unicode 查询网站 分析 getBytes 的问题
2021-02-15 21:20
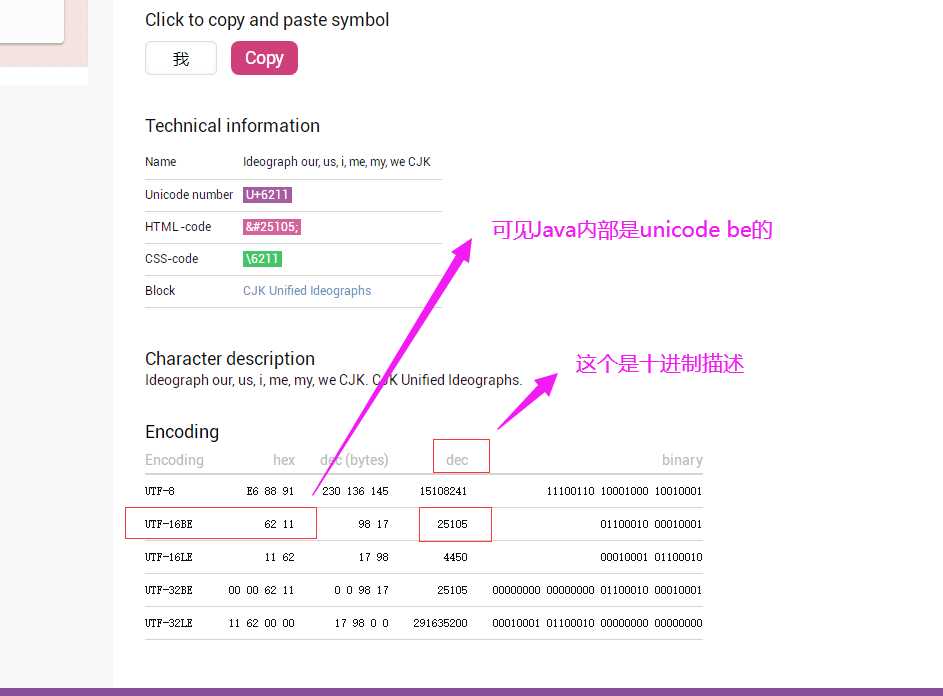
标签:rop rar 参与者 length 世界 tps 属性 字符 fse ------------恢复内容开始------------ 1. 查询网站:https://unicode-table.com 举例: 1. 首先 Java 里的 char是 unicode char ,即有内码和外码之分,外码如.java .class文件 外码可以 utf-8编码,但内码一定是 unicode ,即 jvm在加载 .class文件时,会按UTF-8来加载,但是运行时还是按unicode来运行。 ====================================================================== 参见:https://ask.csdn.net/questions/190147 再来一篇详细的:https://blog.csdn.net/java2000_net/article/details/3047001 还有:https://bbs.csdn.net/topics/270062448 ======================================================================================================== unicode 查询网站 分析 getBytes 的问题 标签:rop rar 参与者 length 世界 tps 属性 字符 fse 原文地址:https://www.cnblogs.com/del88/p/12979920.html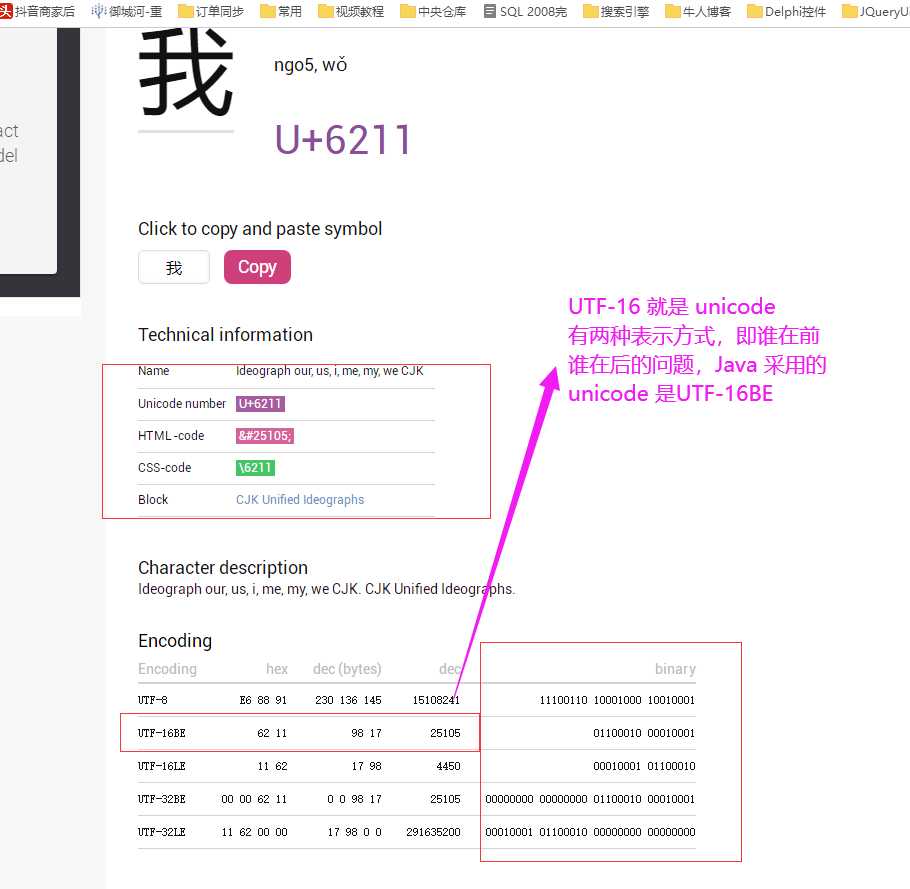
public class TestUnicode {
public static void main(String[] args) throws UnsupportedEncodingException {
String abc = "我";
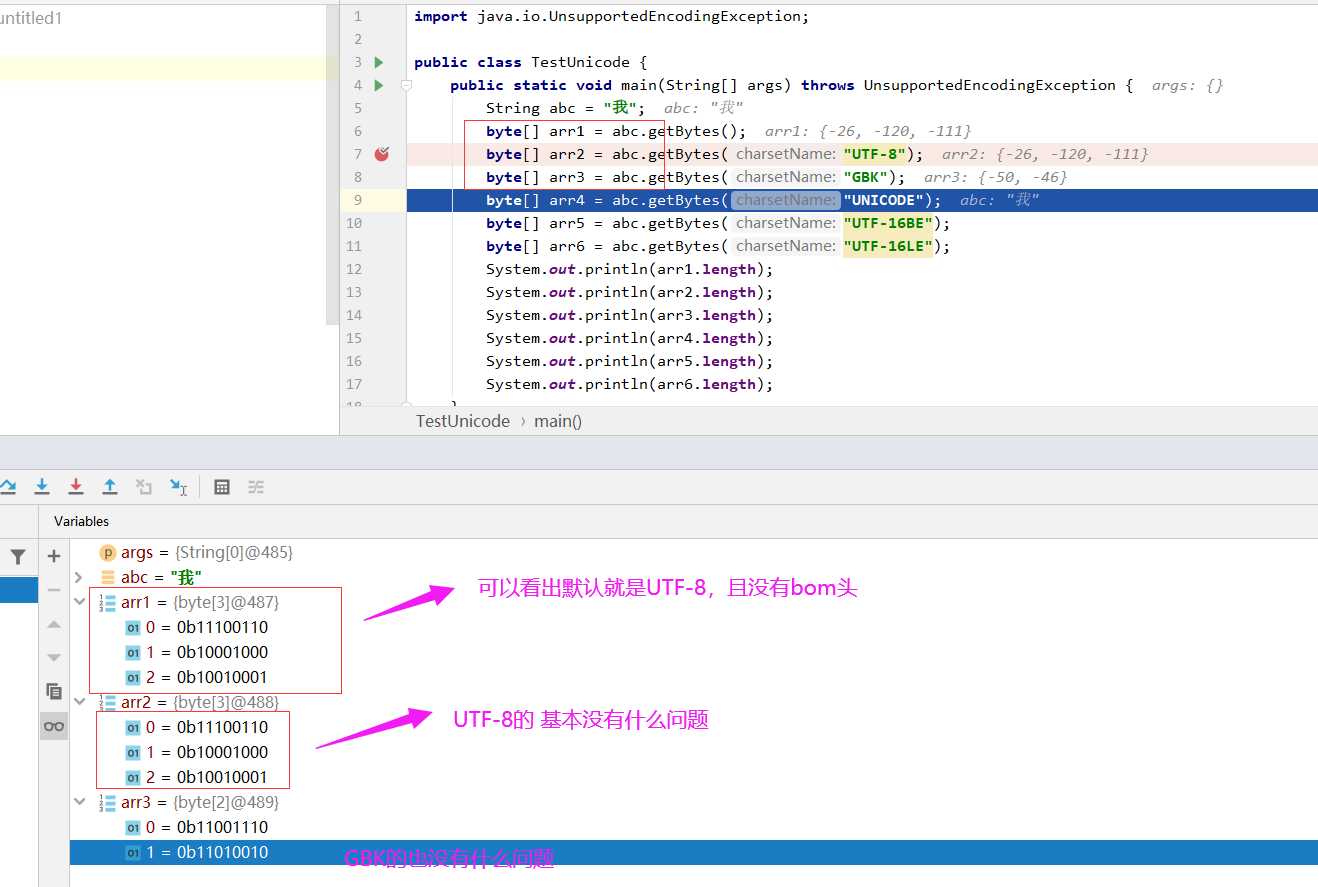
byte[] arr1 = abc.getBytes();
