Flume从入门到实战
2021-02-14 14:19
第1章 Flume概述
1.1 Flume定义
Flume(水槽) 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
在2009年Flume被捐赠了apache软件基金会,为hadoop相关组件之一。尤其近几年随着flume的不断被完善以及升级版本的逐一推出,特别是flume-ng;,同时flume内部的各种组件不断丰富,用户在开发的过程中使用的便利性得到很大的改善,现已成为apache top项目之一。
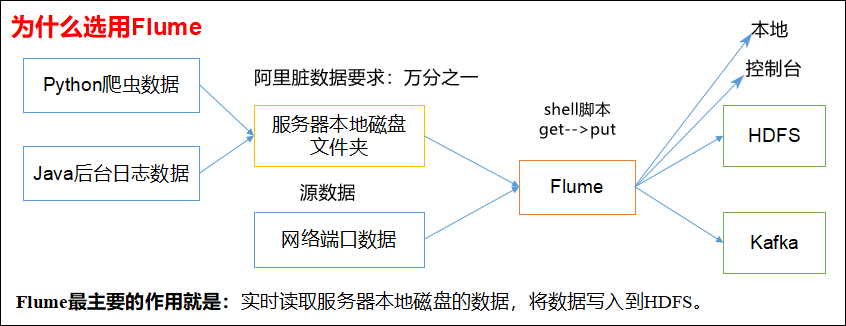
1.2 Flume组成架构
Flume组成架构如下图所示:
Flume组成架构
下面我们来详细介绍一下Flume架构中的组件。
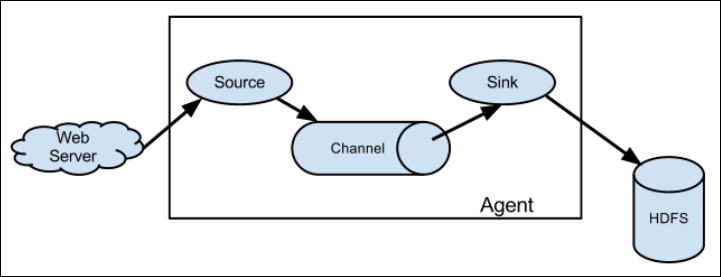
1.2.1 Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的地,是Flume数据传输的基本单元。
Agent主要有3个部分组成,Source、Channel、Sink。
1.2.2 Source
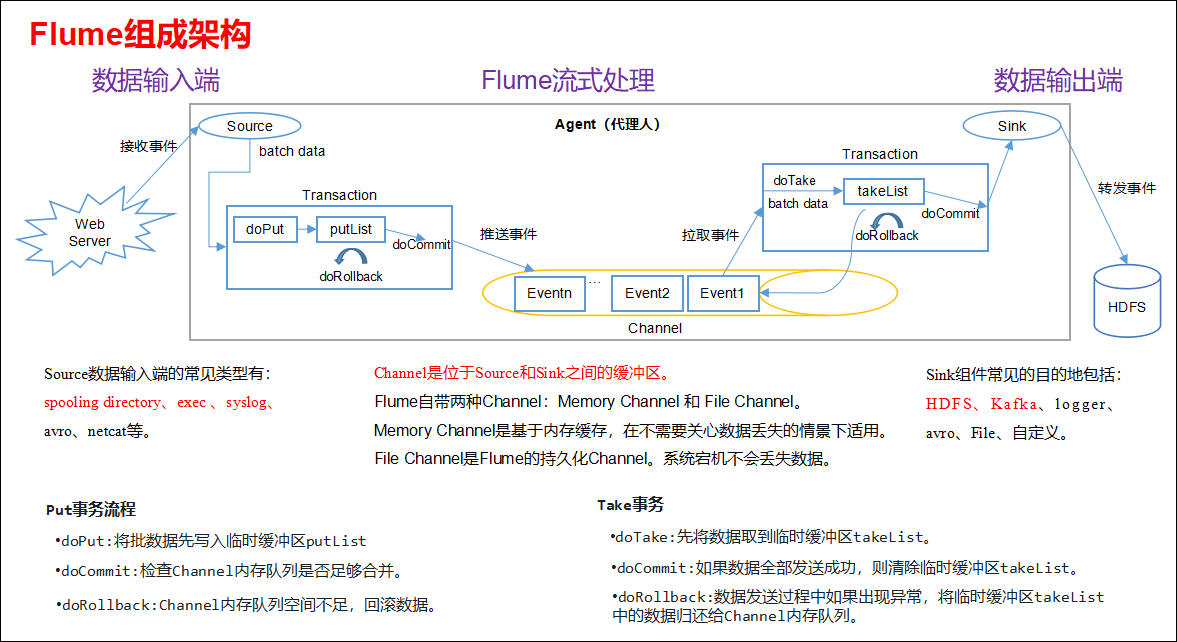
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec(Linux命令)、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
1.2.3 Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel 和 File Channel。
Memory Channel是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
1.2.4 Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。
1.2.5 Event
传输单元,Flume数据传输的基本单元,以事件的形式将数据从源头送至目的地。
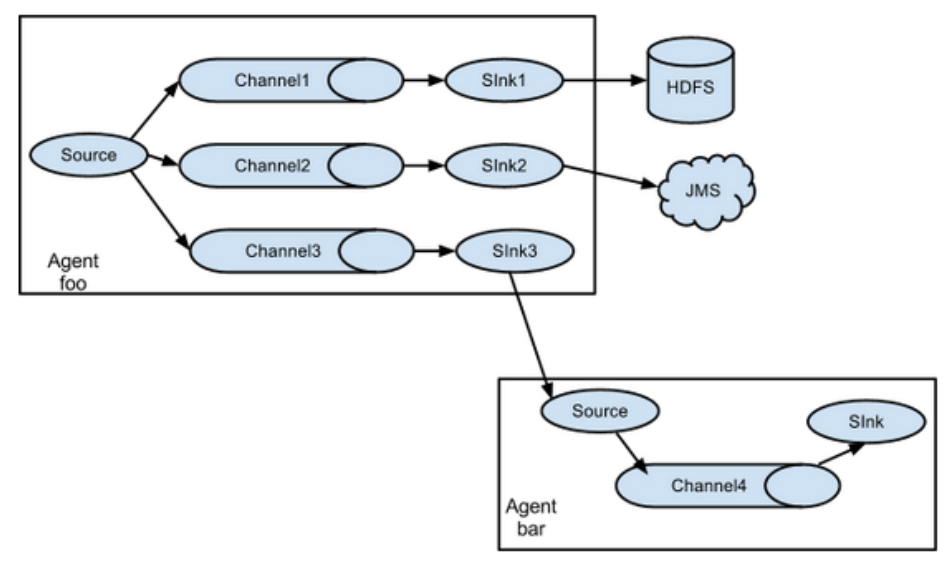
1.3 Flume拓扑结构
Flume的拓扑结构如下图所示:
Flume Agent连接
单source,多channel、sink
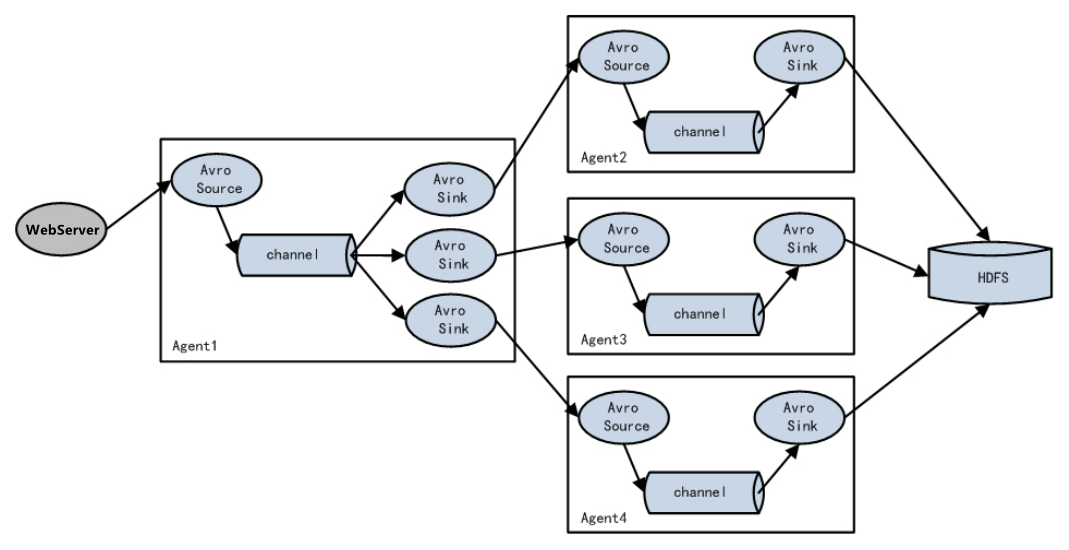
Flume负载均衡
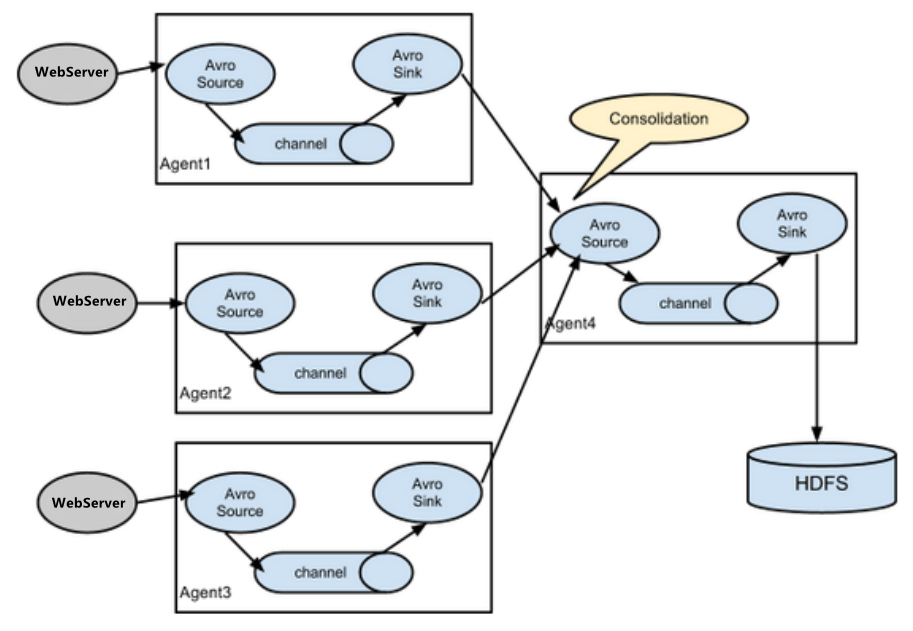
Flume Agent聚合
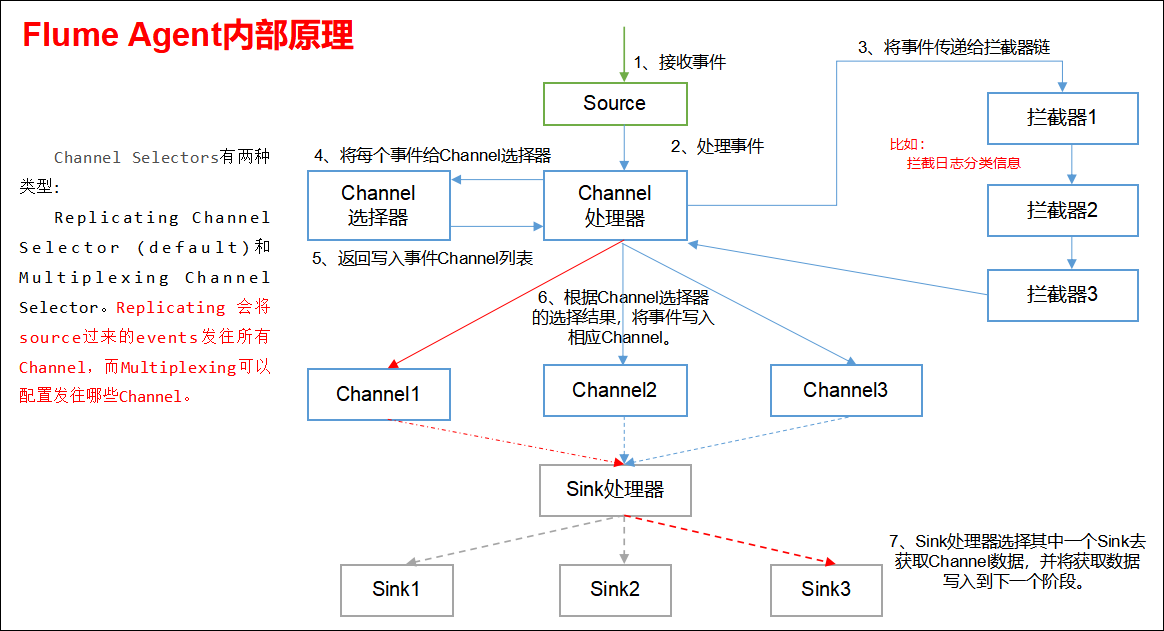
1.4 Flume Agent内部原理
1.5 Hadoop三大发行版本
-
Hadoop(哈道普)三大发行版本:Apache、Cloudera、Hortonworks。
Apache 版本最原始(最基础)的版本,对于入门学习最好。
Cloudera 在大型互联网企业中用的较多。(简称:CDH版,收费)
Hortonworks 文档较好。 -
1、Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/ -
2、Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/- (1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
- (2)
2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support。 - (3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
- (4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
- (5)Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
-
3、Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform- (1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
- (2)
公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。 - (3)雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
- (4)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
- (5)HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
- (6)Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
第2章 Flume快速入门
2.1 Flume安装地址
1) Flume官网地址
http://flume.apache.org/
2)文档查看地址
