python学习之Scrapy爬虫框架
2021-02-10 13:17
标签:模块 成功 san spi request 函数 mamicode 指定 efi ? Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用 优势: Scrapy主要包括了以下组件: ? 新建项目(scrapy startproject xxx): 创建一个 Scrapy 项目,项目文件可以直接用 scrapy 命令生成,命令如下所示 : D scrapy.cfg : 它是 Scrapy 项目的配置文件,其内定义了项目的配置文件路径 、 部署相关信息 Item 是保存爬取数据的容器,它的使用方法和字典类似 。 不过,相比字典, Item 多了额外的保护 Item Pipeline 是项目管道 现在,改写之后的book.py 接下来,进入日录,运行如下 https://gitee.com/huojin181/ScrapyProject.git python学习之Scrapy爬虫框架 标签:模块 成功 san spi request 函数 mamicode 指定 efi 原文地址:https://blog.51cto.com/13810716/2488883
于抓取web站点并从页面中提取结构化的数据。
? Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。
它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版
本又提供了web2.0爬虫的支持。
? Scrap,是碎片的意思,这个Python的爬虫框架叫ScrapyScrapy架构流程
– 用户只需要定制开发几个模块, 就可以轻松实现爬虫, 用来抓取
网页内容和图片, 非常方便;
– Scrapy使用了Twisted异步网络框架来处理网络通讯, 加快网页
下载速度, 不需要自己实现异步框架和多线程等, 并且包含了各
种中间件接口, 灵活完成各种需求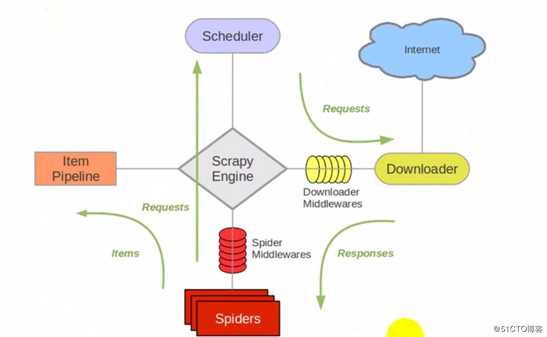
架构图(绿线是数据流向)
? 引擎(Scrapy):
用来处理整个系统的数据流, 触发事务(框架核心)
? 调度器(Scheduler):
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返
回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的
网址是什么, 同时去除重复的网址
? 下载器(Downloader):
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立
在twisted这个高效的异步模型上的)
? 爬虫(Spiders):
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体
(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
? 项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实
体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的
次序处理数据
? 下载器中间件(Downloader Middlewares):
位于Scrapy引擎和下载器之间的框架,
主要是处理Scrapy引擎与下载器之间的请求及响应。
? 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处
理蜘蛛的响应输入和请求输出
? 调度中间件(Scheduler Middewares):
介于Scrapy引擎和调度之间的中间件,从
Scrapy引擎发送到调度的请求和响应。

只有当调度器中不存在任何request时, 整个程序才会停止。(注:对于下载失败的URL,
Scrapy也会重新下载. )Scrapy爬虫步骤
– 新建一个新的爬虫项目;
? 明确目标(编写item.py)
– 明确你要抓取的目标;
? 制作爬虫(spiders/xxspider.py)
– 制作爬虫, 开始爬取网页;
? 存储爬虫(pipelines.py)
– 设置管道存储爬取内容;创建项目
scrapy startproject ScriptProject
进入刚才创建的 ScriptProject文件夹, spiders 文件夹创建了一个 book.py ,它就是刚刚创建的 Spider,
内容如下所示:
import scrapy
class QuotesSpider(scrapy.Spider):
name =” book”
allowed_domains = [“http://uotes.toscrape.com ‘’]
start_urls = [‘http://quotes.toscrape .com/‘]
def parse(self, response):
pass
这里有三个属性一-name 、 allowed_domaiin和 start_urls ,还有一个方法 parse
等内容 。
口 items . py : 它定义 Item 数据结构,所有的 Item 的定义都可以放这里 。
pipelines.py : 它定义 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放这里 。
口 settings.py : 它定义项目的全局配置。
口 middlewares.py : 它定义 Spider Middlewares 和 Downloader Middlewares 的实现。
口 spide : 其内包含一个个 Spider 的实现,每个 Spider 都有一个文件 。创建 Item
机制,可以避免拼写错误或者定义字段错误 。