byte[] arr2 = abc.getBytes("UTF-8");
byte[] arr3 = abc.getBytes("GBK");
byte[] arr4 = abc.getBytes("UNICODE");
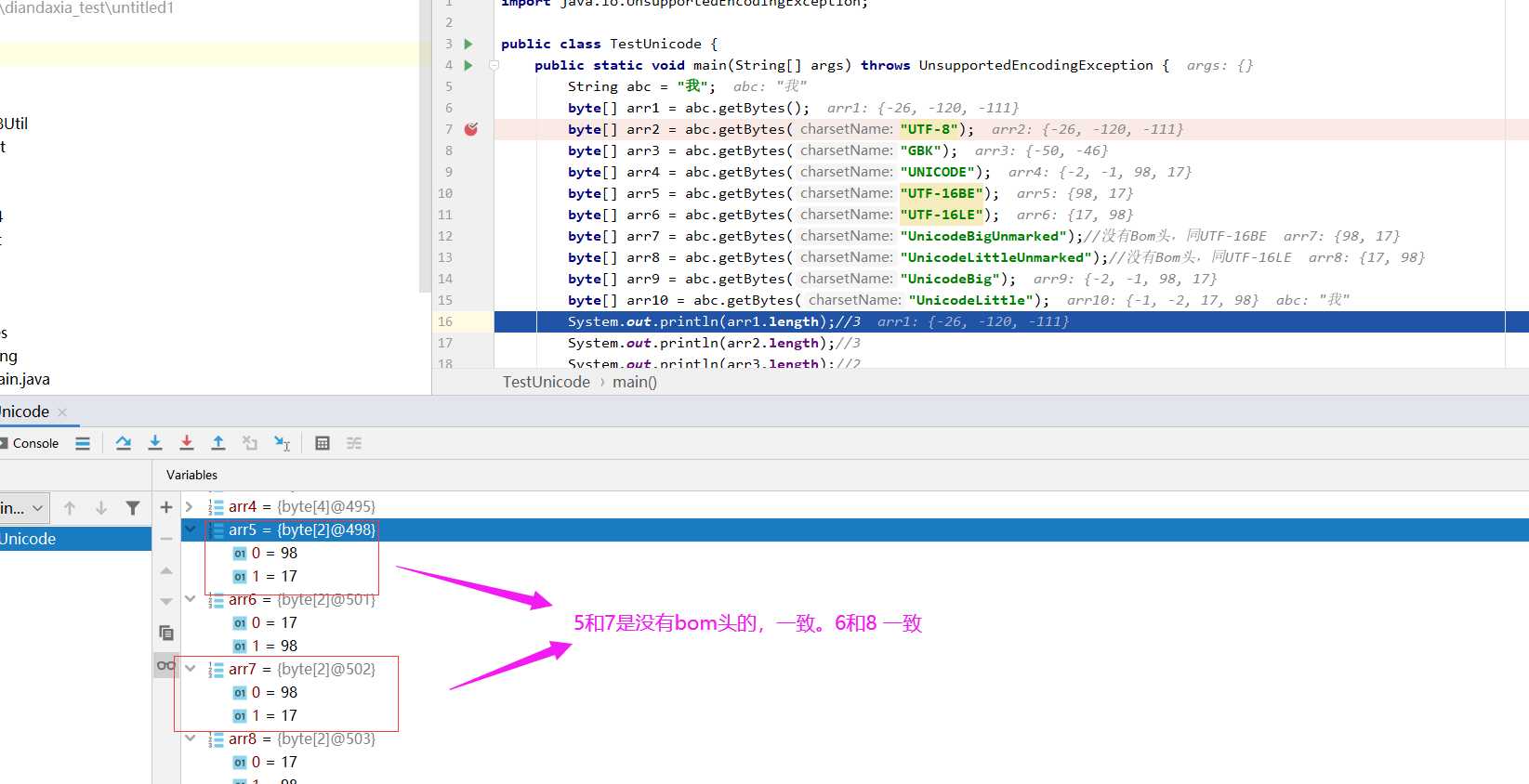
byte[] arr5 = abc.getBytes("UTF-16BE");
byte[] arr6 = abc.getBytes("UTF-16LE");
byte[] arr7 = abc.getBytes("UnicodeBigUnmarked");//没有Bom头,同UTF-16BE
byte[] arr8 = abc.getBytes("UnicodeLittleUnmarked");//没有Bom头,同UTF-16LE
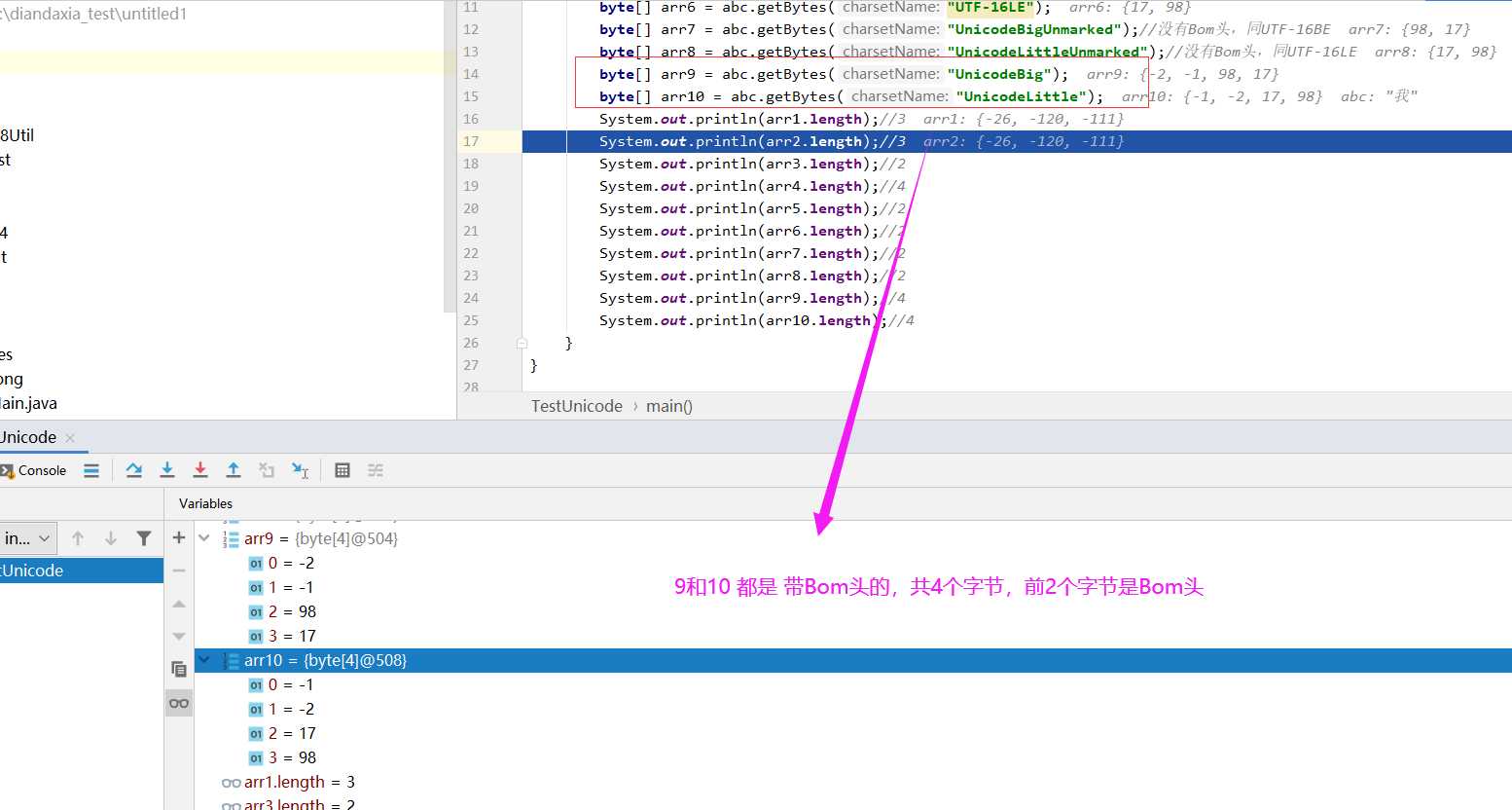
byte[] arr9 = abc.getBytes("UnicodeBig");
byte[] arr10 = abc.getBytes("UnicodeLittle");
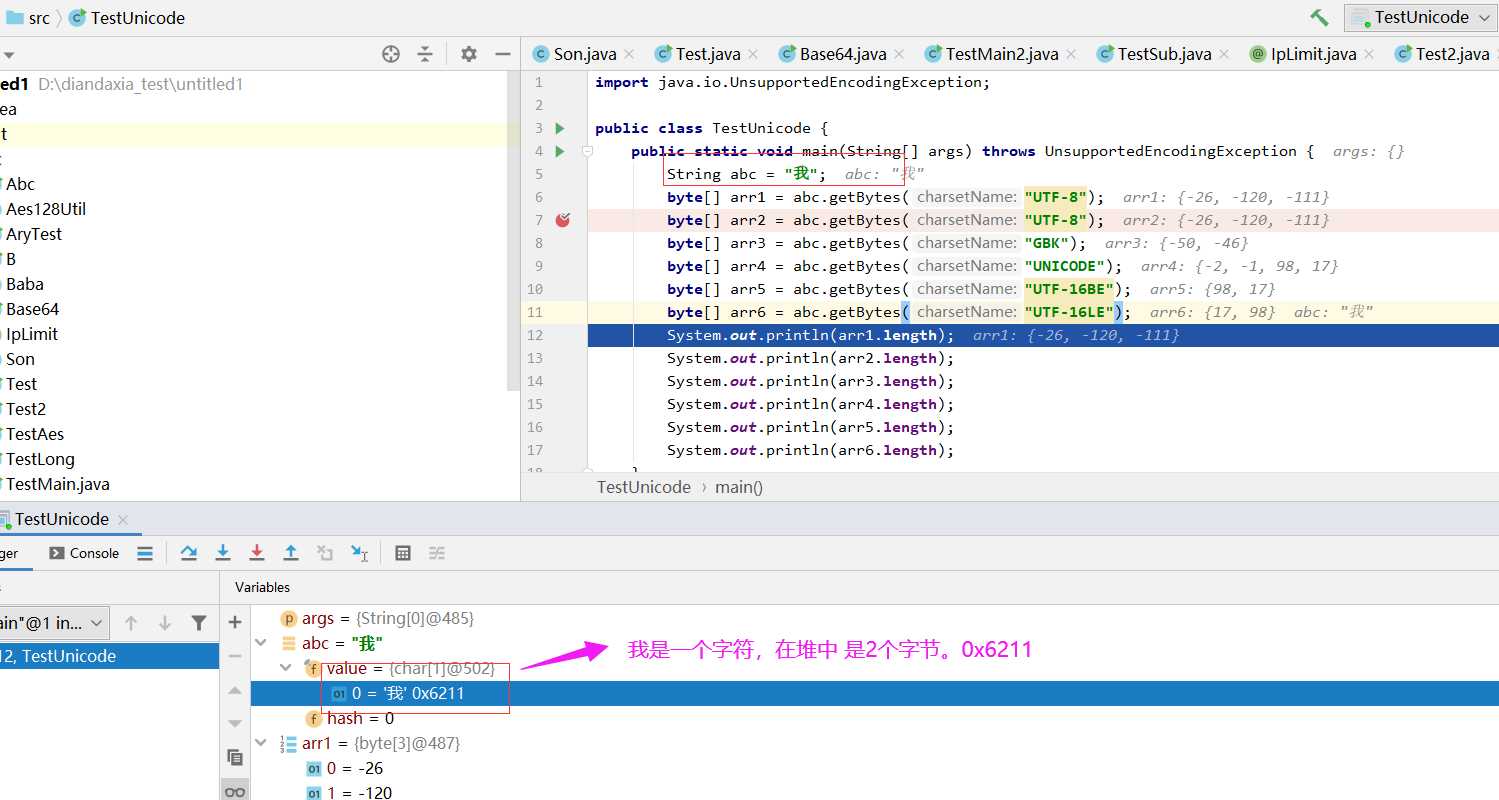
System.out.println(arr1.length);//3
System.out.println(arr2.length);//3
System.out.println(arr3.length);//2
System.out.println(arr4.length);//4
System.out.println(arr5.length);//2
System.out.println(arr6.length);//2
System.out.println(arr7.length);//2
System.out.println(arr8.length);//2
System.out.println(arr9.length);//4
System.out.println(arr10.length);//4
}
}
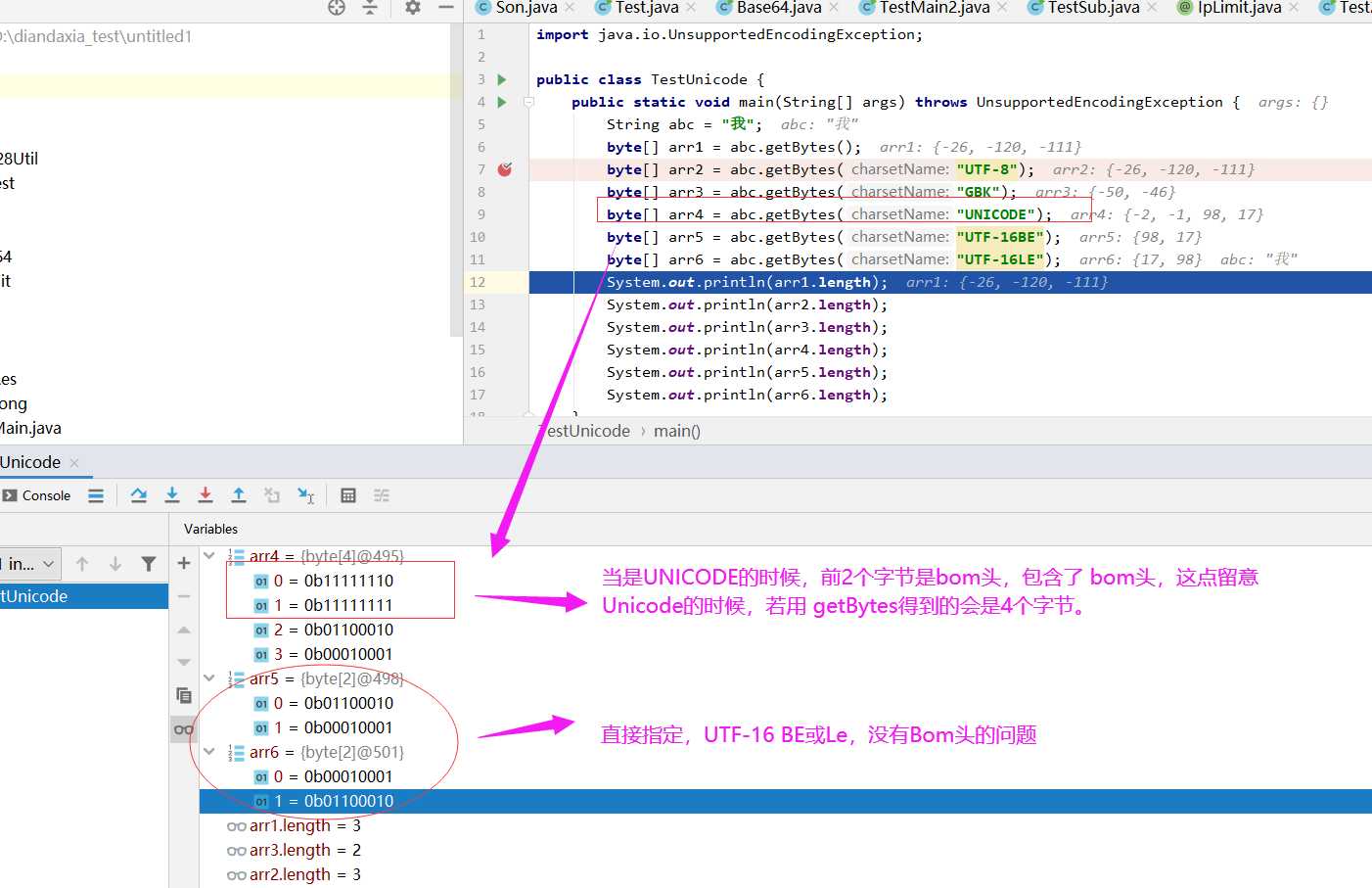
java getBytes("Unicode"))结果为[-2, -1, 0, 97]