http://flume.apache.org/FlumeUserGuide.html
3)下载地址
http://archive.apache.org/dist/flume/
2.2 安装部署
1)将apache-flume-1.7.0-bin.tar.gz上传到linux的/opt/software目录下
2)解压apache-flume-1.7.0-bin.tar.gz到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
3)修改apache-flume-1.7.0-bin的名称为flume
[atguigu@hadoop102 module]$ mv apache-flume-1.7.0-bin flume
4)将flume/conf下的flume-env.sh.template文件修改为flume-env.sh,并配置flume-env.sh文件
[atguigu@hadoop102 conf]$ mv flume-env.sh.template flume-env.sh
[atguigu@hadoop102 conf]$ vim flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
第3章 Flume企业开发案例
3.1 监控端口数据官方案例
1)案例需求:首先,Flume监控本机44444端口,然后通过telnet工具向本机44444端口发送消息,最后Flume将监听的数据实时显示在控制台。
2)需求分析:

3)实现步骤:
1.安装telnet工具
将rpm软件包(xinetd-2.3.14-40.el6.x86_64.rpm、telnet-0.17-48.el6.x86_64.rpm和telnet-server-0.17-48.el6.x86_64.rpm)拷入/opt/software文件夹下面。执行RPM软件包安装命令:
[atguigu@hadoop102 software]$ sudo rpm -ivh xinetd-2.3.14-40.el6.x86_64.rpm
[atguigu@hadoop102 software]$ sudo rpm -ivh telnet-0.17-48.el6.x86_64.rpm
[atguigu@hadoop102 software]$ sudo rpm -ivh telnet-server-0.17-48.el6.x86_64.rpm
2.判断44444端口是否被占用
[atguigu@hadoop102 flume-telnet]$ sudo netstat -tunlp | grep 44444
功能描述:netstat命令是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。
基本语法:netstat [选项]
选项参数:
-t或--tcp:显示TCP传输协议的连线状况;
-u或--udp:显示UDP传输协议的连线状况;
-n或--numeric:直接使用ip地址,而不通过域名服务器;
-l或--listening:显示监控中的服务器的Socket;
-p或--programs:显示正在使用Socket的程序识别码和程序名称;
3.创建Flume Agent配置文件flume-telnet-logger.conf
在flume目录下创建job文件夹并进入job文件夹。
[atguigu@hadoop102 flume]$ pwd
/opt/module/flume
[atguigu@hadoop102 flume]$ mkdir job
[atguigu@hadoop102 flume]$ cd job/
在job文件夹下创建Flume Agent配置文件flume-telnet-logger.conf
[atguigu@hadoop102 job]$ touch flume-telnet-logger.conf
在flume-telnet-logger.conf文件中添加如下内容:
[atguigu@hadoop102 job]$ vim flume-telnet-logger.conf
添加内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注:配置文件来源于官方手册:http://flume.apache.org/FlumeUserGuide.html

- 先开启flume监听端口
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-telnet-logger.conf -Dflume.root.logger=INFO,console
参数说明:
--conf conf/ :表示配置文件存储在conf/目录
--name a1 :表示给agent起名为a1(要与配置文件一致)
--conf-file job/flume-telnet.conf :flume本次启动读取的配置文件是在job文件夹下的flume-telnet.conf文件
-Dflume.root.logger==INFO,console :-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error
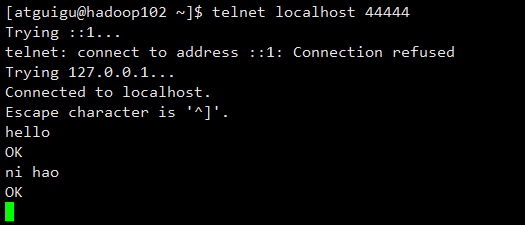
