线程池
2021-02-11 11:17
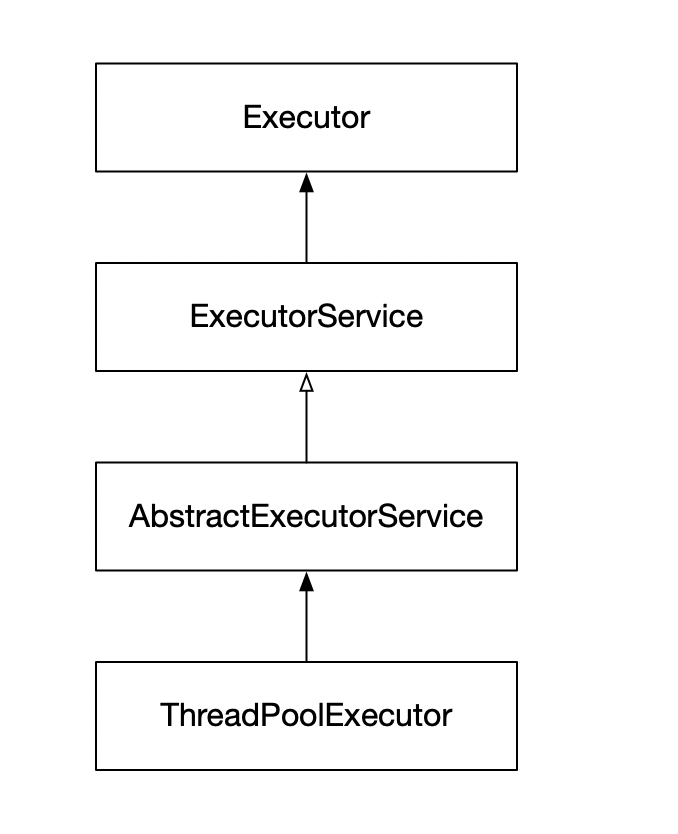
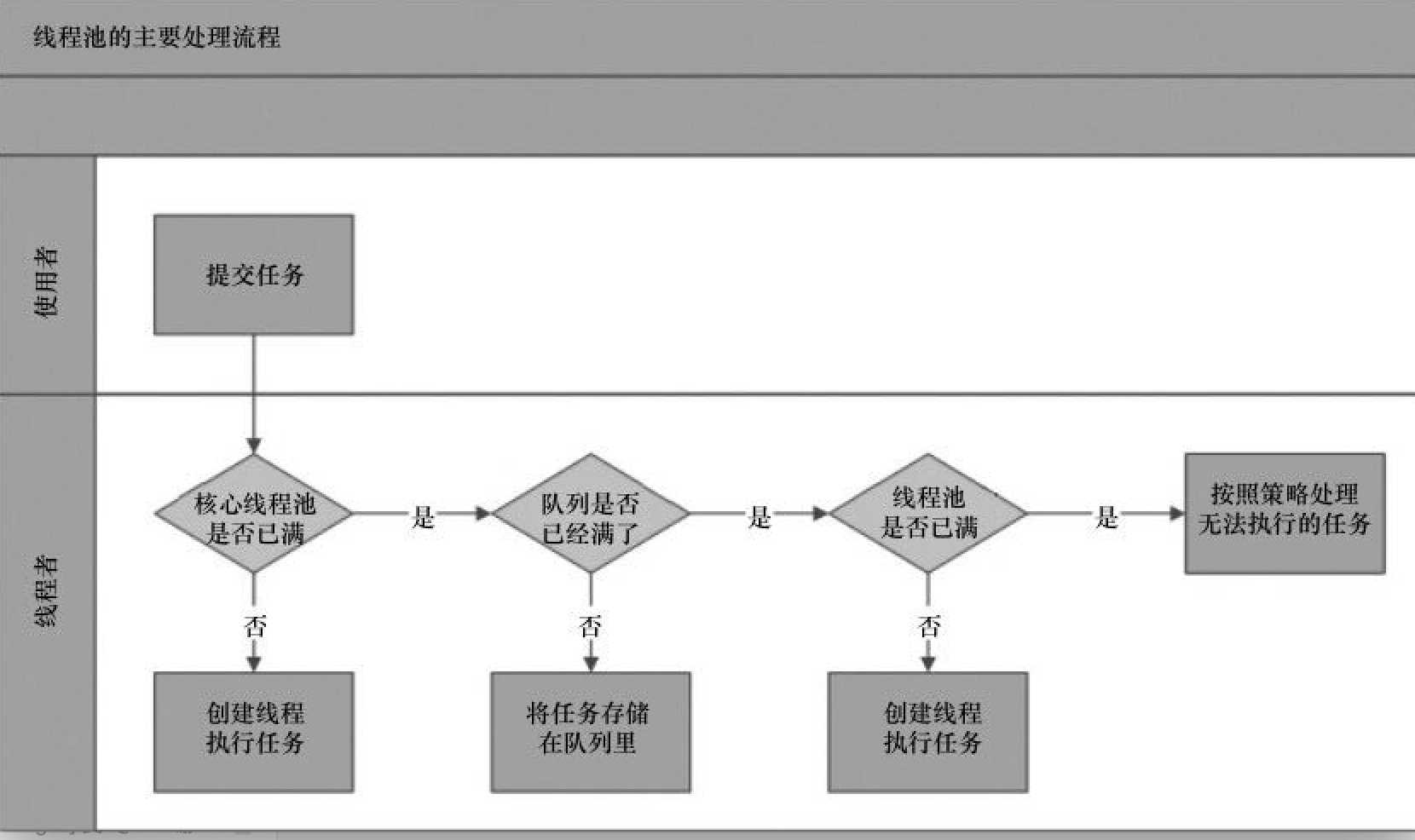
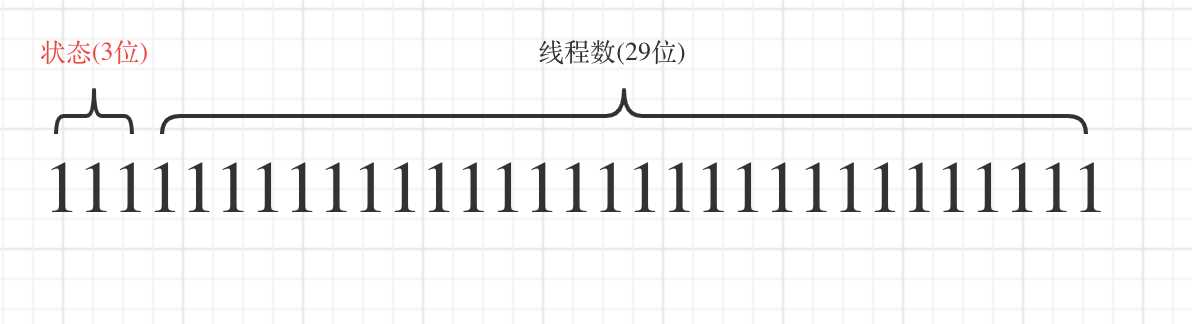
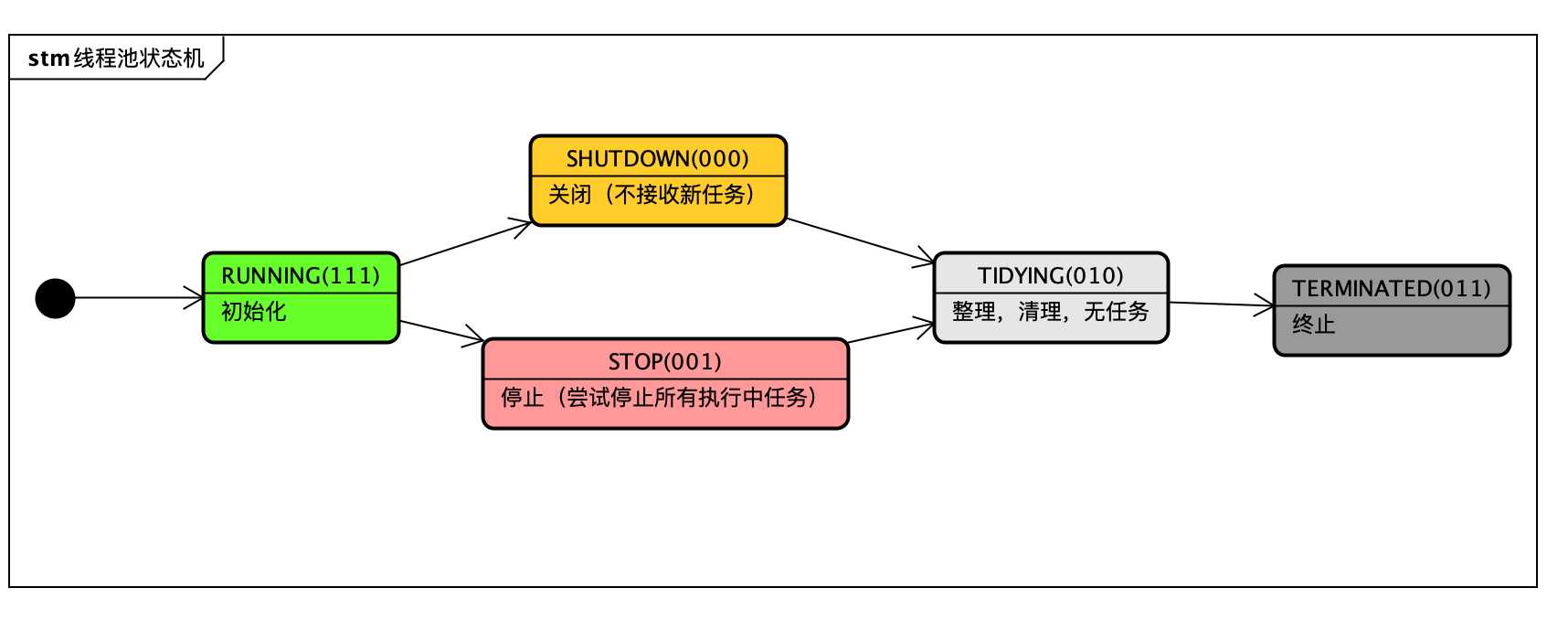
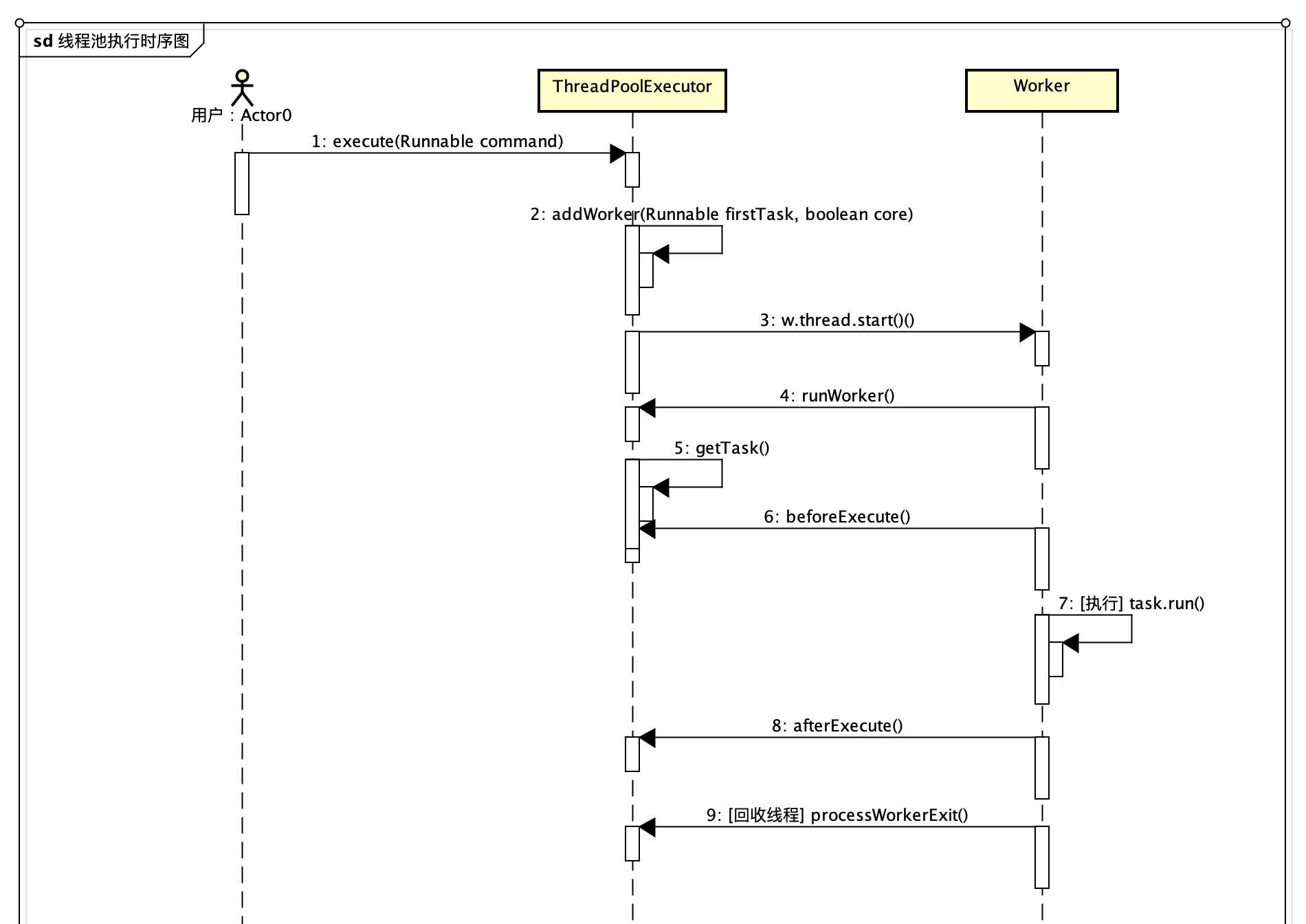
标签:let tab reserve creating 线程池 reads switch 平台 necessary 随着处理器的核心越来越多,利用多线程技术可以把计算逻辑拆分成多个片段,分配到多个核心上,可以显著减少处理时间,提高效率;复杂的业务逻辑,可以使用多线程并发处理,缩短响应时间,提高用户体验。java的线程机制是抢占式协作多线程, 调用机制会周期性的中断线程,将上下文切换到另一个进程,线程越多,竞争会越多,切换会更频繁。所以增加线程带来的性能增加不是线性的,这就是amdahl定律。 再者,线程的创建与销毁,上下文切换都不是免费的。《并发编程实战》一书中对于线程创建与销毁开销说明: Thread lifecycle overhead. Thread creation and teardown are not free. The actual overhead varies across platforms, but thread creation takes time, introducing latency into request processing, and requires some processing activity by the JVM and OS. If requests are frequent and lightweight, as in most server applications, creating a new thread for each request can consume significative computing resources. 