数据挖掘关联分析中Apriori算法理解(非算法应用)-ylance
2021-02-10 07:17
标签:集合 mamicode 无法 das ack 可见 次数 width font 1.项集和支持度计数 ① 在关联分析中,包含0或多个项的集合叫做项集,有几个项就是几-项集,如有一个项,就是1-项集。空集是不包含任何项的项集 例:{啤酒,尿布,牛奶} 这是一个3-项集 ② 支持度计数(σ):项集在事务中出现的次数 例:(由表可见,事务数为5) σ{面包}:4 σ{啤酒,尿布}:3 2.关联规则(支持度,置信度) 关联规则是形如X?Y的蕴含表达式,其中X和Y是不相交的项集。关联规则的强度可以用它的支持度(s)和置信度(c)度量 s(X?Y) = σ {X,Y} / 总的事务数 c(X?Y) = σ {X,Y} / σ{X} 例:(图1.1)中 s(啤酒?尿布) = 3/5 c(啤酒?尿布) = 3/3 1.规则产生的两大步骤 继续把所有频繁项集的规则列出,得出全部的满足置信度阈值的全部规则即可解题成功。 数据挖掘关联分析中Apriori算法理解(非算法应用)-ylance 标签:集合 mamicode 无法 das ack 可见 次数 width font 原文地址:https://www.cnblogs.com/ylance/p/12743634.html一.入门概念
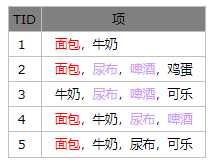 (图1.1)
(图1.1)
二.Apriori-频繁项集的产生
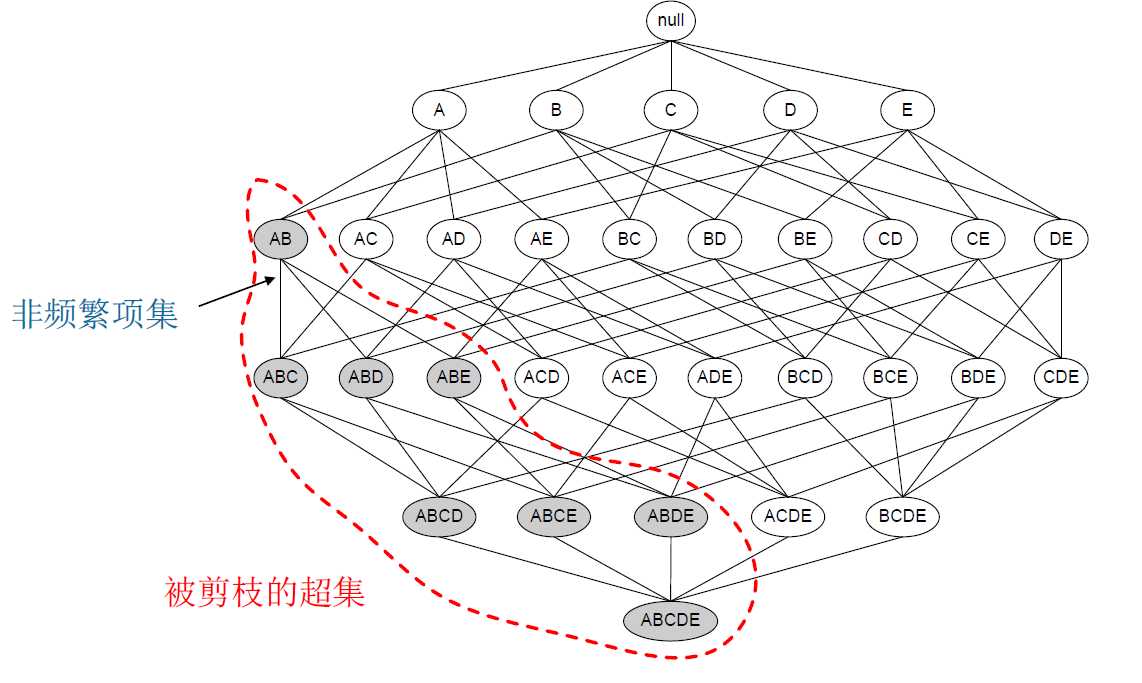
一个项集的支持度绝对不会超过它的子集的支持度。这个性质也称为支持度度量的反单调性。
相反,如果一个项集是频繁的,那么它的所有子集也是频繁的。
那么,我们便可以有了思路,倘若子集不频繁,那么它肯定也不频繁,所以便可以有如下的剪枝处理 可以大大节省计算量!