请教大家一个问题
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws Exception{
char a = ‘a‘;
System.out.println((int)a);//unicode编码
System.out.println(Arrays.toString("a".getBytes("UTF-8")));
System.out.println(Arrays.toString("a".getBytes("Unicode")));
System.out.println(Arrays.toString("a".getBytes("GBK")));
System.out.println(Arrays.toString("a".getBytes("ASCII")));
}
}
结果为
[97]
[-2, -1, 0, 97]
[97]
[97]
其中,[-2, -1, 0, 97]是什么意思?谢谢
论坛的讨论地址如下:
http://topic.csdn.net/u/20081009/09/e899898c-591f-4985-ae88-5972475708fb.html
测试代码如下:
String s = "1";
byte[] arr = s.getBytes("UNICODE");
System.out.println(Arrays.toString(arr)); // 12
感谢runshine的精到和lky5387、火龙果、accp206的精彩讲解。
7楼
为了在读取字节时能知道所采用的字节序,在传输时采用了一个名为
“ZERO WIDTH NON-BREAKING SPACE”(U+FEFF)的字符用于限定字节序,
开头两个字节为 FE FF 时为 Big-Endian,为 FF FE 时为 Little-Endian。
详见 RFC2781 3.2 节。
在 Java 中直接使用 Unicode 转码时会按照 UTF-16LE 的方式拆分,并加上 BOM。
如果采用 UTF-16 拆分,在 Java 中默认采用带有 BOM 的 UTF-16BE 拆分。
11楼
Unicode规范中推荐的标记字节顺序的方法是BOM。BOM不是“Bill Of Material”的BOM表,而是Byte Order Mark。
