别人用钱,而我用python爬虫爬取了一年的4K高清壁纸
2021-02-14 19:22
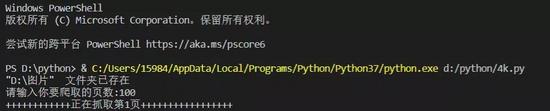
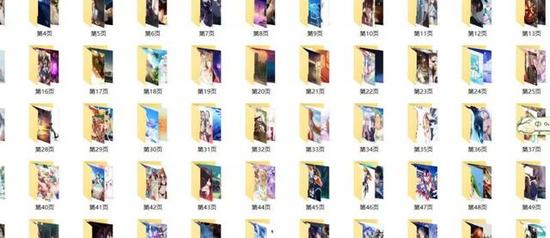
标签:ast requests inline 是什么 浏览器 版本 python模块 箭头 解释 本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。 网络爬虫,也叫网络蜘蛛(Web Spider)。它根据网页地址(URL)爬取网页内容,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。说简单点就是模拟人去获得网页上的资源。网页地址(URL)就是我们在浏览器中输入的网站链接,它的专业术语是:统一资源定位符。 在讲解爬虫内容之前,我们来讲一下抓包过程(packet capture):•在此我们以这个壁纸网站为例URL:http://pic.netbian.com/•这是一个4k高清壁纸网站,里面的资源很多,我们用浏览器打开url,进入页面后,在键盘上按下F12会打开开发者工具,如图: 这这里我们会看到一大堆代码,这些代码就是HTML,HTML就像是我们人的身体,它负责这个网页上会出现什么东西,就比如身边负责我们的样貌。通过查找和调试,可以找出我们所需要的数据,比如这里我们需要找到图片的下载地址,为什么要找图片下载地址呢?因为在这个网站上下载图片需要登入账号,而且每个账号每天只能下载一次。但是我们可以通过爬虫,突破限制,从而能够下载图片。 我们点击开发者工作最左边的箭头,然后鼠标找点击图片,我们可以看到开发者工具那里的代码指向了图片的位置,我们可以从这里发现这里这个位置上面有一个a href="http://www.soscw.com/tupian/25761.html’的标签,可以看出这个就是图片的地址,该地址是:URL+/tupian/25761.html 我们是去试一下,在浏览器地址栏输入该地址-回车,可以看到图片出现来,我们猜想的不错,图片的地址就是:URL+href后面的链接。 接下来我们就可以进行对图片的爬取了! Python和第三方模块的安装 在学习爬虫前我们去要去安装Python[1],找寻安装自己电脑所对应的的Python版本,安装完成以后,按下win+R打开cmd进入DOS窗口输入下面的命令进行requests模块和lxml模块的安装: 在进入正题之前,我先来讲解下 requests 库常用的方法: lxml是干什么的?简单的说来,lxml是帮助我们解析HTML、XML文件,快速定位,搜索、获取特定内容的Python模块。lxml也是对网页内容解析的一个模块。 请大家在爬取图片的过程中,尽量少下载点图片,不然其服务器会崩溃的!•代码的解释,我都在源码里注释了,大家照着注释应该都能看懂,明白! 上源码! 运行程序 输入页数,我这里输入的是100,意思就是爬取100页的所以图片并全部下载。 接着我们再来我们我爬取完后以后的结果,如图: 可以看到这里是全部都下载成功了哦! 别人用钱,而我用python爬虫爬取了一年的4K高清壁纸 标签:ast requests inline 是什么 浏览器 版本 python模块 箭头 解释 原文地址:https://www.cnblogs.com/7758520lzy/p/12719891.html
?
前言

爬虫是什么?
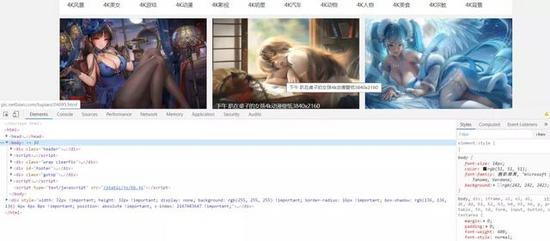
?
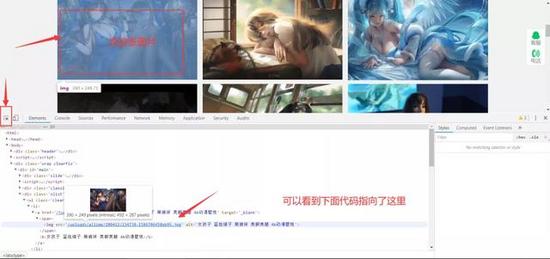
?

?
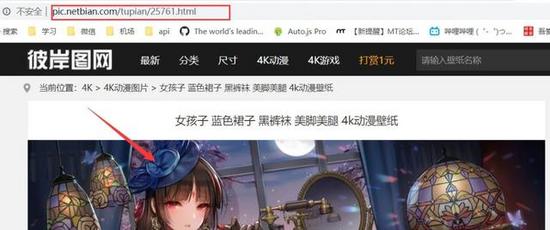
?

?
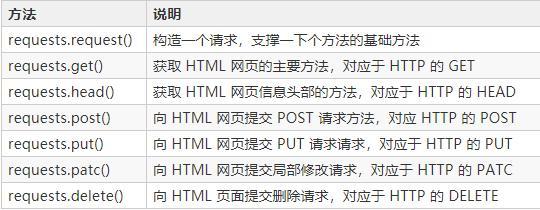
?
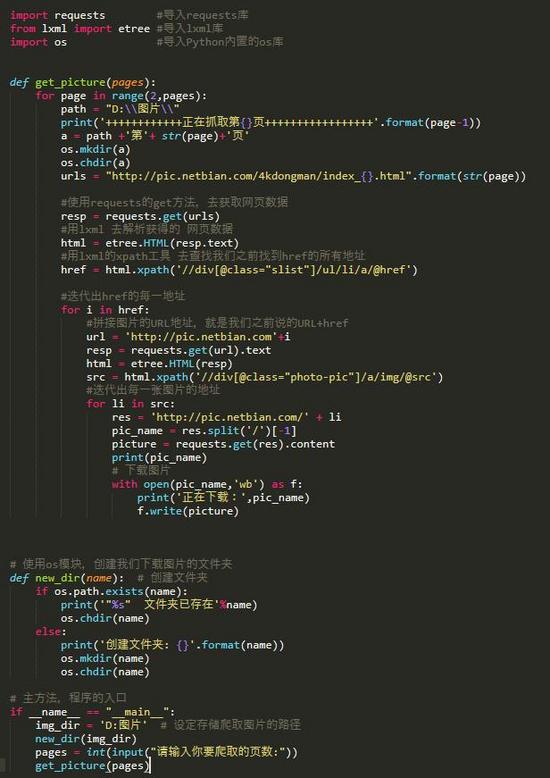
Python代码
?
?
?
文章标题:别人用钱,而我用python爬虫爬取了一年的4K高清壁纸
文章链接:http://soscw.com/index.php/essay/55318.html