小样本元学习综述:A Concise Review of Recent Few-shot Meta-learning Methods
2021-02-14 20:18
标签:embedding actor HERE sig 完整 arc guid review 综述 原文链接 小样本学习与智能前沿 。 在这个公众号后台回复‘CRR-FMM‘,即可获得电子资源。 In this short communication, we present a concise review of recent representative meta- learning methods for few-shot image classification. We re- fer to such methods as few-shot meta-learning methods. Af- ter establishing necessary notation, we first mathematically formulate few-shot learning and offer a pseudo-coded algo- rithm for general few-shot training and evaluation. We then provide a taxonomy and a gentle review of recent few-shot meta-learning methods, to help researchers quickly grasp the state-of-the-art methods in this field. Finally we summa- rize some vital challenges to conclude this review with new prospects. 完整的mindmap:https://note.youdao.com/ynoteshare1/index.html?id=3cf041f5616d34bb4677d03434531c92&type=note A good learner should not only extract sufficient transferable knowledge among tasks but also fast adapt to novel tasks. Hence, in general, a few-shot meta-learning algorithm usu- ally consists of two components, a meta-learner component and a task-specific learner component. What to share, how to share and when to share are three components at the heart of few-shot meta-learning. For example, embedding layers are often shared in a rigid manner (e.g. [2]) in fine-tuning; parameters optimized on the base dataset can be regarded as a good initialization (e.g. [4, 5]), for fast further learning conditional on few labeled samples from novel classes; and auxiliary information also helps few-shot learning, e.g. attribute annotations related to images [30]. In addition to standard few-shot episodes defined by ?? -way ?? -shot, other episodes can also be used as long as they do not poison the evaluation in meta- validation or meta-testing In this section, we give a general few-shot episodic train- ing/evaluation guide in Algorithm 1 For few-shot meta-learning, we can al- ways design a deep neural network ???? parametrized by ?? as the classifier: we denote it as ???? (?|\(S^*\), \(D_{base}\)), where \(S^*\) is some support set. Note that in our notation \(S^*\)can also be a support set on the base classes \(C_{base}\) or even the whole base dataset \(D_{base}\), corresponding to the cases of meta-training or pre- training, respectively. For few-shot classification problems, e.g., ??-way ??- shot classification, the performance of a learning algorithm is measured by its averaged accuracy on the query sets of the tasks generated on the novel dataset \(D_{novel}\) (i.e., the 15th line of Algorithm 1). The meta-learner component is to learn transferable prior knowledge from the base dataset \(D_{base}\). The existing few-shot meta-learning methods can be categorized into four branches according to their technical characteristics: The under- lying rationale is that the task-specific parameters are close to this shared global initialization for all the tasks generated from \(D_{base}\) and \(D_{novel}\). It can be interpreted and executed in the following two ways in recent few-shot meta-learning methods: MAML: the algorithm seeks to update the task-specific parameters and the global initialization jointly in an iterative manner. Either of these baseline and Baseline++ neural networks can be decom-posed into two parts: In [2],at the fine-tuning stage, they only keep the learned embedding part and set up a new classifier fit for the ?? -way ?? -shot problems on tasks generated from \(D_{novel}\). a linear mapping layer and a softmax activation function. The standard baseline method only learns the parameters of the linear mapping at the fine-tuning stage; a modified base- line method replaces the linear mapping layer by a layer that computes cosine distance between each image’s deep representation and the learned parameters of the linear mapping layer (learned at the fine-tuning stage). Tokmakov et al. [30] .The proposed neural net- work is firstly trained on the base dataset \(D_{base}\), and then fine-tuned with those additional regularization terms condi- tional on the labeled images from each novel task. The second branch focuses on rapid generation of parameters of task-specific neural networks from a meta-learner. Munkhdalai and Yu [16]: The meta-learner is used to perform fast parameter generation for itself and the base-learner by minimizing both the representation loss and task loss across various tasks with an attention mechanism. Fast parameter generation is achieved by MetaNet through learning the distribution of func- tional parameters of task-specific Matching Networks condi- tional on support sets of tasks. Gidaris and Komodakis [6]:This is achieved by combining an attention- based classification weight generator and a cosine-based con- volution classifier which allows to learn both base and novel classes even at the testing stage. Ren et al. [21] :The whole training includes two stages. On Mini-ImageNet, the MTL achieves the state-of-the-art per- formance, for 5-way 1-shot classification. Ravi and Larochelle [20] :Their main contribution is to represent parameter optimization of a task-specific classifier by the evolution of LSTM’s cell states. Their work also uses a standard episodic meta training/evaluation as in Algorithm 1. Mishra et al. [15] proposed a class of generic meta-learner architectures, called simple neural attentive learner (SNAIL), that combined temporal convolu- tions and soft attention for leveraging information from past episodes and for pinpointing specific pieces of information, respectively. Munkhdalai et al. [17] proposed a neural mechanism, conditional shifted neurons (CSNs), which was capable of extracting conditioning information and producing condi- tional shifts for prediction in the process of meta-learning, and could be further incorporated into CNNs and RNNs. The main challenge of few-shot learning is the deficiency of samples. when a few- shot meta-learning algorithm has uneven performance on a series of tasks, the knowledge learned by the meta-learner can lead to large uncertainty in performance for novel tasks from unseen classes [10]. it remains vital for us to develop a feature extractor for task- specific learners that learns more discriminative features from only one or few labeled images. Inpractice,\(D_{base}\) and \(D_{novel}\) can be from different domains; such classification problems demand cross-domain few-shot learners. If a meta-leaner can learn transferable knowledge from \(D_{base}\) consisting of multi-domain data, the meta-learner will be expected to have better gener- alization ability. [2] Chen, W.Y., Liu, Y.C., Kira, Z., Wang, Y.C.F., Huang, J.B., 2019. A closer look at few-shot classification, in: International Conference on Learning Representations. 小样本元学习综述:A Concise Review of Recent Few-shot Meta-learning Methods 标签:embedding actor HERE sig 完整 arc guid review 综述 原文地址:https://www.cnblogs.com/joselynzhao/p/12990796.html