(Unicode是一种字符编码方法,不过它是由国际组织设计,可以容纳全世界所有语言文字的编码方案。Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。UCS可以看作是"Unicode Character Set"的缩写。)
在UCS编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议在传输字节流前,先传输字 符"ZERO WIDTH NO-BREAK SPACE"。
这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。
在 Java 中直接使用Unicode 转码时会按照UTF-16LE 的方式拆分,并加上 BOM。 如果采用 UTF-16 拆分,在 Java 中默认采用带有 BOM 的 UTF-16BE 拆分。 (其实Unicode与UTF-8是完全一样的)
12楼
2个疑问,
1 为何UTF-8没有
2 我想知道,在源代码里的哪个部分做的这个判断。
19楼
引用 11 楼 lky5387 的回复:
其实Unicode与UTF-8是完全一样的
嗯,UTF-8 是通过 Unicode 转换而来的,是 Unicode 的表现形式之一。
引用 12 楼 java2000_net 的回复:
2个疑问,
1 为何UTF-8没有
2 我想知道,在源代码里的哪个部分做的这个判断。
只能回答你第一个问题:
UTF-8 是采用 1~4 个字节来表示 Unicode 字符的,每个 Unicode 的 UTF-8 编码的
第一个字节是有一定范围的,如果读取到某个字节的最高位为 0 那么采用一个字节表
示,如果最高位是两个“1”就采用两个字节表示,最高位是三个“1”采用三个字节表
示,以此类推。多字节表示时,第二个和后面的字节的最高位只能是“10”,也就是说
UTF-8 编码时字符的第一个字节的最高位不可能是“10”。
因此,UTF-8 只能采用 Big-Endian 的 BOM 方式。BOM 头 U+FEFF,UTF-8 编码为 EF BB BF
就稳含掉了。
如果采用 LE 方式时,字节序颠倒了,第一个字节最高位就是“10”了,这时 UTF-8 读
