Python-爬取斗图啦网站
2021-02-13 15:21
标签:inf itext www wow hot head pat ini safari 首先我们简单的分析一下这个网站,我们需要爬取的就是图片,然后将图片网址爬取下来,下载 . 图片的下载地址就在这里然后我们开始吧 Python-爬取斗图啦网站 标签:inf itext www wow hot head pat ini safari 原文地址:https://www.cnblogs.com/wocaonidaye/p/12725460.html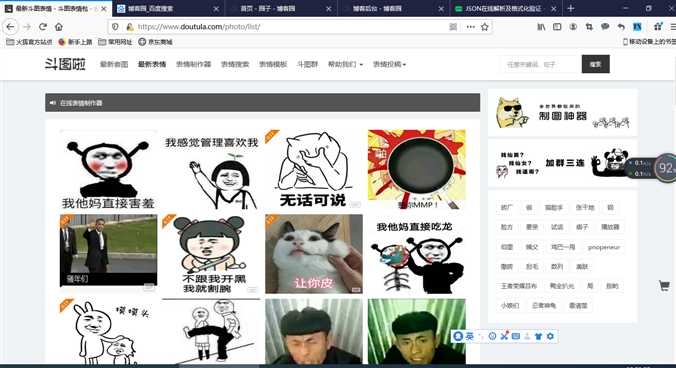
from lxml import etree
import requests
from urllib import request
import re
import os
import threading
from queue import Queue
# 创建生产者类。目的是为了获取当前网页的图片地址
class Procuder(threading.Thread):
def __init__(self, page_queue,img_queue,*args,**kwargs):
self.headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36‘
}
super(Procuder, self).__init__(*args, **kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty():
break
ulr = self.page_queue.get()
self.parse_page(ulr)
def parse_page(self,url):
repon = requests.get(url, headers=self.headers)
text = repon.text
html = etree.HTML(text)
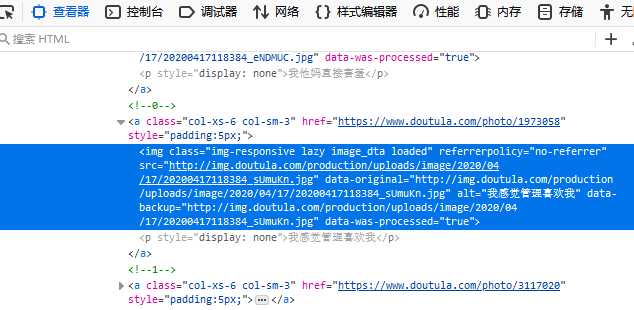
imgs_text = html.xpath("""//a[@class="col-xs-6 col-sm-3"]//img[@referrerpolicy="no-referrer"]/@alt""")
imgs = html.xpath("""//a[@class="col-xs-6 col-sm-3"]//img[@referrerpolicy="no-referrer"]/@data-original""")
for values in zip(imgs_text, imgs):
imgs_texts, img = values
imgs_text = re.sub(r‘[\??,,。.!!\.、\*]‘, ‘‘, imgs_texts)
imgs_houzui = os.path.splitext(img)[1]
img_life = imgs_text + imgs_houzui
self.img_queue.put((img,img_life))
# 创建消费者类,目的为了下载已经存储进img_queue队列的图片地址
class Consumer(threading.Thread):
def __init__(self, page_queue,img_queue,*args,**kwargs):
super(Consumer, self).__init__(*args, **kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img, img_life = self.img_queue.get()
request.urlretrieve(img, "C:\\Users\\Administrator\\Desktop\\imgs\\" + img_life)
print("%s下载成功" % img_life)
def main():
# 创建需要存储ulr的队列
page_queue = Queue(3391)
img_queue = Queue(2000)
for i in range(1, 3392):
url = "https://www.doutula.com/photo/list/?page={}".format(i)
page_queue.put(url)
for x in range(20):
t = Procuder(page_queue,img_queue)
t.start()
for h in range(30):
t = Consumer(page_queue,img_queue)
t.start()
if __name__ == ‘__main__‘:
main()