5.使用telnet工具向本机的44444端口发送内容
[atguigu@hadoop102 ~]$ telnet localhost 44444
如下图所示:
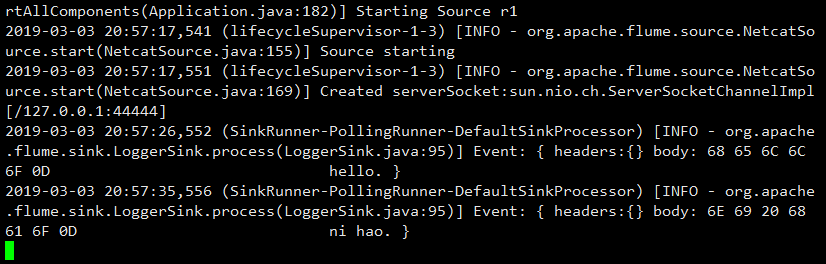
6.在Flume监听页面观察接收数据情况
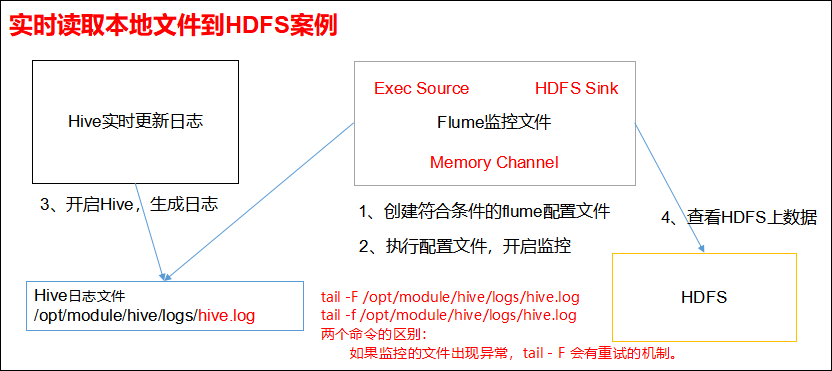
3.2 实时读取本地文件到HDFS案例
1)案例需求:实时监控Hive日志,并上传到HDFS中。(实际开发中是tomcat中产生的日志:订单日志、点击流日志等)
2)需求分析:
3)实现步骤:
1.Flume要想将数据输出到HDFS,必须持有Hadoop相关jar包
将
commons-configuration-1.6.jar
hadoop-auth-2.7.2.jar
hadoop-common-2.7.2.jar
hadoop-hdfs-2.7.2.jar
commons-io-2.4.jar
htrace-core-3.1.0-incubating.jar
拷贝到/opt/module/flume/lib文件夹下。
2.创建flume-file-hdfs.conf文件
创建文件
[atguigu@hadoop102 job]$ touch flume-file-hdfs.conf
注:要想读取Linux系统中的文件,就得按照Linux命令的规则执行命令。由于Hive日志在Linux系统中,所以读取文件的类型选择:exec即execute执行的意思。表示执行Linux命令来读取文件。
[atguigu@hadoop102 job]$ vim flume-file-hdfs.conf
添加如下内容:
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:9000/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k2.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
配置文件解析:

3.执行监控配置
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf
4.开启Hadoop和Hive并操作Hive产生日志
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
[atguigu@hadoop102 hive]$ bin/hive
hive (default)>
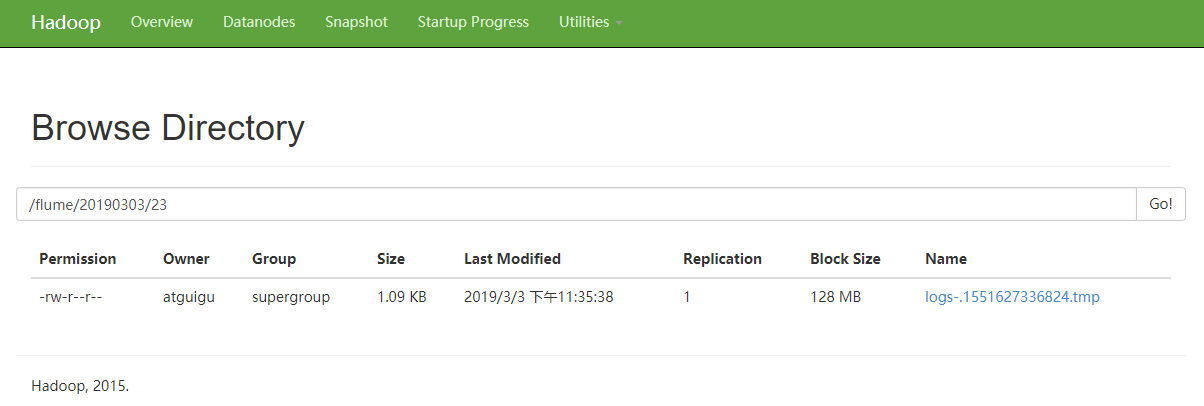
5.在HDFS上查看文件。
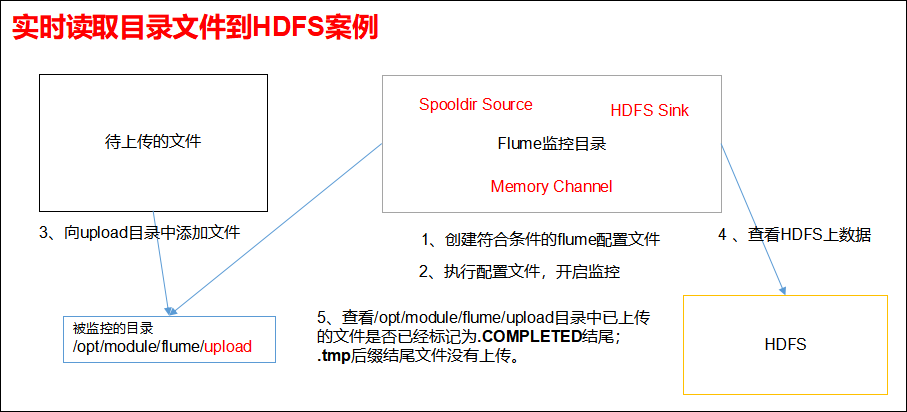
3.3 实时读取目录文件到HDFS案例
1)案例需求:使用Flume监听整个目录的文件。
2)需求分析:
3)实现步骤:
1.创建配置文件flume-dir-hdfs.conf
创建一个文件
[atguigu@hadoop102 job]$ touch flume-dir-hdfs.conf
打开文件
[atguigu@hadoop102 job]$ vim flume-dir-hdfs.conf
添加如下内容:
# Name the components on this agent
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop102:9000/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
#最小冗余数
a3.sinks.k3.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
配置文件解析:

- 启动监控文件夹命令
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf
说明: 在使用Spooling Directory Source时
1) 不要在监控目录中创建并持续修改文件
2) 上传完成的文件会以.COMPLETED结尾
3) 被监控文件夹每500毫秒扫描一次文件变动
- 向upload文件夹中添加文件
在/opt/module/flume目录下创建upload文件夹
[atguigu@hadoop102 flume]$ mkdir upload
向upload文件夹中添加文件
[atguigu@hadoop102 upload]$ touch atguigu.txt
[atguigu@hadoop102 upload]$ touch atguigu.tmp
[atguigu@hadoop102 upload]$ touch atguigu.log
查看数据
- 查看HDFS上的数据
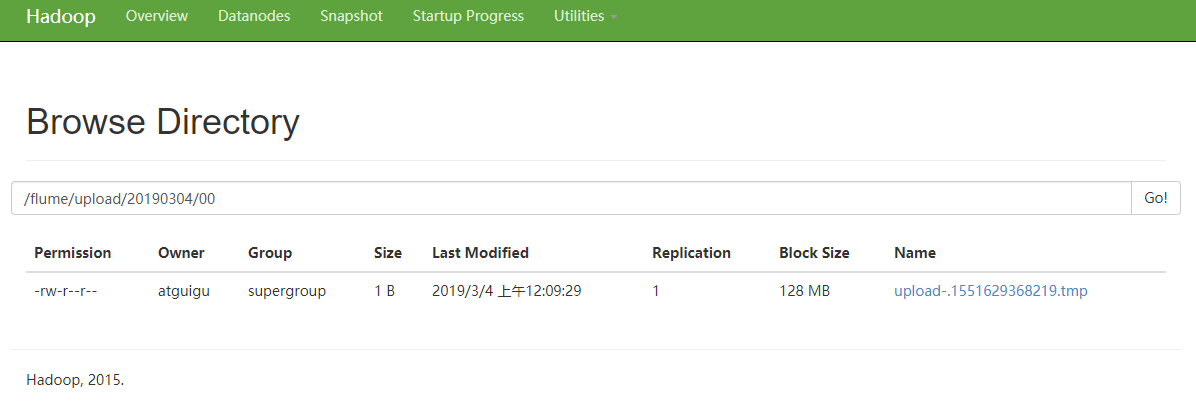
- 等待1s,再次查询upload文件夹
[atguigu@hadoop102 upload]$ pwd
/opt/module/flume/upload
[atguigu@hadoop102 upload]$ ll
总用量 0
-rw-rw-r--. 1 atguigu atguigu 0 3月 4 00:09 atguigu.log.COMPLETED
