Apache Hudi在医疗大数据中的应用
2021-02-14 17:19
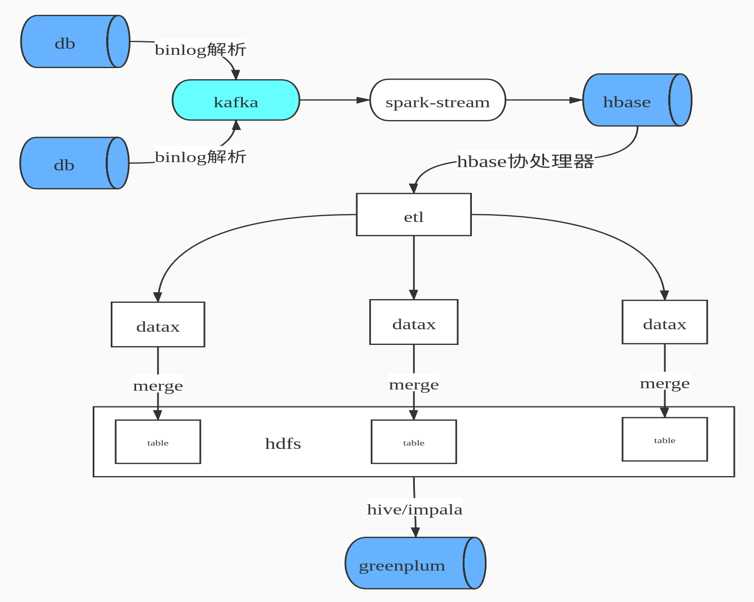
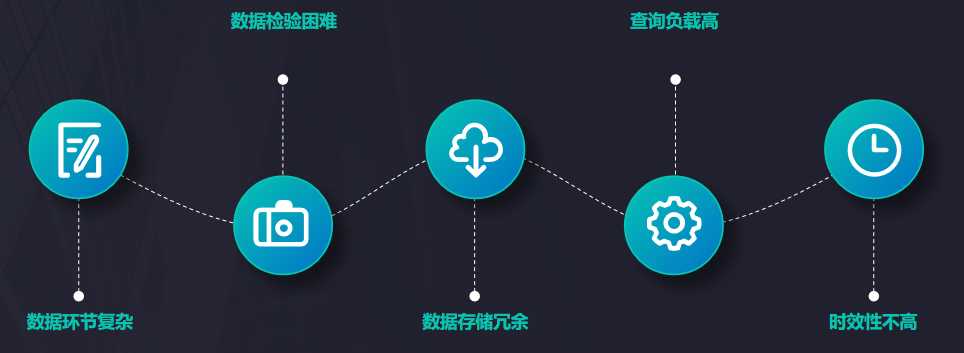
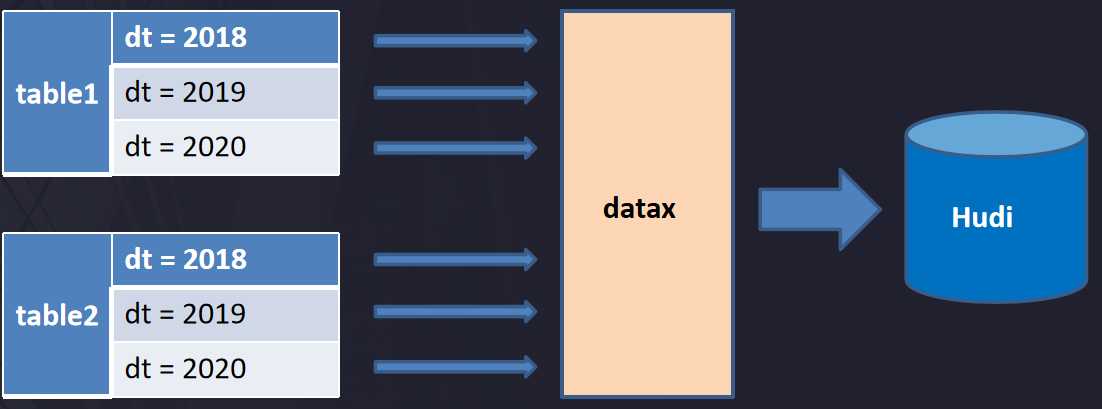
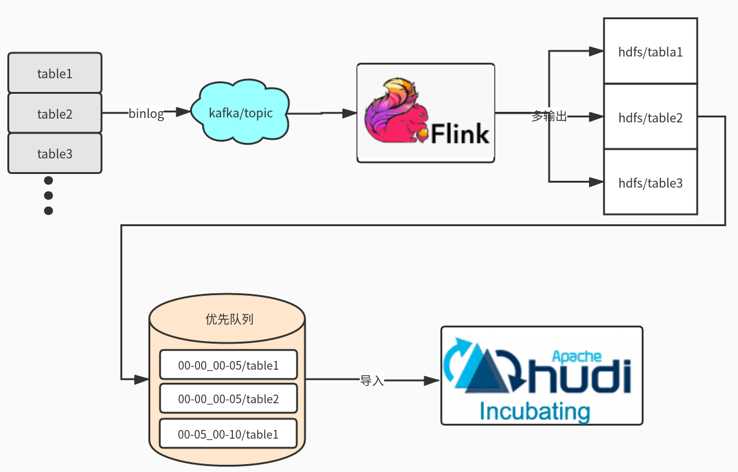
标签:建立 个数 kafka 数据流 工具 建模 hbase 疑问 问题: 本篇文章主要介绍Hudi在医疗大数据中的应用,主要分为5个部分进行介绍:1. 建设背景,2. 为什么选择Hudi,3. Hudi数据同步,4. 存储类型选择及查询优化,5. 未来发展与思考。 我们公司主要为医院建立大数据应用平台,需要从各个医院系统中抽取数据建立大数据平台。如医院信息系统,实验室(检验科)信息系统,体检信息系统,临床信息系统,放射科信息管理系统,电子病例系统等等。 在这么多系统中构建大数据平台有哪些痛点呢?大致列举如下。 我们早期的数据合并方案,如下图所示 即先通过binlog解析工具进行日志解析,解析后变为JSON数据格式发送到Kafka 队列中,通过Spark Streaming 进行数据消费写入HBase,由HBase完成数据CDC操作,HBase即我们ODS数据层。由于HBase 无法提供复杂关联查询,这对后续的数据仓库建模并不是很友好,所以我们设计了HBase二级索引来解决两个问题:1. 增量数据的快速拉取,2. 解决数据的一致性。然后就是自研ETL工具通过DataX 根据最后更新时间增量拉取数据到Hadoop ,最后通过Impala数据模型建模后写入Greenplum提供数据产品查询。 上述方案面临了如下几个问题 面对上述的问题,我们开始调研开源的实现方案,然后选择了Hudi,选择Hudi 优势如下 Hudi数据同步主要分为两个部分:1. 初始化全量数据离线同步;2. 近实时数据同步。 离线同步方面:主要是使用DataX根据业务时间多线程拉取,避免一次请求过大数据和使用数据库驱动JDBC拉取数据慢问题,另外我们也实现多种datax 插件来支持各种数据源,其中包括Hudi的写入插件。 近实时同步方面:主要是多表通过JSON的方式写入Kafka,在通过Flink多输出写入到Hdfs目录,Flink会根据binlog json的更新时间划分时间间隔,比如0点0分到0点5分的数据在一个目录,0点5分到0点10分数据一个目录,根据数据实时要求选择目录时间的间隔。