K均值算法
2021-02-15 13:23
标签:k均值聚类 分析 range get 数据对象 ase legend 完整 src 1. 机器学习的步骤 数据,模型选择,训练,测试,预测 2. 安装机器学习库sklearn pip list 查看版本 python -m pip install --upgrade pip pip install -U scikit-learn pip uninstall sklearn pip uninstall numpy pip uninstall scipy pip install scipy pip install numpy pip install sklearn https://scikit-learn.org/stable/install.html 2. 导入sklearn的数据集 from sklearn.datasets import load_iris iris = load_iris() iris.keys() X = iris.data # 获得其特征向量 y = iris.target # 获得样本标签 iris.feature_names # 特征名称 3.K均值算法 K-means是一个反复迭代的过程,算法分为四个步骤: (x,k,y) 1) 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心; def initcenter(x, k): kc 2) 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类; def nearest(kc, x[i]): j def xclassify(x, y, kc):y[i]=j 3) 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值; def kcmean(x, y, kc, k): 4) 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)。 while flag: y = xclassify(x, y, kc) kc, flag = kcmean(x, y, kc, k) 参考官方文档: http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans 4. 作业: 1). 扑克牌手动演练k均值聚类过程:>30张牌,3类 本人抽取了如上30张牌,一开始以3,4,5作为聚类中心,最终结果如上图所示,最终中心为2,6,j(12)。 2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题) 3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示. 2,3题都用了鸢尾花的花瓣数据做了聚类,效果图也如上二图所示,黑点为聚类中心,可以看出较好的吻合。 4). 鸢尾花完整数据做聚类并用散点图显示. 利用鸢尾花的完整数据进行聚类分析,与实际的分类做出比较后如上图所示,第一第二聚类比较好,第三个聚类较不准确。 5).想想k均值算法中以用来做什么? 1、给机器识别物种 K均值算法 标签:k均值聚类 分析 range get 数据对象 ase legend 完整 src 原文地址:https://www.cnblogs.com/ccla/p/12711488.html
import numpy as np
from sklearn.datasets import load_iris
import random
import matplotlib.pylab as plt
#(1)定义计算欧几里得距离函数。
def jl(data1,data2):
return np.sqrt(sum((data1-data2)**2))
#(2)构建k个随机质心。
def sjcenter(k,data):
sjksz=[]
newdata=[]
for i in range(k):
sjk = random.randint(0, len(data)-1)