2.实例学习
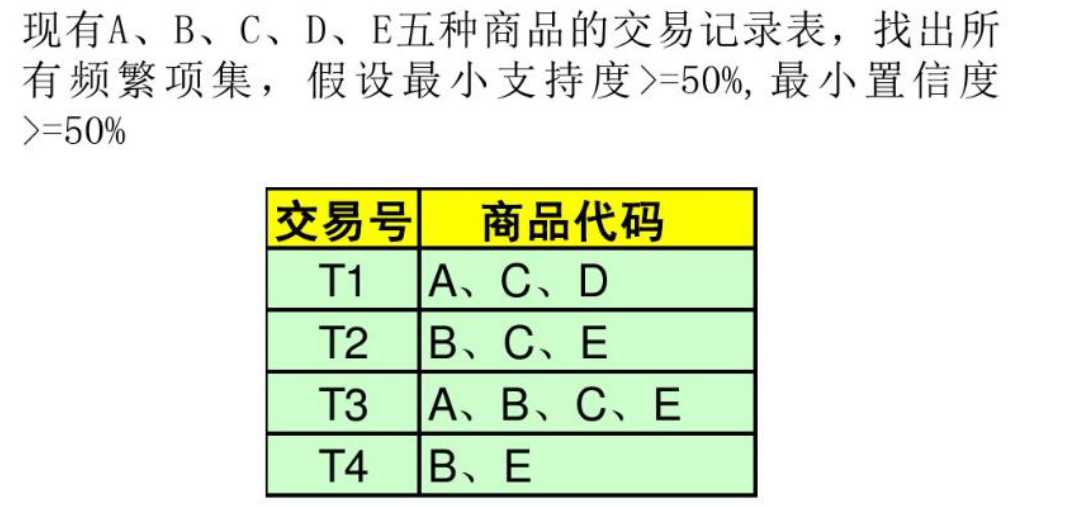
①:产生频繁项集
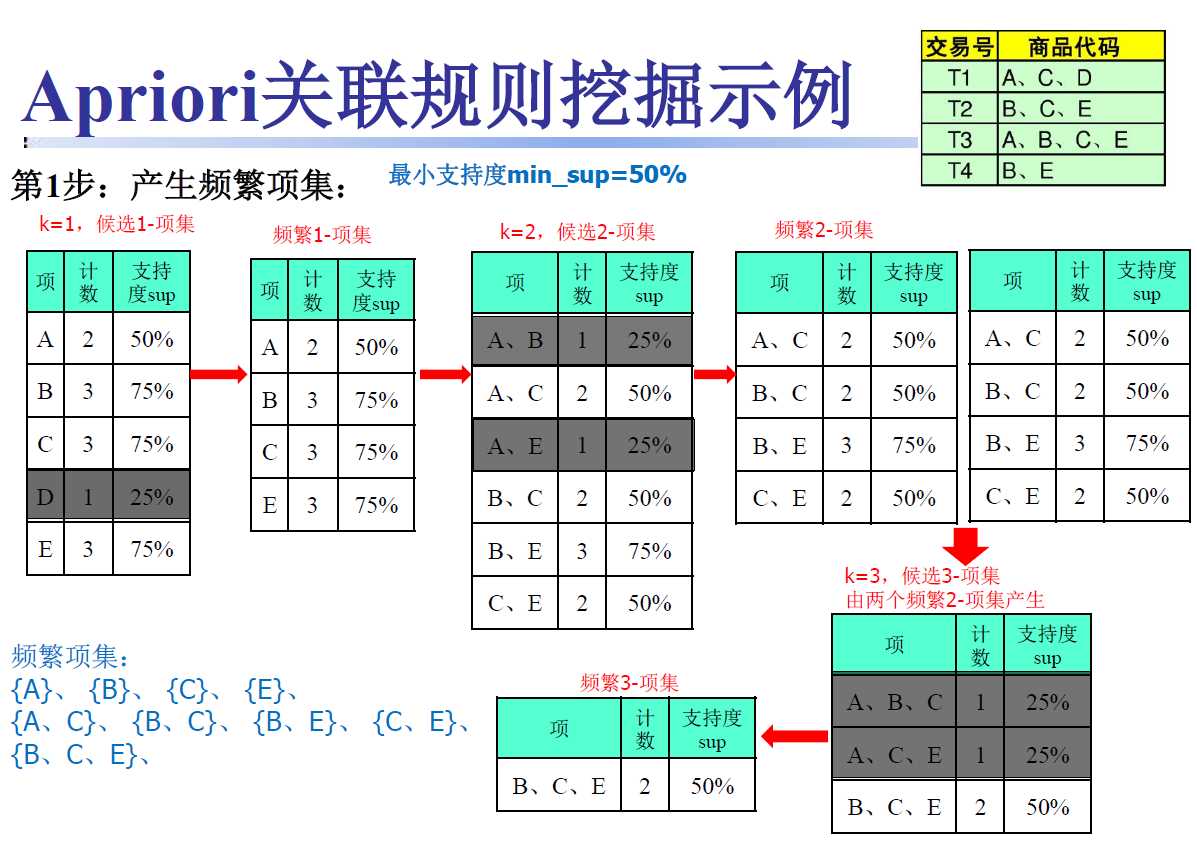 (图1.2)
(图1.2)
解题:a. 列出1-项集,发现D不满足支持度要求,那么包含D的项集则全不满足,继续生成2-项集
b. 列出和D无关的2-项集,发现{A,B}{A,E}项集不满足支持度要求,同理,包含他们的项集同样不满足
c. 生成大于2的项集时,我们用合并一对频繁(N-1)-项集的方法生成N项集(原因是这样做复杂度最小)合并后发现无法合并成四项集,列出所有满足条件的频繁项集即可
ps :下面我们介绍一下c中的这种方法——apriori-gen函数
a. 当生成N项集时:我们可以用两个(N-1)项集进行合并,合并的要求是,要合并的两项集的前N-2个项相同
