3.K均值算法
2021-02-16 18:19
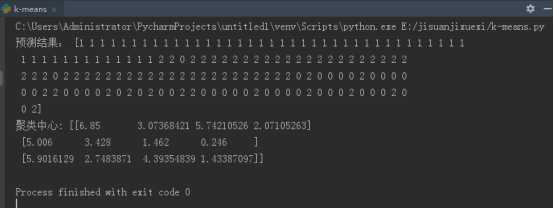
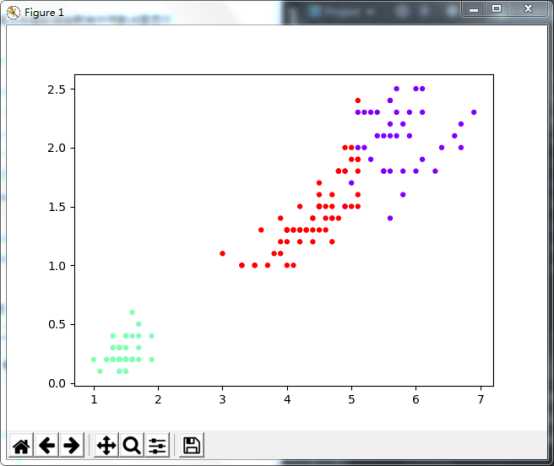
标签:http 技术 ica marker lsp 建模 res print 最优 1). 扑克牌手动演练k均值聚类过程:>30张牌,3类 样本中心 12 8 3 样本数量 9 9 9 样本总和 108 78 37 样本均值 12 8.7 4.1 3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示. import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import load_iris iris = load_iris() mh=iris.data[:,1] #数据 x=mh.reshape(-1,1) p = KMeans(n_clusters=3) p.fit(x) #训练数据 y_kmeans = p.predict(x)#预测每个样本的聚类索引 plt.scatter(x[:, 0], x[:, 0], c=y_kmeans, s=50, marker=‘.‘,cmap=‘rainbow‘); plt.show() 4). 鸢尾花完整数据做聚类并用散点图显示. import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import load_iris iris = load_iris() x = iris.data # 鸢尾花数据 model = KMeans(n_clusters=3) # 构建模型 model.fit(x) # 训练数据 y = model.predict(x) # 预测每个样本的聚类索引 print("预测结果:", y) k = model.cluster_centers_ # 聚类中心 print("聚类中心:", k) plt.scatter(x[:, 2], x[:, 3], c=y, s=50, cmap=‘rainbow‘,marker=‘.‘) plt.show() 5).想想k均值算法中以用来做什么? K-means聚类也称快速聚类,可以用于大量数据进行聚类的情形。在开始聚类之前,需要分析者自己制定类数目,并不是一次指定,可以经过多轮反复分析,根据实际情况最终判定最优类的数目。 K-means聚类是采用计算距离的方式测度变量间的亲疏程度,距离直接影响最终的结果,因此慎重审核数据质量。 可用于顾客细分,顾客细分中关键问题是找出顾客的特征,一般可从顾客自然特征和消费行为入手,在大型统计分析工具出现之前,主要是通过两种方式进行“分群别类”,第一种,用单一变量进行划段分组,比如,以消费频率变量细分,即将该变量划分为几个段,高频客户、中频客户、低频客户,这样的状况;第二种,用多个变量交叉分组,比如用性别和收入两个变量,进行交叉细分。 3.K均值算法 标签:http 技术 ica marker lsp 建模 res print 最优 原文地址:https://www.cnblogs.com/pangminhua/p/12702364.html