if sjk not in sjksz:
sjksz.append(sjk)
newdata.append(data[sjk,:])
else:
i=i-1;
return newdata
#(3)定义K-means函数实现算法。
def Kmeans(k,data,center):
n = len(data)
dist = np.zeros([n, k + 1])
newCenter = np.zeros([k, data.shape[1]])
while True:
for i in range(n):
for j in range(k):
dist[i, j] = jl(data[i],center[j])
dist[i, k] = np.argmin(dist[i, :k])
for i in range(k):
index = dist[:, k] == i
newCenter[i, :] = data[index, :].mean(axis=0)
if (np.all(center == newCenter)):
break
else:
center = newCenter
return dist
#(4)主函数中调用上述4个函数实现K-means算法,并绘制数据散点图查看聚类中心。
def main(k,data):
center = sjcenter(k, data)
dist=Kmeans(k,data,center)
plt.scatter(data[:, 0], data[:, 1], c=dist[:,k], s=50, cmap=‘rainbow‘)
#类中心用黑点标出
for i in range(k):
plt.scatter(center[i][0],center[i][1],color=‘#000000‘)
plt.show()
iris=load_iris()
main(3,iris.data[:,2:4])
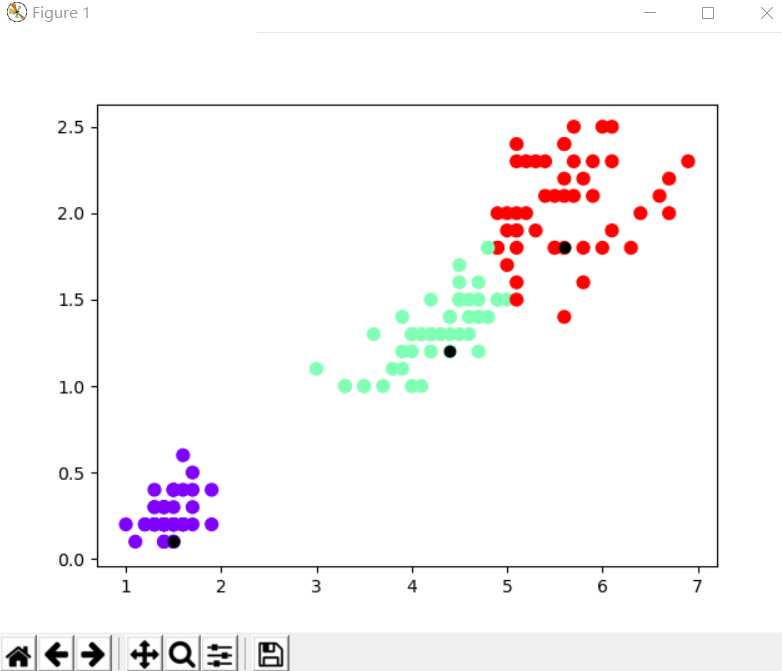
#(1)直接调用sklearn库实现对鸢尾花数据进行聚类分析。
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pylab as plt
iris=load_iris()
data=iris.data[:,2:4]
model=KMeans(n_clusters=3).fit(data)
model.labels_
model.cluster_centers_
plt.scatter(data[:,0],data[:,1],c=model.labels_,s=50,cmap=‘rainbow‘)
for i in range(3):
plt.scatter(model.cluster_centers_[i][0], model.cluster_centers_[i][1], color=‘#000000‘)
plt.show()
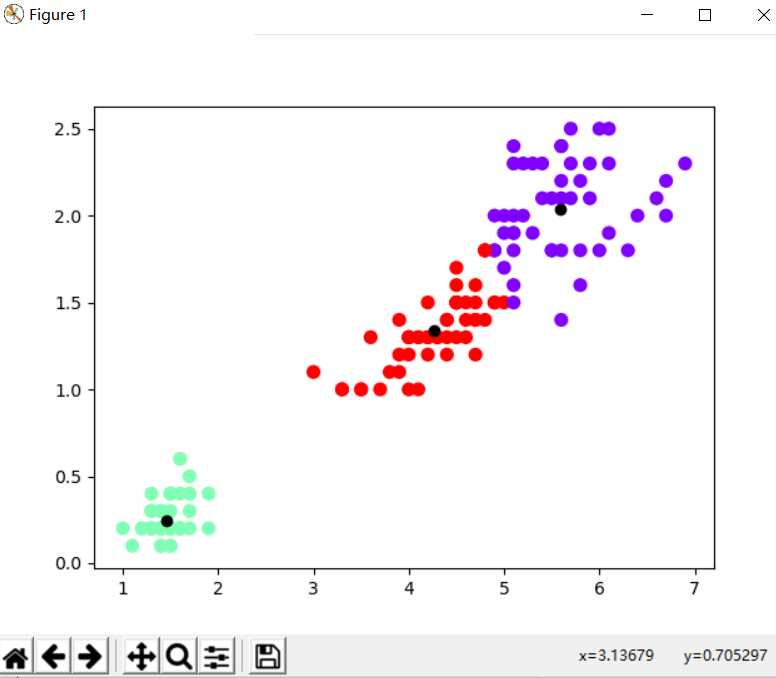
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pylab as plt
iris=load_iris()
data=iris.data
target=iris.target
model=KMeans(n_clusters=3).fit_predict(data)
model
target_test=model
for i in range(150):
if target_test[i]==1:
target_test[i]=0
elif target_test[i]==0:
target_test[i]=1
plt.plot(range(150), target_test)
plt.plot(range(150), target)
plt.legend([‘forecast‘,‘real‘])
plt.show()
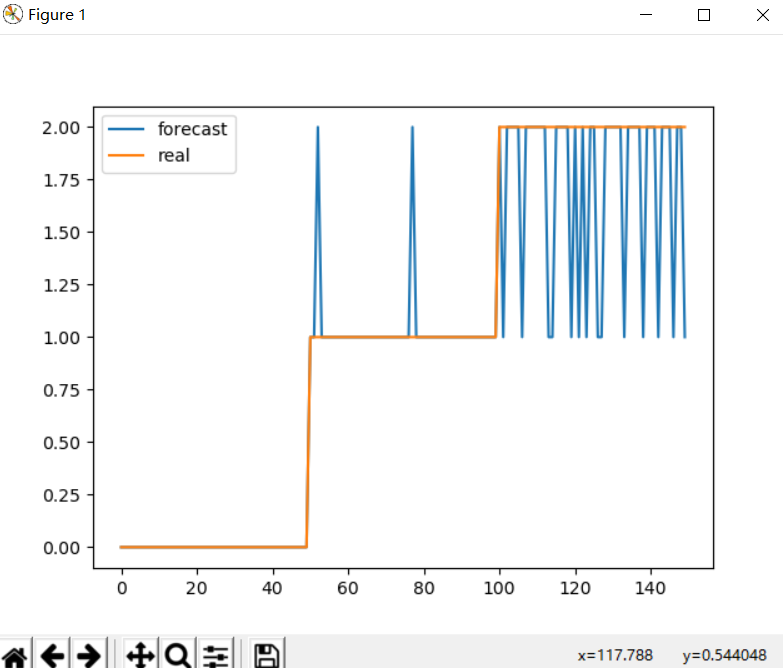
2、预测人习惯爱好