入门自然语言处理(NLP)的门
2021-02-10 22:17
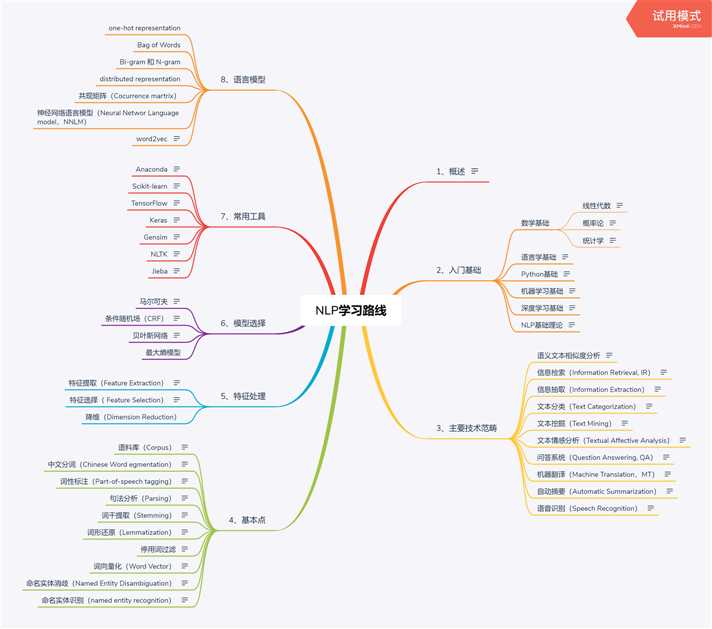
标签:word distrib 编码 机器学习实战 序列 参数 连续 合成 基础 自然语言处理(Natural Language Processing,NLP)是计算机科学领域与人工智能领域中的一个重要方向。简单点说就是怎样让计算机能够理解人类的语言,以执行如机器翻译、文本分析、情感分析等任务。 自然语言处理是人工智能领域比较火热的方向,本人决定入坑是因为听那个谁说,这个方向对数学要求不像计算机视觉那么高巴拉巴拉......其实吧,入门基础要求的数学知识,线代、概率、统计一个没落下。 还有机器学习的基础知识(经典的书:李航统计学习方法、周志华机器学习西瓜书、机器学习实战),以及深度学习要了解CNN、RNN、LSTM ...... 当然,这些相当于入坑人工智能所有领域的普适入门级知识,还没切到自然语言处理上面呢,多学点吧趁还有头发的时候,知识到用时总是很方的。 那NLP究竟是个什么玩法呢? 首先需要一个语料库:语料库中存放的是在语言的实际使用中真实出现过的语言材料;语料库是以电子计算机为载体承载语言知识的基础资源;真实语料需要经过加工(分析和处理),才能成为有用的资源。 然后进行分词: (1)中文分词指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。 (2)现有的分词方法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。 (3)比较流行的中文分词工具:jieba、StanfordNLP、HanLP、SnowNLP、THULAC、NLPIR 词性标注: (1)词性标注是指为给定句子中的每个词赋予正确的词法标记,给定一个切好词的句子,词性标注的目的是为每一个词赋予一个类别,这个类别称为词性标记(part-of-speech tag),比如,名词(noun)、动词(verb)、形容词(adjective)等。 (2)词性标注是一个非常典型的序列标注问题。最初采用的方法是隐马尔科夫生成式模型, 然后是判别式的最大熵模型、支持向量机模型,目前学术界通常采用的结构是感知器模型和条件随机场模型。近年来,随着深度学习技术的发展,研究者们也提出了很多有效的基于深层神经网络的词性标注方法。 句法分析:基于规则或基于统计的方法。 词干提取:将词语去除变化或衍生形式,转换为词干或原型形式的过程。词干提取的目标是将相关词语还原为同样的词干。 停用词过滤:指在文本中频繁出现且对文本信息的内容或分类类别贡献不大甚至无贡献的词语,如常见的介词、冠词、助词、情态动词、代词以及连词等。 词向量化:词向量化是用一组实数构成的向量代表自然语言的叫法。这种技术非常实用,因为电脑无法处理自然语言。词向量化可以捕捉到自然语言和实数间的本质关系。通过词向量化,一个词语或者一段短语可以用一个定维的向量表示。 命名实体识别:识别一个句子中有特定意义的实体并将其区分为人名,机构名,日期,地名,时间等类别的任务。三种主流算法:CRF,字典法和混合方法。 命名实体消歧:一词多义要能根据语境区别同一个词不同的含义。 这几天去知网上查论文,关于中文自然语言处理的近几年论文比较多的就是各种方法的命名实体识别(NER)任务,许多都是用CRF或者LSTM+CRF或者BiLSTM+CRT......方法上没什么惊天动地的突破性创新,主要是各自用的数据不同吧,有自家医院的电子病历,网上爬取的数据,或者公开数据集等等。同样,自从2018年谷歌开源了BERT,大量的研究都是基于BERT的了,我大致get到了这种用已有优秀模型迁移到自己数据上的研究(guanshui)方式了。 对了,刚刚提到那个CRF就是条件随机场,学AI的肯定不用解释,可要我这种入门小白吧,极可能就被这些莫名其妙的的缩写劝退的,放心,后面还会遇到很多的。 (1)条件随机场用于序列标注,中文分词、中文人名识别和歧义消解等自然语言处理中,表现出很好的效果。原理是:对给定的观察序列和标注序列,建立条件概率模型。条件随机场可用于不同预测问题,其学习方法通常是极大似然估计。 (2)条件随机场模型也需要解决三个基本问题:特征的选择、参数训练和解码。 此外还要知道马尔可夫: 马尔可夫模型、隐马尔可夫模型、层次化隐马尔可夫模型、马尔可夫网络 (1)应用:词类标注、语音识别、局部句法剖析、语块分析、命名实体识别、信息抽取等。应用于自然科学、工程技术、生物科技、公用事业、信道编码等多个领域。 (2)马尔可夫链:在随机过程中,每个语言符号的出现概率不相互独立,每个随机试验的当前状态依赖于此前状态,这种链就是马尔可夫链。 (3)多元马尔科夫链:考虑前一个语言符号对后一个语言符号出现概率的影响,这样得出的语言成分的链叫做一重马尔可夫链,也是二元语法。二重马尔可夫链,也是三元语法,三重马尔可夫链,也是四元语法 。 关于语言模型,我就提几个关键词,以这几个关键词去延伸扩展,盲人慢慢就能摸到全象的轮廓了。 好了,这是我第一篇blog,想吐槽一下这个文本编辑器有点难搞,另外,有个xmind画的思维导图,我就截图放上来吧。 入门自然语言处理(NLP)的门 标签:word distrib 编码 机器学习实战 序列 参数 连续 合成 基础 原文地址:https://www.cnblogs.com/mokoaxx/p/12740303.html