K-近邻算法
2021-02-11 04:18
#导入相关库 由于实际使用模块较多,这里是所有工程需要库,不必全部导入
import numpy as np import pandas as pd from pandas import read_csv from pandas.plotting import scatter_matrix from matplotlib import pyplot as plt from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_score from sklearn.model_selection import StratifiedKFold from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score
#导入封装好的KNN算法
from sklearn.neighbors import KNeighborsClassifierfrom sklearn import metrics from collections import Counter from sklearn.externals import joblib import time
#解决matplotlib中文显示乱码问题
plt.rcParams[‘font.family‘] = [‘sans-serif‘]
plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘]
#导入数据
#数据读取与划分数据集
#random_state参数将随机种子设置为固定数字,以确保每种算法都在训练数据集的相同分割上进行评估。
data = pd.read_csv("E:\\Mywork\\分类器\\file\\Data_1.csv")
print(data.shape)
print(data.head())
array = data.iloc[:,:].values
X = array[:,1:3]
y = array[:,3]
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=0.1, random_state=1)
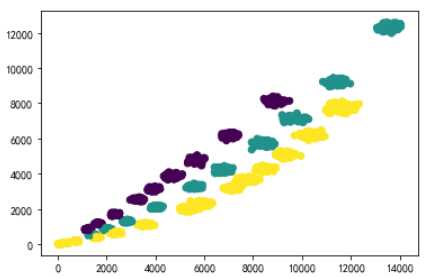
#查看数据分布状况
plt.scatter(X_train[:,0], X_train[:,1],c = Y_train)
plt.show()
#Surpervised KNN
#Knn网络参数详解
‘‘‘
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=’uniform’,
algorithm=’auto’, leaf_size=30, p=2, metric=’minkowski’, metric_params=None,
n_jobs=1, **kwargs)
1.n_neighbors : 一个整数,指定k值。
2.weights:字符串或可调用对象,指定投票权重类型。
uniform:节点附件邻居节点的投票权重都相等。
distance:投票权重与距离成正比。节点越近权重越大。
[callable]:一个可调用对象,它传入距离的数组,返回同样形状的权重数组。
3.algorithm:一个字符串,指定最近邻算法。
ball_tree : 使用BallTree算法。
kd_tree : 使用KDTree算法。
brute : 使用暴力搜索算法。
auto : 自动决定最合适算法
4.leaf_size:一个int,指定BallTree或者KDTree叶节点的规模。影响树的构建和查询速度。
5.metric:一个str,指定距离量度。默认为‘minkowski‘
6.P:int
1.曼哈顿距离。
2.欧式距离。
‘‘‘
#使用Sklearn构建KNN算法
KNN_model = KNeighborsClassifier(n_neighbors = 3,leaf_size = 30,p = 2,)
KNN = KNN_model.fit(X_train,Y_train)
y_pred_KNN = KNN.predict(X_validation)
y_pred_raw = KNN.predict(data_test_1)
#评估预测
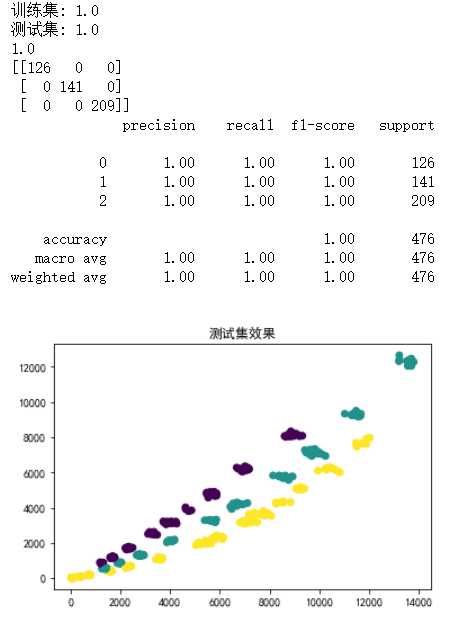
print("训练集:", KNN.score(X_train, Y_train))
print("测试集:", KNN.score(X_validation, Y_validation))
print(accuracy_score(Y_validation,y_pred_KNN))
print(confusion_matrix(Y_validation, y_pred_KNN))
print(classification_report(Y_validation, y_pred_KNN))
plt.title(‘测试集效果‘)
plt.scatter(X_validation[:,0],X_validation[:,1],c = y_pred_KNN)
输出