14 基于bs4库的HTML内容遍历方法
2021-02-11 02:34
阅读:786
YPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/REC-html40/loose.dtd">
标签:mic http src soup 图片 info font else rpo
https://python123.io/ws/demo.html
The demo python introduces several python courses.
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
Basic Python and Advanced Python.
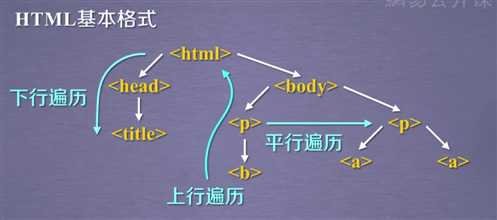
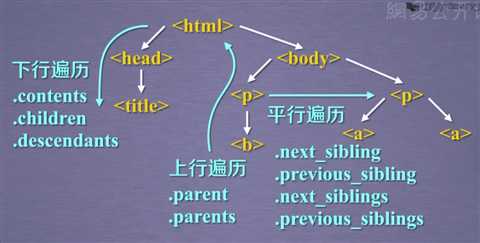
方法一:下行遍历

"""12 基于bs4库的HTML内容遍历方法"""
import requests
from bs4 import BeautifulSoup
#方法一:下行遍历
url = "https://python123.io/ws/demo.html"
r = requests.get(url)
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
#
This is a python demo page
print(soup.head)
# [This is a python demo page ]
print(soup.head.contents)
print(soup.body.contents)
# 5
print(len(soup.body.contents)) # 注意回车也是其元素
print(soup.body.contents[1])
# 使用.contents输出其元素
print(‘*‘*10)
for content in soup.body.contents:
print(content)
print(‘*‘*10)
###############################
print(‘#‘*10)
# 使用.chidlren输出
for child in soup.body.children:
print(child)
print(‘#‘ * 10)
print(‘$‘*10)
# 使用.descendants输出
for descendant in soup.body.descendants:
print(descendant)
print(‘$‘ * 10)
方法二:上行遍历

"""12 基于bs4库的HTML内容遍历方法"""
import requests from bs4 import BeautifulSoup
#方法二:上行遍历 url = "https://python123.io/ws/demo.html" r = requests.get(url) demo = r.text soup = BeautifulSoup(demo, "html.parser") #This is a python demo page print(soup.title.parent) print(soup.head.parent) # 整个html print(‘$‘ * 30) print(soup.html.parent) # 整个html print(‘$‘ * 30) print(soup.parent) # None ############### """ p body html [document] """ for parent in soup.a.parents: if parent is None: print(parent) else: print(parent.name)
方法三:平行遍历

"""12 基于bs4库的HTML内容遍历方法"""
import requests from bs4 import BeautifulSoup
#方法三:平行遍历 url = "https://python123.io/ws/demo.html" r = requests.get(url) demo = r.text soup = BeautifulSoup(demo, "html.parser") # and print(soup.a.next_sibling) print(soup.a.next_sibling.next_sibling) print(soup.a.previous_sibling) # None print(soup.a.previous_sibling.previous_sibling) #对a标签后序结点进行遍历 print(‘#‘*30) for sibling in soup.a.next_siblings: print(sibling) print(‘#‘*30) #对a标签前序结点进行遍历 print(‘@‘*30) for sibling in soup.a.previous_siblings: print(sibling) print(‘@‘*30)
14 基于bs4库的HTML内容遍历方法
标签:mic http src soup 图片 info font else rpo
原文地址:https://www.cnblogs.com/sruzzg/p/13047185.html
上一篇:现代 CSS 进化史
下一篇:安装node.js
文章来自:搜素材网的编程语言模块,转载请注明文章出处。
文章标题:14 基于bs4库的HTML内容遍历方法
文章链接:http://soscw.com/index.php/essay/53840.html
文章标题:14 基于bs4库的HTML内容遍历方法
文章链接:http://soscw.com/index.php/essay/53840.html
评论
亲,登录后才可以留言!