-rw-rw-r--. 1 atguigu atguigu 0 3月 4 00:09 atguigu.tmp
-rw-rw-r--. 1 atguigu atguigu 0 3月 4 00:09 atguigu.txt.COMPLETED
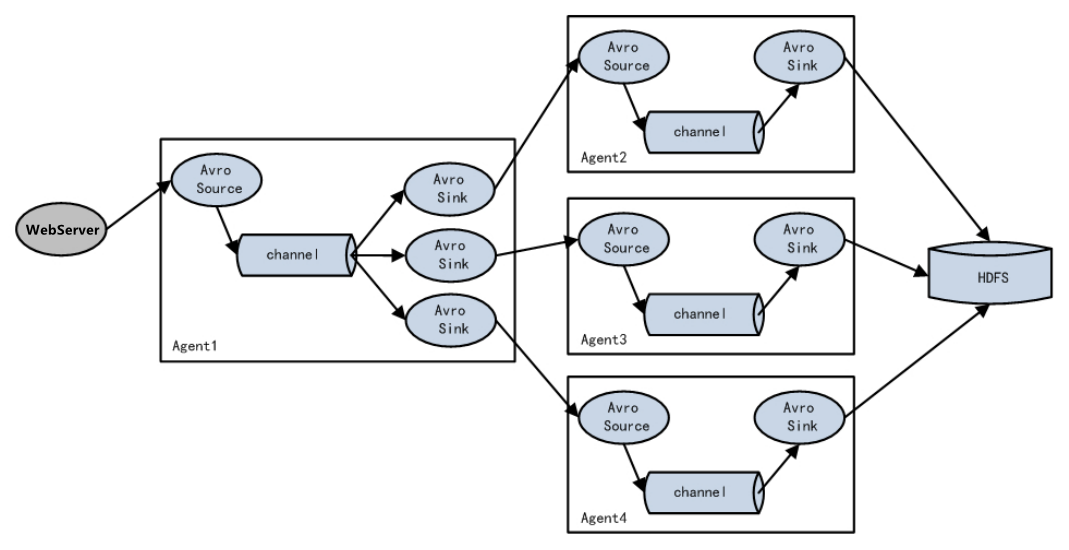
3.4 单数据源多出口案例(选择器)
单Source多Channel、Sink,如下图所示:
1)案例需求:使用Flume-1监控文件变动,Flume-1将变动内容传递给Flume-2,Flume-2负责存储到HDFS。同时Flume-1将变动内容传递给Flume-3,Flume-3负责输出到Local FileSystem。
2)需求分析:
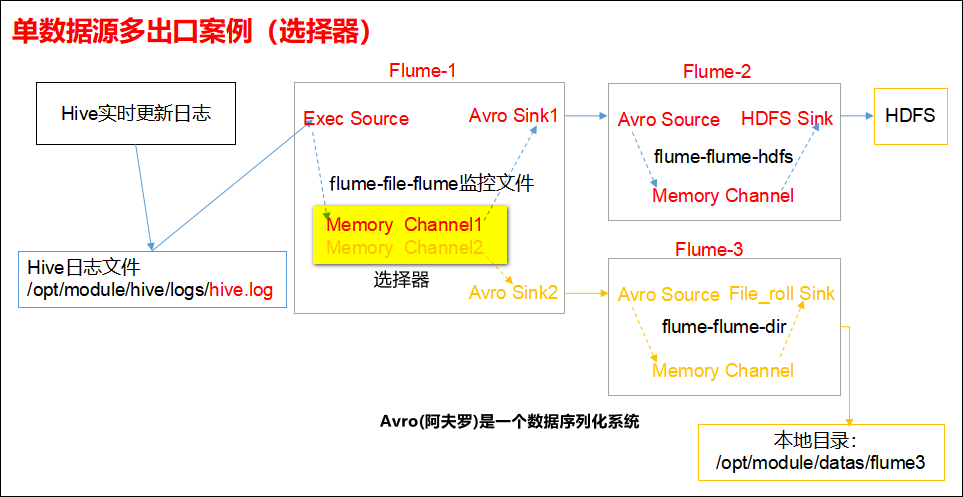
3)实现步骤:
0.准备工作
在/opt/module/flume/job目录下创建group1文件夹
[atguigu@hadoop102 job]$ mkdir group1
[atguigu@hadoop102 job]$ cd group1/
在/opt/module/datas/目录下创建flume3文件夹
[atguigu@hadoop102 datas]$ mkdir flume3
1.创建flume-file-flume.conf
配置1个接收日志文件的source和2个channel、2个sink,分别输送给flume-flume-hdfs和flume-flume-dir。
创建配置文件并打开:
[atguigu@hadoop102 group1]$ touch flume-file-flume.conf
[atguigu@hadoop102 group1]$ vim flume-file-flume.conf
添加如下内容:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 将数据流复制给所有channel
a1.sources.r1.selector.type = replicating
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
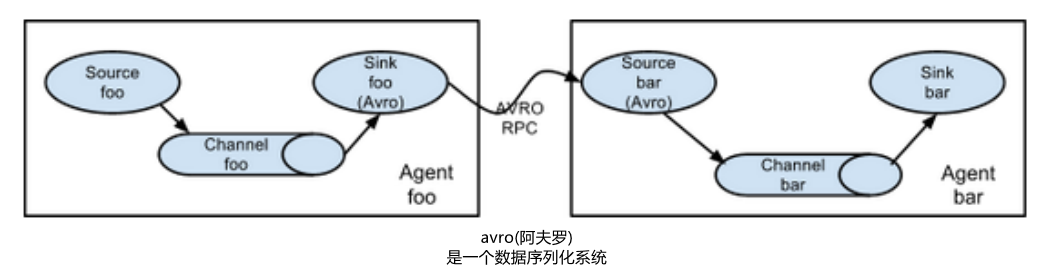
注:Avro是由Hadoop创始人Doug Cutting创建的一种跟语言无关的数据序列化和RPC框架。注:RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
2.创建flume-flume-hdfs.conf
配置上级Flume输出的Source,输出是到HDFS的Sink。
创建配置文件并打开
[atguigu@hadoop102 group1]$ touch flume-flume-hdfs.conf
[atguigu@hadoop102 group1]$ vim flume-flume-hdfs.conf
添加如下内容:
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hadoop102:9000/flume2/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k1.hdfs.filePrefix = flume2-
#是否按照时间滚动文件夹
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k1.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
a2.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k1.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k1.hdfs.minBlockReplicas = 1
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
3.创建flume-flume-dir.conf
配置上级Flume输出的Source,输出是到本地目录的Sink。
创建配置文件并打开
[atguigu@hadoop102 group1]$ touch flume-flume-dir.conf
[atguigu@hadoop102 group1]$ vim flume-flume-dir.conf
添加如下内容:
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop102
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /opt/module/datas/flume3
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
提示:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目录。
4.执行配置文件
分别开启对应配置文件:flume-flume-dir,flume-flume-hdfs,flume-file-flume。
