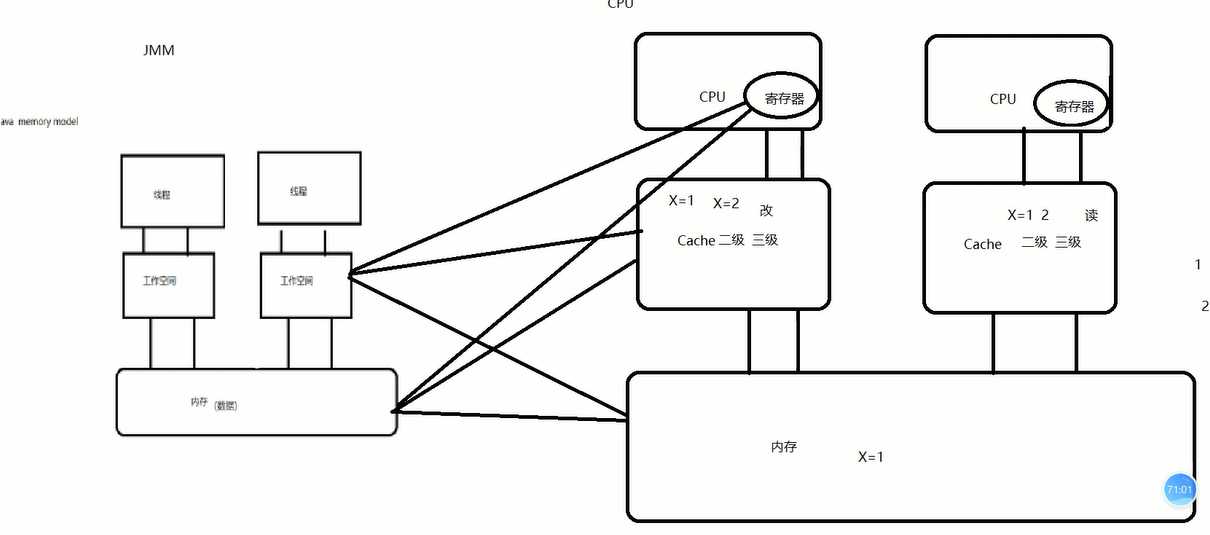
java内存模型的必要性
6、并发编程的三个重要特性
原子性
x=1 就是原子性,x++不具备原子性可见性
有序性
两种重排序
- 编译重排
- 指令重排
提高程序效率。7、JMM对三个特征的保证
jmm与原子性
jmm与可见性
jmm与有序性
as-if-serial原则
happens-before 原则
总结