1 Introduction
MindMap
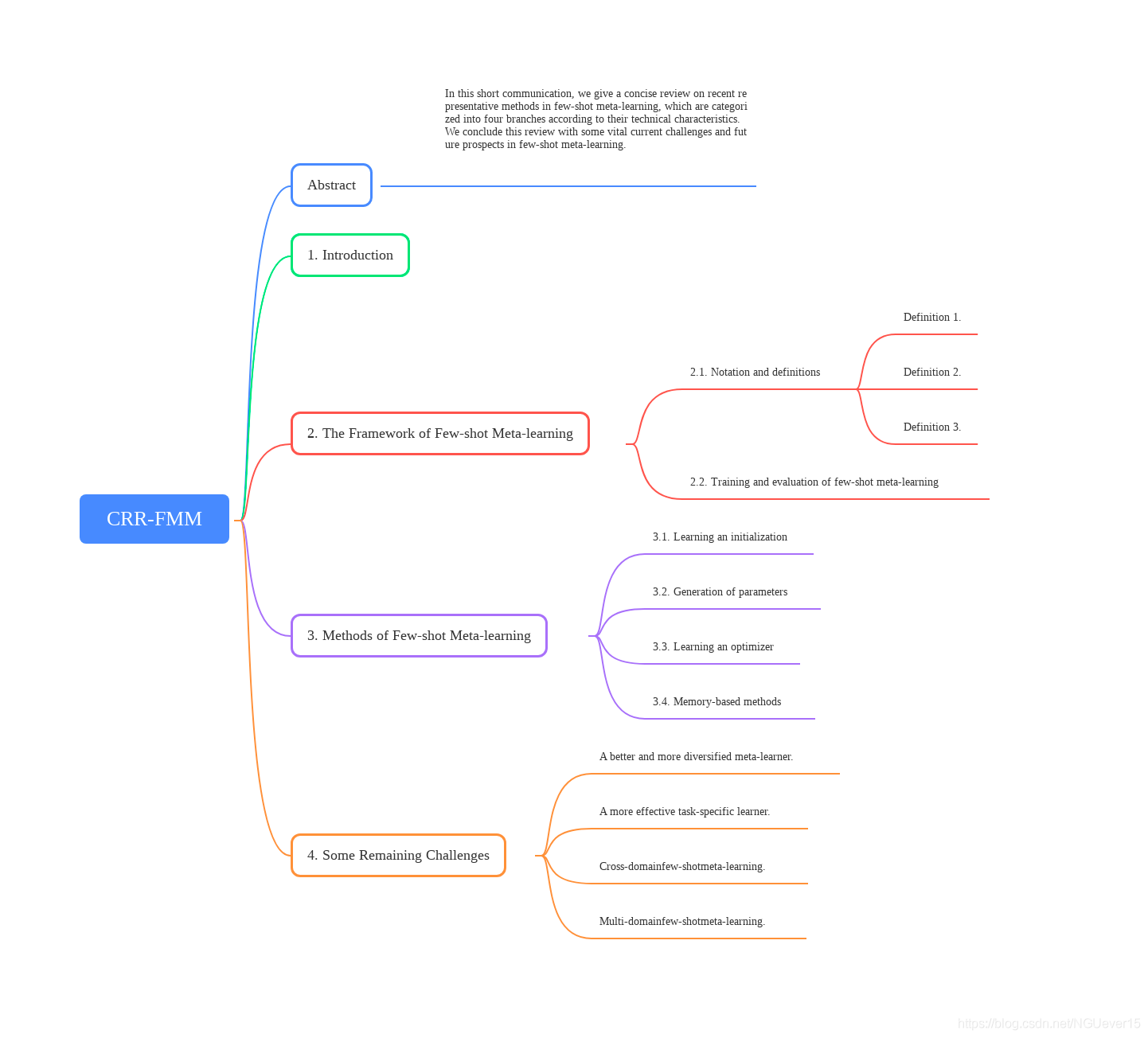
2. The Framework of Few-shot Meta-learning
2.1. Notation and definitions
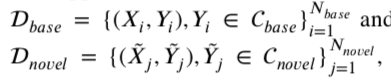
A classifier ?? is expected to correctly discriminate query images Q conditional on the small-size labeled support images SDefinition 1. (Small-sample learning)