取时会产生错误,这时会采用一个被称为 Replacement Character (U+FFFD) 的字符来代替。
第二个问题正在看源代码……
24楼
java.lang.String#getBytes(String) 的源代码:
public byte[] getBytes(String s) throws UnsupportedEncodingException {
if(s == null)
throw new NullPointerException();
else
return StringCoding.encode(s, value, offset, count);
}
java.lang.StringCoding.encode 的源代码:
static byte[] encode(String s, char ac[], int i, int j) throws UnsupportedEncodingException {
Object obj = (StringEncoder)deref(encoder);
String s1 = s != null ? s : "ISO-8859-1";
if(obj == null || !s1.equals(((StringEncoder) (obj)).requestedCharsetName()) && !s1.equals(((StringEncoder) (obj)).charsetName())) {
obj = null;
try {
Charset charset = lookupCharset(s1);
if(charset != null)
obj = new CharsetSE(charset, s1);
} catch(IllegalCharsetNameException illegalcharsetnameexception) { }
if(obj == null)
obj = new ConverterSE(CharToByteConverter.getConverter(s1), s1);
set(encoder, obj);
}
return ((StringEncoder) (obj)).encode(ac, i, j);
}
Unicode 编码不存在对应的 Charset 因此会执行 new ConverterSE(CharToByteConverter.getConverter(s1), s1);