大意如下:“线程生命周期开销:创建和销毁都是有代价的。实际开销虽因平台有所不同,但是都要消耗时间,jvm和os 需要执行一些处理程序;在大数请求频繁的服务端应用中,如果为每个请求创建一个线程将消耗非常可观的计算机资源”。以上概念层的开销,那一个java线程的创建实际开销则是这样的: 上下问切换(context switching)也是有开销的,需要分配内存存储当前状态,克隆系统调用等,具体可以参考文末参考资料[2] 正是因为创建线程的代价是如此昂贵的(expensive),所以线程池出现了, 它以“池化”思想来管理资源,按需创建,分配,回收;并重复利用已有的线程资源。既然大家都用线程池,那么它的”真面目“是怎么样的呢-- 从源开开始。 java为多线程编程提供了良好的,考究并且一致的编程模型,让我们只需关注问题本身,而ThreadPoolExecutor类就是java为我们提供的线程池模型,其继承体系如下图,顶层接口定义了统一的行为,并将任务提交与任务执行的策略解藕开来;而AbstractExecutorService 抽象任务执行流程并串连起来;如此,子类只用关注某个具体方法了。 一般而言 ThreadPoolExecutor.execute(Runnable()) 是我们使用线程池的入口 execute方法的三个分支,决定了线程池中线程的创建执行策略(面试中经常碰到的场景就是:添加了多个任务时,创建了多少个线程): 上面的代码中的判断条件中有两个:workerCountOf(c) -- 获取当前线程数; isRunning(c) -- 线程池是否是运行状态。这两个方法的参数都是一个int类型,那么一个int是如何能同时表示两个类型呢。一个int 4个字节,32位,这里就是用指定位数(3位)来表示状态,剩下的29位表示线程数,下图展示了这个关系。