创建 Item 需要继承 scrapy.Item 类,并且定义类型为 scra py.Field 的字段 。 观察目标网站,我们
叮以获取到到内容有 text 、 author 、 tags 。
定义 Item ,此时将 items.py 修改如下:import scrapy
class BookItem(scrapy.Item):
name = scrapy.Field(output_processor=TakeFirst())
content = scrapy.Field(output_processor=TakeFirst())
bookname = scrapy.Field(output_processor=TakeFirst())tem Pipeline 的用法
首先我们看看 Item Pipeline 在 Scrapy 中的架构 ,它的调用发生在 Spider 产生 Item 之后 。 当 Spider 解析完 Response
之后, Item 就会传递到 Item Pipeline ,被定义的 Item Pipeline 组件会)I顶次调用,完成一连串的处理过
程,比如数据清洗、存储等 。
Item Pipeline 的 主要功能有如下 4 点 。
口 清理 HTML 数据 。
口 验证爬取数据, 检查爬取字段 。
口 查重并丢弃重复 内 容 。
口将爬取结果保存到数据库 。class ScrapyprojectPipeline(object):
def process_item(self, item, spider):
"""将章节内容写入对应的章节文件"""
#books/hongloumeng
dirname = os.path.join(‘books‘, item[‘bookname‘])
if not os.path.exists(dirname):
os.makedirs(dirname) # 递归创建目录
name = item[‘name‘]
#文件名相对路径用join方法拼接: Linux路径拼接符是/, Windows路径拼接符是 filename = os.path.join(dirname, name)
#写入文件时以‘w’的方式打开, 并指定编码格式为utf-8来写入中文.
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(item[‘content‘])
#print("写入文件%s成功" %(name))
return itemimport scrapy
from scrapy import Request
from scrapy.loader import ItemLoader
from ScrapyProject.items import BookItem
Scrapy爬虫流程:
1.确定start_urls起始URL
2.引擎起始的URL交给调度器(存储到队列,去重)
3.调度器简爱嗯URL发给Downloader,Downloader发起Request从互联网下载网页信息
4. 将下载的页面交给Spider,进行解析(parse函数),
5.
"""
class BookSpider(scrapy.Spider):
name = ‘book‘
base_url = ‘http://www.shicimingju.com‘
#allowed_domains = [‘shicimingju.com‘]
start_urls = [
‘http://shicimingju.com/book/sanguoyanyi.html‘
#‘http://shicimingju.com/book/sanguoyanyi.html‘
#‘http://shicimingju.com/book/xiyouji.html‘
#‘http://shicimingju.com/book/hongloumeng.html‘
]
def parse(self, response):
chapters = response.xpath(‘//div[@class="book-mulu"]/ul/li‘)
for chapter in chapters:
l = ItemLoader(item=BookItem(), selector=chapter)
detail_url = chapter.xpath(‘./a/@href‘).extract_first()
l.add_xpath(‘name‘,‘./a/text()‘)
l.add_value(‘bookname‘,response.url.split(‘/‘)[-1].strip(‘.html‘))
yield Request(url=self.base_url + detail_url,
callback=self.parse_chapter_detail,
# meta={‘name‘: name, ‘bookname‘: bookname}
meta={‘item‘: l.load_item()}
)
def parse_chapter_detail(self, response):
# 1). .xpath(‘string(.)‘)获取该标签及子孙标签所有的文本信息;
#2). 如何将对象转成字符串?
#- extract_first()/get()-转换一个对象为字符串
#- extract()/get_all()-转换列表中的每一个对象为字符串
item = response.meta[‘item‘]
content = response.xpath(‘.//div[@class="chapter_content"]‘)[0].xpath(‘string(.)‘).get()
item[‘content‘] = content
yield item运行
scrapy crawl book完整项目代码
下一篇:Java8_函数式接口
文章标题:python学习之Scrapy爬虫框架
文章链接:http://soscw.com/index.php/essay/53578.html