Definition 2. (Few-shot learning)

Definition 3. (Few-shot meta-learning)


2.2. Training and evaluation of few-shot meta-learning



3. Methods of Few-shot Meta-learning
3.1. Learning an initialization
TAML:which aims to train an initial model that is unbiased to all tasks.
TAML achieves the state-of-the-art performance in 5-way 1-shot and 5-way 5-shot classification on the Onimiglot dataset.
3.2. Generation of parameters
A pre-training stage is to learn a good representation and so- called slow weights (??????????) of the top fully connected layer of the classifier. Then, an incremental few-shot episodic training is designed to increment novel classes into training via an episodic style.3.3. Learning an optimizer
3.4. Memory-based methods
4. Some Remaining Challenges
Parameter-generation based meth- ods solve this problem by directly generating the parame-ters of the task-specific learner to mitigate the difficulty of training on novel data.A better and more diversified meta-learner.
Apart from the existing few- shot meta-learning methods, meta-learning methods with di- versified emphases, such as learning a suitable loss function or learning a network structure, will also be valuable to ex- plore.A more effective task-specific learner.
Thus, it is important that task-specific learners are built on the loss functions that can ensure the robustness and performance of models.Cross-domain few-shot meta-learning.
Therefore, it merits further exploration on cross-domain few-shot meta-learning.Multi-domain few-shot meta-learning.
Reference
[15] Mishra, N., Rohaninejad, M., Chen, X., Abbeel, P., 2018. A simple neural attentive meta-learner, in: International Conference on Learn- ing Representations.
[17] Munkhdalai, T., Yuan, X., Mehri, S., Trischler, A., 2018. Rapid adap- tation with conditionally shifted neurons, in: International Confer- ence on Machine Learning, pp. 3661–3670.
[20] Ravi, S., Larochelle, H., 2017. Optimization as a model for few-shot learning, in: International Conference on Learning Representations.
[27] Sun,Q.,Liu,Y.,Chua,T.S.,Schiele,B.,2019.Meta-transferlearning
for few-shot learning, in: IEEE Conference on Computer Vision and
Pattern Recognition, pp. 403–412.
文章标题:小样本元学习综述:A Concise Review of Recent Few-shot Meta-learning Methods
文章链接:http://soscw.com/index.php/essay/55328.html