jdk中还有一些其他类也同步用了这样方法,比如:ReentrantReadWriteLock,高16位表示共享锁的数量,低16位表示互斥锁的数量。 线程池做为一个对象,有自己的状态机,其状态变化是有内部事件驱动的。下图展示了每个状态以及对应值(状态值是3位二进制),及对应的行为。这里有个插曲:以前面试被问到线程池shutwon和stop的差别。当时认识不清说得特别含糊,其实从这两个状态的英文单词的含义就可以看出7,8分了。 showdown 牛津翻译为:the act of closing a factory or business or stopping a large machine from working, either temporarily or permanently。体现的是进行时,closing,stopping;stop 意思比较多,但都是表示的一个意思:end / not continue。大师的变量名命名那真是相当精确的,要不怎么都提倡程序员学好英语呢。 看完了线程池的调度入口,了解了线程池的状态机,我们继续来看下方法 addWorker(Runnable firstTask, boolean core),前文说到线程池的把任务的提交和执行解藕,那就是如何串连的呢,addWorker方法就很好的完成的这个串连。这个方法主要分两个部分: 1,根据线程池状态及线程数判断是返回还是继续。其中第一个 if 条件尤为复杂,已经有注释。 2,创建工作进程对象 Worker w ,并执行其持有的线程对象thread 的start 方法。顺利让解藕的执行部分开始工作。 这里的代码逻辑不复杂,有一个标记还是有意思的: retry:(标记,可以写成任意如:abc:) / continue retry ;(跳出当前循环) /break retry; (跳出外层循环)。 以后跳出双重循环是不是也可以这样写? 