这一句。再通过其底层类库的字符集类 sun.io.CharacterEncoding 可以找出 Unicode 的转换器,
是采用 sun.io.CharToByteUnicode 这个类的,这个类的 sun.io 包是读取 file.encoding.pkg 这
个系统属性拼接字符串反射而来的。
这个类是这样拼出来的:
file.encoding.pkg 属性值 + "." + "CharToByte" + CharacterEncoding 中保存的名字
这个类的构造是:
public CharToByteUnicode() {
usesMark = true;
markWritten = false;
byteOrder = 0;
String s = (String)AccessController.doPrivileged(new GetPropertyAction("sun.io.unicode.encoding", "UnicodeBig"));
if(s.equals("UnicodeBig"))
byteOrder = 1;
else
if(s.equals("UnicodeLittle"))
byteOrder = 2;
else
byteOrder = 1;
}
String s = (String)AccessController.doPrivileged(new GetPropertyAction("sun.io.unicode.encoding", "UnicodeBig"));
这一句很关键,决定着 Unicode 编码时 byteOrder 的值是 1 还是 2。这里有个 sun.io.unicode.encoding
这个系统属性,在 Windows 系统下的值为:UnicodeLittle,因此 byteOrder 值为 2。
注:有苹果机的同学用 System.out.println(System.getProperty("sun.io.unicode.encoding")); 看看这个值
是啥。
至于 Unicode 是怎么转换的看看 sun.io.CharToByteUnicode 这个类的源代码就有了。
25楼
果子继续,我想知道那个 -2 从哪里来的!
