几种获取html元素的方法
2021-02-12 05:15
标签:class type utf-8 访问 get 个数 四种方法 har ima DOM是文档对象模型,这里文档代表的是整个网页,所以获取元素都是通过document对象来获取的。第一行JS代码的作用是会把html元素转换为一个JS对象,那个div就是一个JavaScript对象。其次应注意,像这种方式获取html元素,如果有多个的话,返回的是一个数组。 几种获取html元素的方法 标签:class type utf-8 访问 get 个数 四种方法 har ima 原文地址:https://www.cnblogs.com/EvanTheGreat/p/14394026.html 1 DOCTYPE html>
2 html>
3 head>
4 meta charset="utf-8">
5 title>title>
6
7 head>
8 body>
9 div id="one">
10 span>
11 在 HTML 中 DOM(文档对象模型)是 Web 前端里最基础、最常用的—模型。
12 例如,一个网页其实就是一个 HTML 文件,经过浏览器的解析,最终呈现在用户面前。
13 span>
14 div>
15 div class="two">
16 span>
17 每一层可以同时存在很多标签,比如 head 和 body 属于同一层,它们被外面的 html 套着。
18 这样的结构很像计算机里的文件夹。例如,“我的电脑”是最外层,里面套着 C、D、E、F 盘,每个
19 盘里又有很多文件夹,文件夹里又有文件夹,逐个打开后才能看到具体的文件。
20 span>
21 div>
22 div class="three" name="last">
23 span>
24 为什么要按照这种结构来组织呢?目的其实是方便解析和查询。解析的时候,从外向里循序渐进,
25 好比按照图纸盖房子,先盖围墙,再盖走廊,最后才盖卧室。查询的时候,会遵循一条明确的路线,
26 例如“D盘/文化交流/影视作品/给产品经理讲技术avi”,一层一层地缩小范围,查找效率会非常高。
27 span>
28 div>
29 body>
30 html>
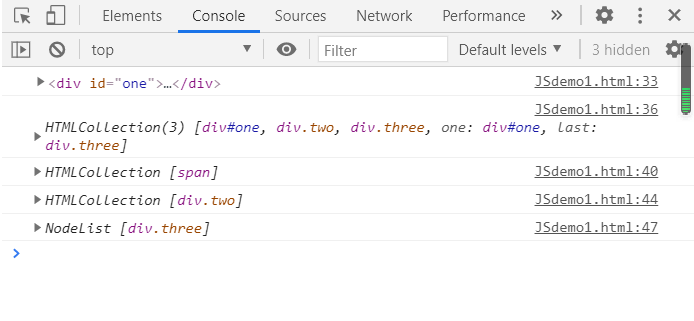
31 script type="text/javascript">
32 var div = document.getElementById("one"); //通过id访问
33 console.log(div);
34
35 var div2 = document.getElementsByTagName("div"); //通过TagName访问
36 console.log(div2);
37 /*第三种方法*/
38 var div3 = document.getElementById("one");
39 var arr1 = div3.getElementsByTagName("span"); //调用div3里面的通过标签名访问的函数,限定范围
40 console.log(arr1);
41
42 /*第四种方法*/
43 var arr2 = document.getElementsByClassName("two"); //通过类名访问
44 console.log(arr2);
45
46 var arr3 = document.getElementsByName("last"); //第五种方法,通过name访问
47 console.log(arr3);
48 script>
上一篇:4.K均值算法--应用
下一篇:Ubuntu 18.04 安装Tomcat9 遇到的问题Tomcat9 Error: Could not find or load main class org.apache.catalina.sta