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group1/flume-flume-dir.conf
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume-hdfs.conf
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-file-flume.conf
5.启动Hadoop和Hive
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
[atguigu@hadoop102 hive]$ bin/hive
hive (default)>
6.检查HDFS上数据
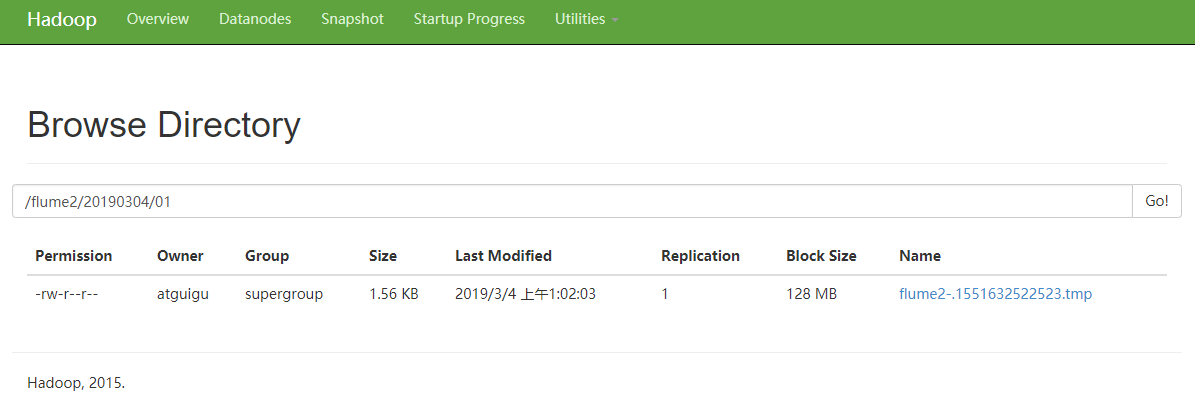
- 检查/opt/module/datas/flume3目录中数据
[atguigu@hadoop102 flume3]$ pwd
/opt/module/datas/flume3
[atguigu@hadoop102 flume3]$ ll
总用量 4
-rw-rw-r--. 1 atguigu atguigu 0 3月 4 01:01 1551632490229-1
-rw-rw-r--. 1 atguigu atguigu 1594 3月 4 01:02 1551632490229-2
[atguigu@hadoop102 flume3]$ ll
总用量 4
-rw-rw-r--. 1 atguigu atguigu 0 3月 4 01:01 1551632490229-1
-rw-rw-r--. 1 atguigu atguigu 3808 3月 4 01:02 1551632490229-2
-rw-rw-r--. 1 atguigu atguigu 0 3月 4 01:02 1551632490229-3
[atguigu@hadoop102 flume3]$ ll
总用量 8
-rw-rw-r--. 1 atguigu atguigu 0 3月 4 01:01 1551632490229-1
-rw-rw-r--. 1 atguigu atguigu 3808 3月 4 01:02 1551632490229-2
-rw-rw-r--. 1 atguigu atguigu 538 3月 4 01:02 1551632490229-3
-rw-rw-r--. 1 atguigu atguigu 0 3月 4 01:03 1551632490229-4
-rw-rw-r--. 1 atguigu atguigu 0 3月 4 01:03 1551632490229-5
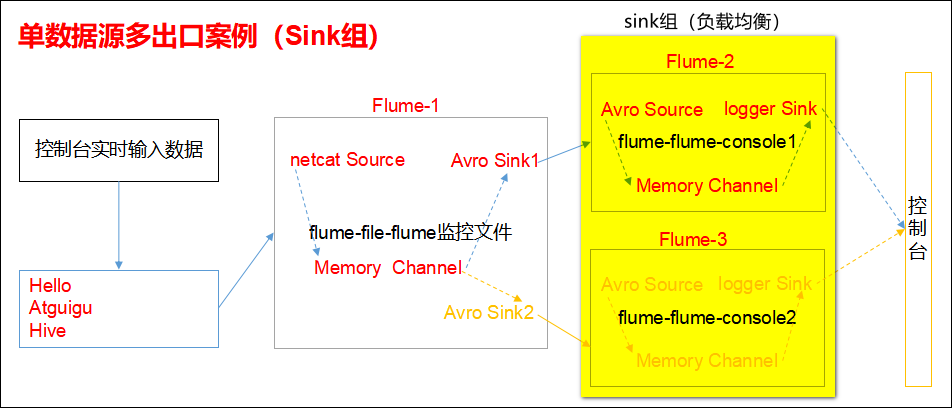
3.5 单数据源多出口案例(Sink组)
单Source、Channel多Sink(负载均衡),如下图所示。
1)案例需求:使用Flume-1监控文件变动,Flume-1将变动内容传递给Flume-2,Flume-2负责存储到HDFS。同时Flume-1将变动内容传递给Flume-3,Flume-3也负责存储到HDFS
2)需求分析:
3)实现步骤:
0.准备工作
在/opt/module/flume/job目录下创建group2文件夹
[atguigu@hadoop102 job]$ mkdir group2
[atguigu@hadoop102 job]$ cd group2/
1.创建flume-netcat-flume.conf
配置1个接收日志文件的source和1个channel、2个sink,分别输送给flume-flume-console1和flume-flume-console2。
创建配置文件并打开
[atguigu@hadoop102 group2]$ touch flume-netcat-flume.conf
[atguigu@hadoop102 group2]$ vim flume-netcat-flume.conf
添加如下内容:
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 配置sink组相关信息
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
a1.sinkgroups.g1.processor.selector.maxTimeOut=10000
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
注:Avro是由Hadoop创始人Doug Cutting创建的一种语言无关的数据序列化和RPC框架。注:RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
2.创建flume-flume-console1.conf
配置上级Flume输出的Source,输出是到本地控制台。
创建配置文件并打开
[atguigu@hadoop102 group2]$ touch flume-flume-console1.conf
[atguigu@hadoop102 group2]$ vim flume-flume-console1.conf
添加如下内容:
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = logger