我只看到了2
27楼, 果子有点“生气”了,哈哈
汗,已经说了很清楚了啊,在 sun.io.CharToByteUnicode 这个类中啊。
贴上源代码吧。
Java code
01 public int convert(char ac[], int i, int j, byte abyte0[], int k, int l) throws ConversionBufferFullException, MalformedInputException {
02 charOff = i;
03 byteOff = k;
04 if(i >= j)
05 return 0;
06 int i1 = i;
07 int j1 = k;
08 int k1 = l - 2;
09 if(usesMark && !markWritten) {
10 if(j1 > k1)
11 throw new ConversionBufferFullException();
12 if(byteOrder == 1) {
13 abyte0[j1++] = -2;
14 abyte0[j1++] = -1;
15 } else {
16 abyte0[j1++] = -1;
17 abyte0[j1++] = -2;
18 }
19 markWritten = true;
20 }
21 if(byteOrder == 1)
22 while(i1 j) {
23 if(j1 > k1) {
24 charOff = i1;
25 byteOff = j1;
26 throw new ConversionBufferFullException();
27 }
28 char c = ac[i1++];
29 abyte0[j1++] = (byte)(c >> 8);
30 abyte0[j1++] = (byte)(c & 255);
31 }
32 else
33 while(i1 j) {
34 if(j1 > k1) {
35 charOff = i1;
36 byteOff = j1;
37 throw new ConversionBufferFullException();
38 }
39 char c1 = ac[i1++];
40 abyte0[j1++] = (byte)(c1 & 255);
41 abyte0[j1++] = (byte)(c1 >> 8);
42 }
43 charOff = i1;
44 byteOff = j1;
45 return j1 - k;
46 }
12 判断字节序,13~14 行写入 BE 的 BOM;16~17 行写入 LE 的 BOM。
22~31 以 BE 方式写入字节,33~42 以 LE 方式写入字节。
BE 和 LE 的写入方式仅在 29~30 和 40~41 行不同。
29~30 为 BE 序先写入高字节,再写入低字节,而 40~41 为 LE 序,先写低字节,再写高字节的。
28楼
关于 Unicode 转为 byte 数组,做了个小实验,呵呵。
public class Test1 {
private final static char[] HEX = "0123456789abcdef".toCharArray();
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "中国";
String[] encoding = {
"Unicode", "UnicodeBig", "UnicodeLittle",
"UnicodeBigUnmarked", "UnicodeLittleUnmarked",
"UTF-16", "UTF-16BE", "UTF-16LE"
};
for(int i = 0; i ) {
System.out.printf("%-22s %s%n",
encoding[i],
bytes2HexString(str.getBytes(encoding[i]))
);
}
}
public static String bytes2HexString(byte[] bys) {
char[] chs = new char[bys.length * 2 + bys.length - 1];
for(int i = 0, offset = 0; i ) {
if(i > 0) {
chs[offset++] = ‘ ‘;
}
chs[offset++] = HEX[bys[i] >> 4 & 0xf];
chs[offset++] = HEX[bys[i] & 0xf];
}
return new String(chs);
}
}
输出结果:
Unicode ff fe 2d 4e fd 56
UnicodeBig fe ff 4e 2d 56 fd
UnicodeLittle ff fe 2d 4e fd 56
UnicodeBigUnmarked 4e 2d 56 fd
UnicodeLittleUnmarked 2d 4e fd 56
UTF-16 fe ff 4e 2d 56 fd
UTF-16BE 4e 2d 56 fd
UTF-16LE 2d 4e fd 56
总结:
1. Unicode 的字节序方式采用 sun.io.unicode.encoding 的系统属性,并且是加上 BOM 的。
转换类为:sun.io.CharToByteUnicode
2. UnicodeBig 字节序为 BE 方式,加上 BOM
转换类为:sun.io.CharToByteUnicode 不过在 sun.io.CharToByteUnicodeBig 中强制使用 BE 序,
即即构造时强制设定 byteOrder 值为 1
3. UnicodeLittle 字节序为 LE 方式,加上 BOM
转换类为:sun.io.CharToByteUnicode 不过在 sun.io.CharToByteUnicodeLittle 中强制使用 LE 序,
即即构造时强制设定 byteOrder 值为 2
4. UnicodeBigUnmarked 字节序为 BE 方式,有 Unmarked 不加 BOM
转换类为:sun.io.CharToByteUnicode 不过在 sun.io.CharToByteUnicodeBigUnmarked 中强制使用 BE 序和不加 BOM。