接着通过另外一个服务轮询监控Hdfs是否有新目录生成,然后调用Hudi Merge脚本任务。运行任务都是提交到线程池,可以根据集群的资源调整并合并的数量。 这里可能大家有疑问,为什么不是Kafka 直接写入Hudi ?官方是有这样例子,但是是基于单表的写入,如果表的数据多达上万张时怎么处理?不可能创建几万个Topic。还有就是分流的时候是无法使用Spark Write进行直接写入。 我们根据自身业务场景,选择了Copy On Write模式,主要出于以下两个方面考虑。 关于使用Spark SQL查询Hudi也还是SQL拆分和优化、设置合理分区个数(Hudi可自定义分区可实现上层接口),提升Job并行度、小表的广播变量、防止数据倾斜参数等等。 关于使用Presto查询测试比Spark SQL要快3倍,合理的分区对优化非常重要,Presto 不支持Copy On Write 增量视图,在此基础我们修改了hive-hadoop2插件以支持增量模式,减少文件的扫描。 离线同步接入类似于FlinkX框架,有助于资源统一管理。FlinkX是参考了DataX的配置方式,把配置转化为Flink 任务运行完成数据的同步。Flink可运行在Yarn上也方便资源统一管理。 Spark消费可以支持多输出写入,避免需要落地Hdfs再次导入。这里需要考虑如果多表传输过来有数据倾斜的问题,还有Hudi 的写入不仅仅只有Parquert数据写入,还包括元数据写入、布隆索引的变更、数据合并逻辑等,如果大表合并比较慢会影响上游的消费速度。 Flink对Hudi的支持,社区正在推进这块的代码合入。 更多参与社区,希望Hudi社区越来越好。 Apache Hudi在医疗大数据中的应用 标签:建立 个数 kafka 数据流 工具 建模 hbase 疑问 问题: 原文地址:https://www.cnblogs.com/leesf456/p/12990274.html1. 建设背景

2. 为什么选择Hudi
3. Hudi 数据同步
4. 存储类型选择及查询优化
5. 未来发展与思考
上一篇:kubernetes系列之 service代理模式ipvs
下一篇:Typora+PicGo-Core(command line)+SMMS、github、gitee实现Typora图片上传到图床
文章标题:Apache Hudi在医疗大数据中的应用
文章链接:http://soscw.com/index.php/essay/55274.html