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
3.创建flume-flume-console2.conf
配置上级Flume输出的Source,输出是到本地控制台。
创建配置文件并打开
[atguigu@hadoop102 group2]$ touch flume-flume-console2.conf
[atguigu@hadoop102 group2]$ vim flume-flume-console2.conf
添加如下内容:
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop102
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
4.执行配置文件
分别开启对应配置文件:flume-flume-console2,flume-flume-console1,flume-netcat-flume。
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group2/flume-flume-console2.conf -Dflume.root.logger=INFO,console
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group2/flume-flume-console1.conf -Dflume.root.logger=INFO,console
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group2/flume-netcat-flume.conf
5.使用telnet工具向本机的44444端口发送内容
$ telnet localhost 44444
6.查看Flume2及Flume3的控制台打印日志
3.6 多数据源汇总案例
多Source汇总数据到单Flume,如下图所示。
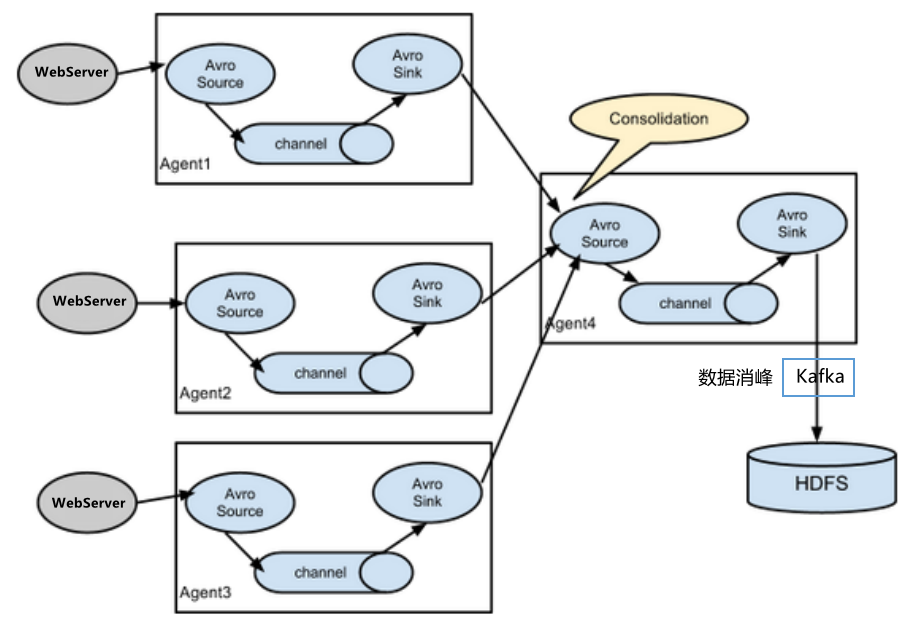
1)案例需求:
hadoop103上的Flume-1监控文件/opt/module/group.log,
hadoop102上的Flume-2监控某一个端口的数据流,
Flume-1与Flume-2将数据发送给hadoop104上的Flume-3,Flume-3将最终数据打印到控制台。
2)需求分析:
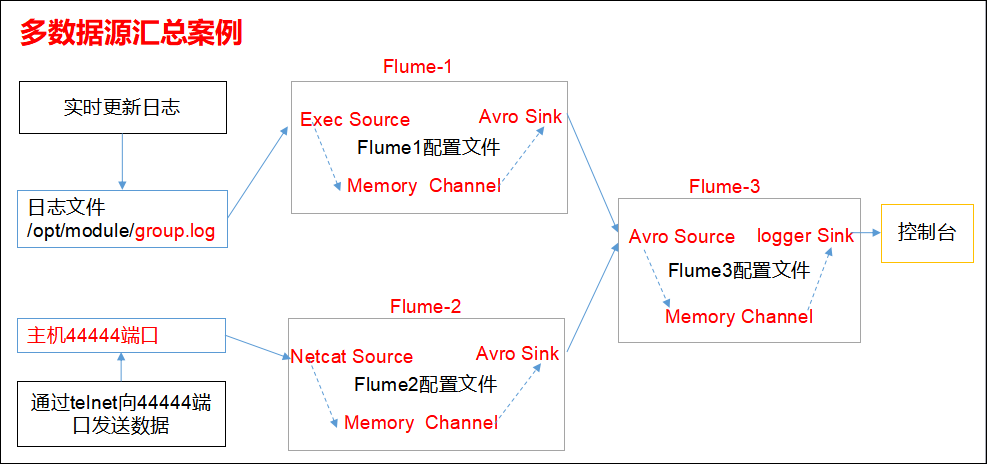
3)实现步骤:
0.准备工作
分发Flume
[atguigu@hadoop102 module]$ xsync flume
在hadoop102、hadoop103以及hadoop104的/opt/module/flume/job目录下创建一个group3文件夹。
[atguigu@hadoop102 job]$ mkdir group3
[atguigu@hadoop103 job]$ mkdir group3
[atguigu@hadoop104 job]$ mkdir group3
1.创建flume1-logger-flume.conf
配置Source用于监控hive.log文件,配置Sink输出数据到下一级Flume。
在hadoop103上创建配置文件并打开
[atguigu@hadoop103 group3]$ touch flume1-logger-flume.conf
[atguigu@hadoop103 group3]$ vim flume1-logger-flume.conf
添加如下内容:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/group.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop104
a1.sinks.k1.port = 4141
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.创建flume2-netcat-flume.conf
配置Source监控端口44444数据流,配置Sink数据到下一级Flume:
在hadoop102上创建配置文件并打开
[atguigu@hadoop102 group3]$ touch flume2-netcat-flume.conf
[atguigu@hadoop102 group3]$ vim flume2-netcat-flume.conf
添加如下内容:
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = netcat
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 44444
# Describe the sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = hadoop104
a2.sinks.k1.port = 4141
# Use a channel which buffers events in memory
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
