LRU算法Python实现
2021-02-14 13:17
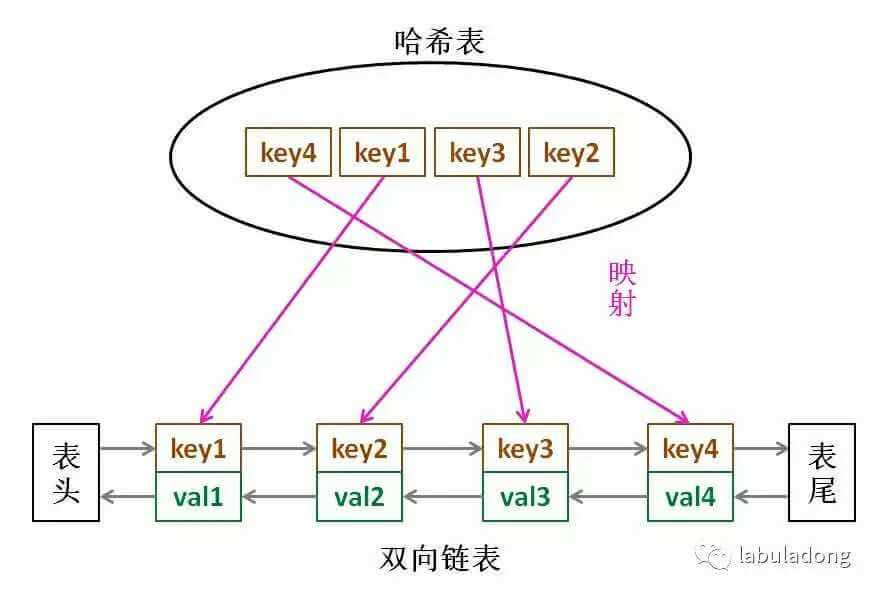
标签:条件 jsb else vbo 优先 param one 区分 als LRU 算法实际上是让你设计数据结构:首先要接收一个 capacity 参数作为缓存的最大容量,然后实现两个 API,一个是 put(key, val) 方法存入键值对,另一个是 get(key) 方法获取 key 对应的 val,如果 key 不存在则返回 -1。 注意哦,get 和 put 方法必须都是 O(1) 的时间复杂度,我们举个具体例子来看看 LRU 算法怎么工作。 分析上面的操作过程,要让 put 和 get 方法的时间复杂度为 O(1),我们可以总结出 cache 这个数据结构必要的条件:查找快,插入快,删除快,有顺序之分。 因为显然 cache 必须有顺序之分,以区分最近使用的和久未使用的数据;而且我们要在 cache 中查找键是否已存在;如果容量满了要删除最后一个数据;每次访问还要把数据插入到队头。 那么,什么数据结构同时符合上述条件呢?哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。所以结合一下,形成一种新的数据结构:哈希链表。 LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构长这样: 需要删除操作。删除一个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,而双向链表才能支持直接查找前驱,保证操作的时间复杂度 O(1)。 参考:https://blog.csdn.net/qq_35810838/article/details/83035759 https://labuladong.gitbook.io/algo/gao-pin-mian-shi-xi-lie/lru-suan-fa LRU算法Python实现 标签:条件 jsb else vbo 优先 param one 区分 als 原文地址:https://www.cnblogs.com/cassielcode/p/12723024.html/* 缓存容量为 2 */
LRUCache cache = new LRUCache(2);
// 你可以把 cache 理解成一个队列
// 假设左边是队头,右边是队尾
// 最近使用的排在队头,久未使用的排在队尾
// 圆括号表示键值对 (key, val)
cache.put(1, 1);
// cache = [(1, 1)]
cache.put(2, 2);
// cache = [(2, 2), (1, 1)]
cache.get(1); // 返回 1
// cache = [(1, 1), (2, 2)]
// 解释:因为最近访问了键 1,所以提前至队头
// 返回键 1 对应的值 1
cache.put(3, 3);
// cache = [(3, 3), (1, 1)]
// 解释:缓存容量已满,需要删除内容空出位置
// 优先删除久未使用的数据,也就是队尾的数据
// 然后把新的数据插入队头
cache.get(2); // 返回 -1 (未找到)
// cache = [(3, 3), (1, 1)]
// 解释:cache 中不存在键为 2 的数据
cache.put(1, 4);
// cache = [(1, 4), (3, 3)]
// 解释:键 1 已存在,把原始值 1 覆盖为 4
// 不要忘了也要将键值对提前到队头
‘‘‘
方法一
class LRUCache:
#@param capacity,an integer
def __init__(self,capacity):
self.cache ={}
self.used_list=[]
self.capacity = capacity
#@return an integer
def get(self,key):
if key in self.cache:
#使用一个list来记录访问的顺序,最先访问的放在list的前面,最后访问的放在list的后面,故cache已满时,则删除list[0],然后插入新项;
if key != self.used_list[-1]:
self.used_list.remove(key)
self.used_list.append(key)
return self.cache[key]
else:
return -1
def put(self,key,value):
if key in self.cache:
self.used_list.remove(key)
elif len(self.cache) == self.capacity:
self.cache.pop(self.used_list.pop(0))
self.used_list.append(key)
self.cache[key] = value
‘‘‘
#方法二:
import collections
#基于orderedDict实现
class LRUCache(collections.OrderedDict):
‘‘‘
function:利用collection.OrdereDict数据类型实现最近最少使用的算法
OrdereDict有个特殊的方法popitem(Last=False)时则实现队列,弹出最先插入的元素
而当Last=True则实现堆栈方法,弹出的是最近插入的那个元素。
实现了两个方法:get(key)取出键中对应的值,若没有返回None
set(key,value)更具LRU特性添加元素
‘‘‘
def __init__(self,size=5):
self.size = size
self.cache = collections.OrderedDict()#有序字典
def get(self,key):
if key in self.cache.keys():
#因为在访问的同时还要记录访问的次数(顺序)
value = self.cache.pop(key)
#保证最近访问的永远在list的最后面
self.cache[key] = value
return value
else:
value = None
return value
def put(self,key,value):
if key in self.cache.keys():
self.cache.pop(key)
self.cache[key] = value
elif self.size == len(self.cache):
self.cache.popitem(last=False)
self.cache[key] = value
else:
self.cache[key] = value
if __name__ == ‘__main__‘:
test = LRUCache()
test.put(‘a‘,1)
test.put(‘b‘,2)
test.put(‘c‘,3)
test.put(‘d‘,4)
test.put(‘e‘,5)
# test.put(‘f‘,6)
print (test.get(‘a‘))