4.K均值算法--应用
2021-02-11 15:20
标签:gets 压缩图片 均值 limit 保存 数值 使用 learn 中文显示 1. 应用K-means算法进行图片压缩 读取一张图片 观察图片文件大小,占内存大小,图片数据结构,线性化 用kmeans对图片像素颜色进行聚类 获取每个像素的颜色类别,每个类别的颜色 压缩图片生成:以聚类中收替代原像素颜色,还原为二维 观察压缩图片的文件大小,占内存大小 结果: 未压缩: 压缩后: 2.可以根据患者的指标进行癌症患者的分类 4.K均值算法--应用 标签:gets 压缩图片 均值 limit 保存 数值 使用 learn 中文显示 原文地址:https://www.cnblogs.com/chuichuichui1998/p/12735261.htmlfrom sklearn.datasets import load_sample_image
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from pylab import mpl
import sys
import numpy as np
import matplotlib.image as img
import PIL
mpl.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 中文显示
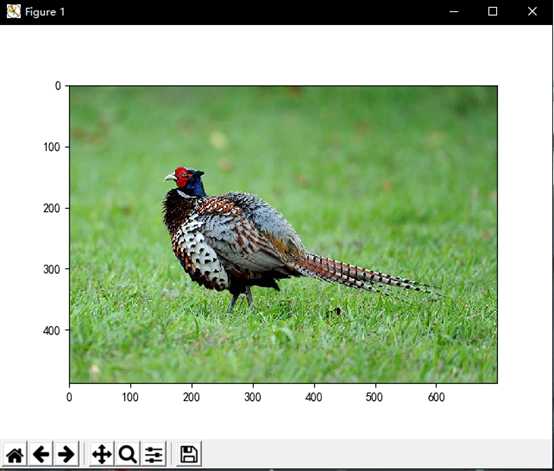
china = img.imread(‘duolajiang.jpg‘) # 读取图片
img.imsave(‘duolajiang.jpg‘, china) # 保存图片
print("原图内存为", sys.getsizeof(china))
print("原图数据结构为", china.shape)
plt.imshow(china)
plt.show()
image = china[::3, ::3]
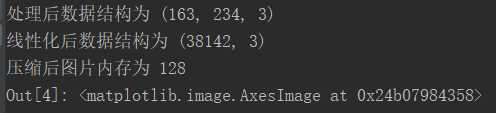
print("处理后数据结构为", image.shape)
X = image.reshape(-1, 3) # 线性化处理
print("线性化后数据结构为", X.shape)
n_colors = 64
model = KMeans(n_colors) # 聚类为64个聚类中心
labels = model.fit_predict(X) #一维数组,30602个元素的类别
colors = model.cluster_centers_ # 二维数组(64,3)
new_image = colors[labels] # 聚类中心代替
new_image = new_image.reshape(image.shape) # 还原为二维数组
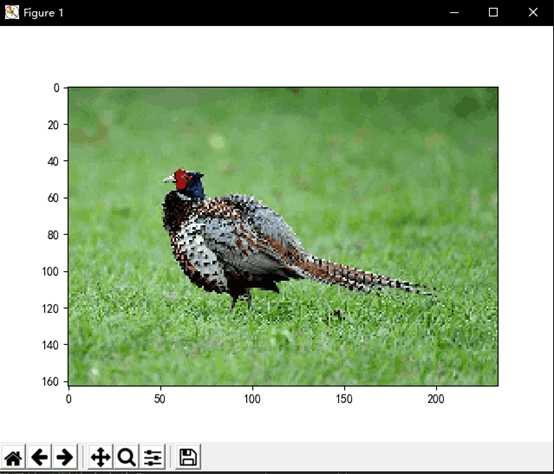
print("压缩后图片内存为", sys.getsizeof(new_image))
plt.imshow(new_image.astype(np.uint8))
plt.show()
img.imsave(‘new.jpg‘, new_image) # 保存图片
import scipy
import scipy.cluster.hierarchy as sch
from scipy.cluster.vq import vq,kmeans,whiten
import numpy as np
import matplotlib.pylab as plt
#待聚类的数据点,cancer.csv有653行数据,每行数据有11维:
dataset = np.loadtxt(‘cancer.csv‘, delimiter=",")
#np数据从0开始计算,第0维维序号排除,第10维为标签排除,所以为1到9
points = dataset[:,1:9]
cancer_label = dataset[:,10]
print("points:\n",points)
print("cancer_label:\n",cancer_label)
# k-means聚类
#将原始数据做归一化处理
data=whiten(points)
#使用kmeans函数进行聚类,输入第一维为数据,第二维为聚类个数k.
#有些时候我们可能不知道最终究竟聚成多少类,一个办法是用层次聚类的结果进行初始化.当然也可以直接输入某个数值.
#k-means最后输出的结果其实是两维的,第一维是聚类中心,第二维是损失distortion,我们在这里只取第一维,所以最后有个[0]
#centroid = kmeans(data,max(cluster))[0]
centroid = kmeans(data,2)[0]
print(centroid)
#使用vq函数根据聚类中心对所有数据进行分类,vq的输出也是两维的,[0]表示的是所有数据的label
label=vq(data,centroid)[0]
num = [0,0]
for i in label:
if(i == 0):
num[0] = num[0] + 1
else:
num[1] = num[1] + 1
print(‘num =‘,num)
#np.savetxt(‘file.csv‘,label)
print("Final clustering by k-means:\n",label)
result = np.subtract(label,cancer_label)
print("result:\n",result)
count = [0,0]
for i in result:
if(i == 0):
count[0] = count[0] + 1
else:
count[1] = count[1] + 1
print(count)
print(float(count[1])/(count[0]+count[1]))
下一篇:使用ajax来进行登录验证