3.创建flume3-flume-logger.conf
配置source用于接收flume1与flume2发送过来的数据流,最终合并后sink到控制台。
在hadoop104上创建配置文件并打开
[atguigu@hadoop104 group3]$ touch flume3-flume-logger.conf
[atguigu@hadoop104 group3]$ vim flume3-flume-logger.conf
添加如下内容:
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop104
a3.sources.r1.port = 4141
# Describe the sink
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
4.执行配置文件
分别开启对应配置文件:flume3-flume-logger.conf,flume2-netcat-flume.conf,flume1-logger-flume.conf。
[atguigu@hadoop104 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group3/flume3-flume-logger.conf -Dflume.root.logger=INFO,console
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group3/flume2-netcat-flume.conf
[atguigu@hadoop103 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group3/flume1-logger-flume.conf
5.在hadoop103上向/opt/module目录下的group.log追加内容
[atguigu@hadoop103 module]$ echo ‘hello‘ > group.log
6.在hadoop102上向44444端口发送数据
[atguigu@hadoop102 flume]$ telnet hadoop102 44444
7.在hadoop102上向44444端口发送数据
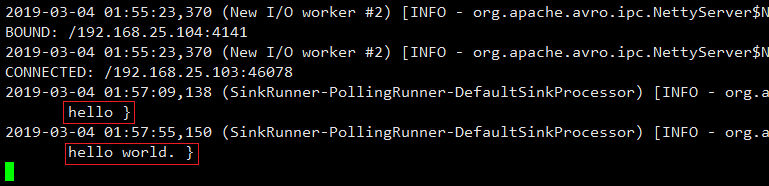
第4章 Flume监控之Ganglia
4.1 Ganglia的安装与部署
1) 安装httpd服务与php
[atguigu@hadoop102 flume]$ sudo yum -y install httpd php
2) 安装其他依赖
[atguigu@hadoop102 flume]$ sudo yum -y install rrdtool perl-rrdtool rrdtool-devel
[atguigu@hadoop102 flume]$ sudo yum -y install apr-devel
3) 安装ganglia
[atguigu@hadoop102 flume]$ sudo rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
[atguigu@hadoop102 flume]$ sudo yum -y install ganglia-gmetad
[atguigu@hadoop102 flume]$ sudo yum -y install ganglia-web
[atguigu@hadoop102 flume]$ sudo yum install -y ganglia-gmond
4) 修改配置文件/etc/httpd/conf.d/ganglia.conf
[atguigu@hadoop102 flume]$ sudo vim /etc/httpd/conf.d/ganglia.conf
修改为如下的配置:
# Ganglia monitoring system php web frontend
Alias /ganglia /usr/share/ganglia
Order deny,allow
Deny from all
Allow from all
# Allow from 127.0.0.1
# Allow from ::1
# Allow from .example.com
5) 修改配置文件/etc/ganglia/gmetad.conf
[atguigu@hadoop102 flume]$ sudo vim /etc/ganglia/gmetad.conf
修改为:
data_source "hadoop102" 192.168.25.102
6) 修改配置文件/etc/ganglia/gmond.conf
[atguigu@hadoop102 flume]$ sudo vim /etc/ganglia/gmond.conf
修改为:
cluster {
name = "hadoop102"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel {
#bind_hostname = yes # Highly recommended, soon to be default.