接下来任务的执行就交给了工作线程 Worker w 了,这是一个内部类实现了接口 Runnable,构造函数中对的 属性thread初始化传是this, 如此 addWorker 方法中的 t.start(); 就顺利调用了Worker的run 方法了,而run方法又调用 runWorker。所以真正执行任务的最终方法在这里 -- runWorker。 我们继续来读最关键的方法runWorker,我删除了一些判断以及异常处理的代码,让我们可以清晰看到处理逻辑:获取任务,执行,回收线程。获取任务有两种情况:1,线程数小于核心数和队列满了但线程未到最大线程数时直接传入了任务;2,从阻塞获取任务,getTask()方法完成了这一任务 ThreadPoolExecutor 中定义了 HashSet 文章开头提到流量增大,心中不安,很大一部分原因,就是因为无法监控到线上线程池的状态,比如阻塞队列中的任务数,活跃线程数,线程池大小等等。当然这也是原于早前的无知,平时我们写代码主要分成两部分:功能性代码,实现业务功能;运维性代码,监控程序状态,分析问题。大师的代码也不例外,只是优雅很多。ThreadPoolExecutor 中有提供了相关运维代码,并在runWorker 中使用模板方法设计模式,为我们获取线程池状态等信息提供接口了,比如:beforeExecute(wt, task); afterExecute(task, thrown); ThreadPoolExecutor中这两个方法都是空实现,我们可以继承,并重写完成状态的获取。获取线程池运维状态提代了如下方法下图。 参考了一位网友的代码(忘记出处了),继承ThreadPoolExecutor ,重写afterExecute,打印线程池相关信息 线程池 标签:let tab reserve creating 线程池 reads switch 平台 necessary 原文地址:https://www.cnblogs.com/ysd139856/p/12737005.html为什么要用线程池
源码分析

public void execute(Runnable command) {
if (command == null)
// 三种情况:
int c = ctl.get();
//1,线程数 少于 核心线程 直接创建线程
if (workerCountOf(c)
// CAPACITY= 00011111111111111111111111111111(29个1)
// 获取当前线程数
// 线程池的最大数就是2^29-1
private static int workerCountOf(int c) {
return c & CAPACITY;
}
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
Worker
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
// 注意:这里,这个线程 传的runnable 是this, 也就是 worker本身, 所以start()后进入runnable状态,等到获取时间片后,就执行 run方法。
this.thread = getThreadFactory().newThread(this);
}
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();try {
Throwable thrown = null;
try {
task.run();
}
afterExecute(task, thrown);
} finally { task = null; // 统计完成任务数
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
//回收工作线程,尝试更新状态。
processWorkerExit(w, completedAbruptly);
}
}
线程池监控

 View Code
View Code
上一篇:常见的排序算法