b. 生成三项集时 : 两个二项集前一个项相同,后一个项不同,则可以进行合并,
如:{面包,牛奶}和{面包,尿布}可以合并成{面包,尿布,牛奶}
但是,{啤酒,尿布}和{尿布,牛奶}则无法合并,因为他们的前一个项不同
三.Apriori-规则的产生
① 频繁项集的产生–生成其支持度≥minsup的所有项集
②规则的产生–从每个频繁项集生成高置信度规则(忽略前件或后件为空的规则)
2.实例学习(接图1.2中的结果)
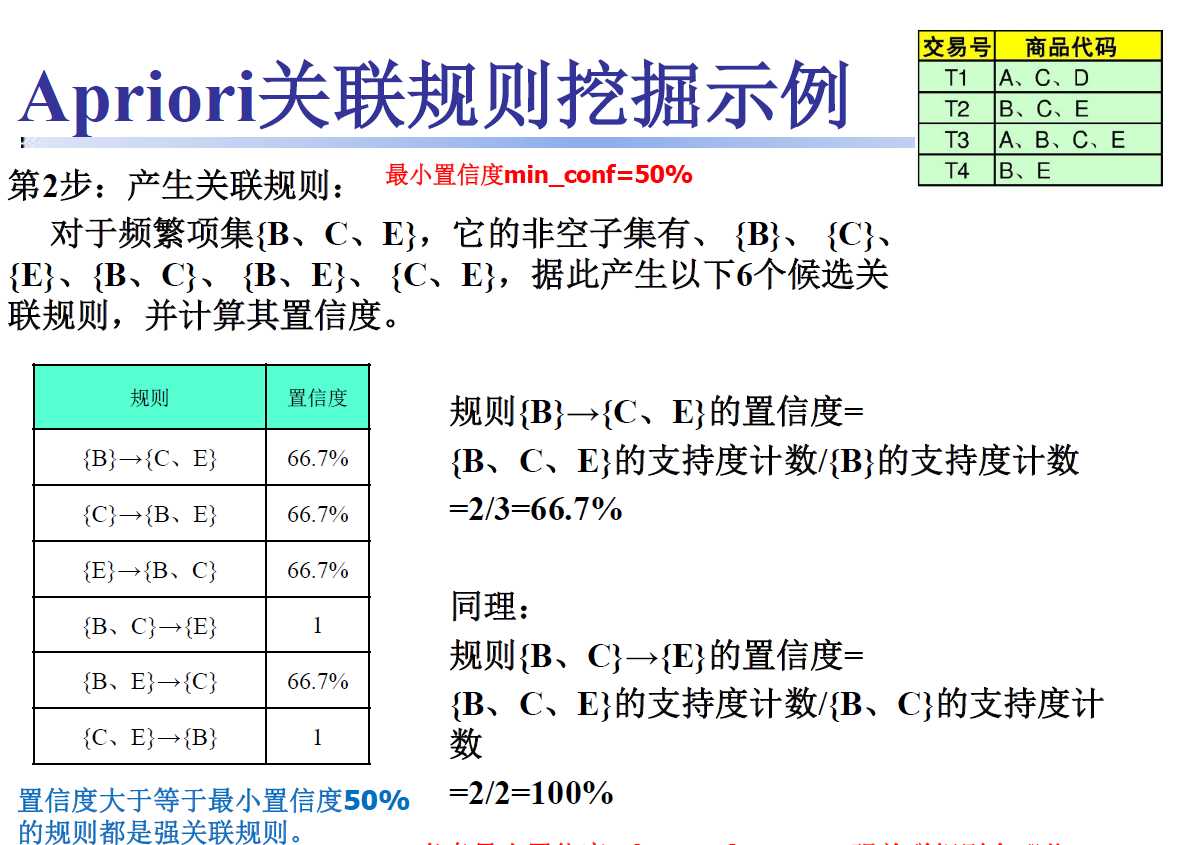
解题:规则的产生就是从每个频繁项集生成高置信度规则,图中详解了{B,C,E}项集产生的规则,
文章标题:数据挖掘关联分析中Apriori算法理解(非算法应用)-ylance
文章链接:http://soscw.com/index.php/essay/53461.html