# This option tells gmond to use a source address
# that resolves to the machine‘s hostname. Without
# this, the metrics may appear to come from any
# interface and the DNS names associated with
# those IPs will be used to create the RRDs.
# mcast_join = 239.2.11.71
host = 192.168.25.102
port = 8649
ttl = 1
}
udp_recv_channel {
# mcast_join = 239.2.11.71
port = 8649
# bind = 239.2.11.71
bind = 192.168.25.102
retry_bind = true
# Size of the UDP buffer. If you are handling lots of metrics you really
# should bump it up to e.g. 10MB or even higher.
# buffer = 10485760
}
7) 修改配置文件/etc/selinux/config
[atguigu@hadoop102 flume]$ sudo vim /etc/selinux/config
修改为:
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
# SELINUX=enforcing
SELINUX=disabled
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
尖叫提示:selinux本次生效关闭必须重启,如果此时不想重启,可以临时生效之:
[atguigu@hadoop102 flume]$ sudo setenforce 0
5) 启动ganglia
[atguigu@hadoop102 flume]$ sudo service httpd start
[atguigu@hadoop102 flume]$ sudo service gmetad start
[atguigu@hadoop102 flume]$ sudo service gmond start
6) 打开网页浏览ganglia页面
http://192.168.25.102/ganglia尖叫提示:如果完成以上操作依然出现权限不足错误,请修改/var/lib/ganglia目录的权限:
[atguigu@hadoop102 flume]$ sudo chmod -R 777 /var/lib/ganglia
4.2 操作Flume测试监控
1) 修改/opt/module/flume/conf目录下的flume-env.sh配置:
JAVA_OPTS="-Dflume.monitoring.type=ganglia
-Dflume.monitoring.hosts=192.168.25.102:8649
-Xms100m
-Xmx200m"
2) 启动Flume任务
[atguigu@hadoop102 flume]$ bin/flume-ng agent \
--conf conf/ \
--name a1 \
--conf-file job/flume-telnet-logger.conf \
-Dflume.root.logger==INFO,console \
-Dflume.monitoring.type=ganglia \
-Dflume.monitoring.hosts=192.168.25.102:8649
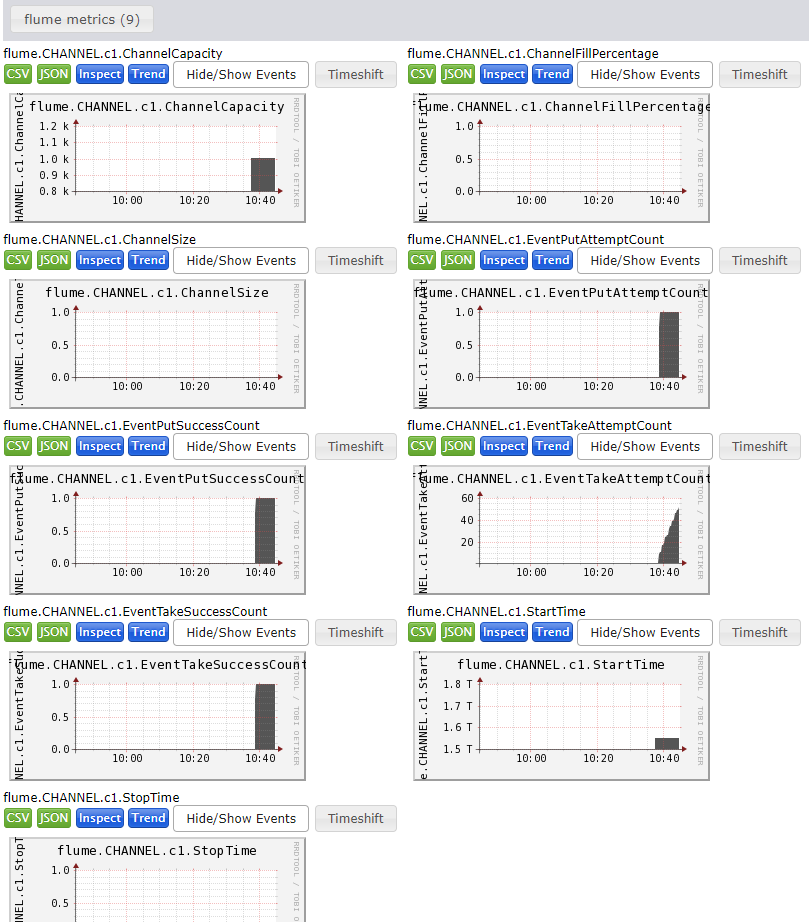
3) 发送数据观察ganglia监测图
[atguigu@hadoop102 flume]$ telnet localhost 44444
样式如图:
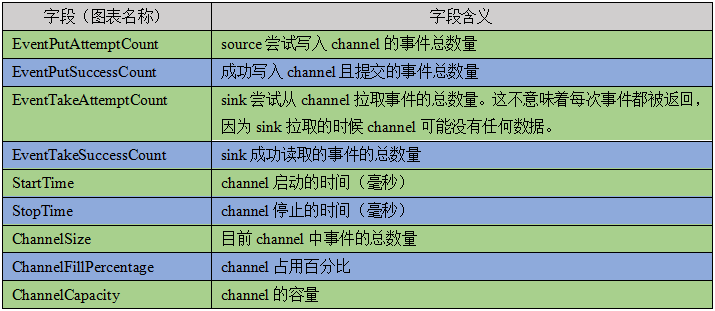
图例说明:
第5章 Flume高级之自定义MySQLSource
5.1 自定义Source说明
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。官方提供的source类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些Source。
如:实时监控MySQL,从MySQL中获取数据传输到HDFS或者其他存储框架,所以此时需要我们自己实现MySQLSource。
官方也提供了自定义source的接口:
官网说明:https://flume.apache.org/FlumeDeveloperGuide.html#source
5.2 自定义My
上一篇:PHP之异常处理的概念