即构造时强制设定 byteOrder 值为 1,usesMark 值为 false
5. UnicodeLittleUnmarked 字节序为 LE 方式,有 Unmarked 不加 BOM
转换类为:sun.io.CharToByteUnicode 不过在 sun.io.CharToByteUnicodeLittleUnmarked 中强制使用 LE 序和不加 BOM。
即构造时强制设定 byteOrder 值为 2,usesMark 值为 false
6. UTF-16 字节序为 BE 方式,加上 BOM
转换类为:sun.io.CharToByteUnicode 不过在 sun.io.CharToByteUTF16 中强制使用 BE 序和加 BOM。
即构造时强制设定 byteOrder 值为 1,usesMark 值为 true
UTF-16 实际上与 UnicodeBig 是一样的。
7. UTF-16BE 没有转换类,与 UnicodeBigUnmarked 使用相同的转换器。
8. UTF-16LE 没有转换类,与 UnicodeLittleUnmarked 使用相同的转换器。
上面的那些类都是 sun.io.CharToByteUnicode 的子类,这些子类中就只有设定各种格式的构造方法。
根据 CharacterEncoding 的映射与 UnicodeBigUnmarked 兼容的编码有:unicode-1-1, iso-10646-ucs-2, utf-16be, x-utf-16be 这么几个。而且 UnicodeLittleUnmarked 兼容的有:utf-16le, x-utf-16le 这两个。
30楼
之前的话:
来迟了!但不可惜。呵呵。
输出结果:
[-2, -1, 0, 49]
问题现象:
“意外”地多了两个字节,即数组前两个元素,其值分别为-2、-1
问题原因:
楼上各位已经说得非常清楚,详见7楼与11楼
相关源码:
这是楼主最感兴趣的内容,所以说得详细一些。
String的encode()方法里边调用了StringCoding的encode()方法。
StringCoding的encode()方法有点复杂,包括缓存机制、Charset对象的创建等,但主要是调用了其嵌套类StringEncoder的encode()方法。
而StringCoding.StringEncoder类的encode()方法又用到了CharsetEncoder类的encode()方法。
CharsetEncoder的encode()又调用了它自己的encodeLoop()方法。——这就是答案所在。换句话说,输出BOM的源代码就在CharsetEncoder的encodeLoop()方法中。
encodeLoop()方法是抽象方法,不同的子类有不同的实现。
针对于“Unicode”编码,其对应的类为sun.nio.cs.UTF_16的嵌套类Encoder,以下是其源码:
Java code
private static class Encoder extends UnicodeEncoder
{
public Encoder(Charset charset)
{
super(charset, 0, true);
}
}
以下是其父类UnicodeEncoder的部分源码:
Java code
//构造方法
protected UnicodeEncoder(Charset charset, int i, boolean flag)
{
super(charset, 2.0F, flag ? 4F : 2.0F, i != 0 ? (new byte[] {
-3, -1
}) : (new byte[] {
-1, -3
}));
usesMark = needsMark = flag;
byteOrder = i;
}
//最终完成编码任务的方法——答案所在。
protected CoderResult encodeLoop(CharBuffer charbuffer, ByteBuffer bytebuffer)
{
// 省略无关代码
if (needsMark)
{
if (bytebuffer.remaining() )
return CoderResult.OVERFLOW;
put(‘/uFEFF‘, bytebuffer);
needsMark = false;
}
// 省略无关代码
}
看完源码,再分析一下执行过程:
1、因为当前使用的字符编码是“Unicode”,所以对应的CharsetEncoder是sun.nio.cs.UTF_16.Encoder
2、在创建UTF_16.Encoder的对象时,其传给父类构造函数的第三个参数是true,意味着needsMark将被赋值为true
3、由于needsMark为true,在encodeLoop()执行的时候,会写入0xFE、0xFF。然后needsMark被赋值为false,意味着BOM最多只写入一次
4、0xFE、0xFF转换成byte,就分别是-2、-1
问题补充:
楼主又问到,为什么使用“UTF-8”时不会加BOM?
参见第19楼。
而从源代码的角度来说,因为“UTF-8”所对应的CharsetEncoder是sun.nio.cs.UTF_8.Encoder,
在这个类的源代码中,encodeLoop()方法及与其的encodeArrayLoop()、encodeBufferLoop()方法的确没有写入BOM的操作,呵呵。
后面的话:
1、我的结论与27楼不太一致,27楼说的是sun.io.CharToByteUnicode,但我觉得我的跟踪和分析过程是正确的,我是在JDK6下做的这个过程。呵呵。
2、强手如云啊,学习了!呵呵。
再次感谢火龙果,钦佩他的研究精神和无私奉献精神以及超强的忍耐力(我有时挺烦人的)。
感谢 lky5387 的精彩发言
感谢accp206 在最后时刻的发言。
也感谢所有的参与者,大家都提高了经验值。
————————————————
版权声明:本文为CSDN博主「老紫竹」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/java2000_net/java/article/details/3047001
文章标题:unicode 查询网站 分析 getBytes 的问题
文章链接:http://soscw.com/index.php/essay/55807.html