[Java] 分布式消息队列(MQ)
标签:不能 要求 netty 数据存储 connector down 定义 镜像 ESS
概述
场景
- 服务解耦
- 削峰填谷
- 异步化缓冲:最终一致性/柔性事务
MQ应用思考点
- 生产端可靠性投递
- 消费端幂等:消息只能消费一次
- 高可用、低延迟、可靠性
- 消息堆积能力
- 可扩展性
业界主流MQ
- ActiveMQ:适合传统需求,并发性差
- RabbitMQ:扩展性差
- RocketMQ:扩展性强
- Kafka:扩展性强,并发性强,可靠性差
技术选型
- 性能、优缺点、业务场景
- 集群架构模式,分布式、可扩展、高可用、可维护性
- 综合成本,集群规模,人员成本
- 未来的方向、规划、思考
ActiveMQ
介绍
- JMS(Java Message Service):Java消息服务,定义了Java中访问消息中间件的接口规范
- 实现JMS的中间件称为“JMS Provider”
- MOM (Message Oriented Middleware 消息中间件):ActiveMQ、RocketMQ、RabbitMQ、Kafka
术语
- JMS(Java Message Service):Java消息服务接口
- Provider(MessageProvider):消息的生产者
- Consumer(MessageConsumer):消息的消费者
- PTP(Point to Point):即点对点的消息模型,这也是非常经典的模型
- Pub / Sub(Publish/Subscribe):,即发布/订阅的消息模型
- Queue:队列目标,也就是我们常说的消息队列,一般都是会真正的进行物理存储
- Topic:主题目标
- ConnectionFactory:连接工厂,JMS 用它创建连接
- Connection:JMS 客户端到JMS Provider 的连接
- Destination:消息的目的地
- Session:会话,一个发送或接收消息的线程(这里Session可以类比Mybatis的Session)
消息定义格式
- StreamMessage:原始值的数据流
- MapMessage:一套名称/值对
- TextMessage:一个字符串对象
- BytesMessage:一个未解释字节的数据流
- ObjectMessage:一个序列化的Java对象
消息投递模式
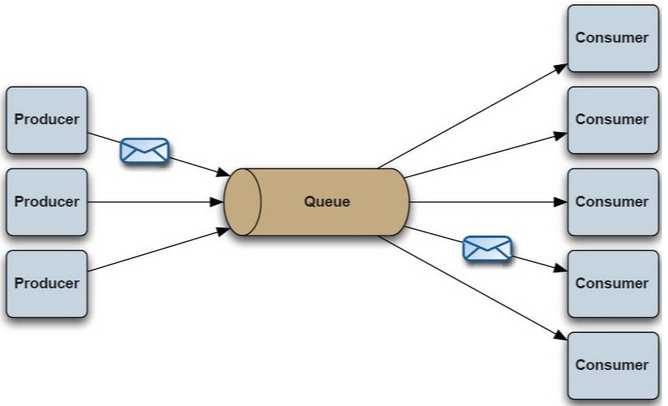
- 点对点:生产者向队列投递消息,只有一个消费者能监听到这条消息
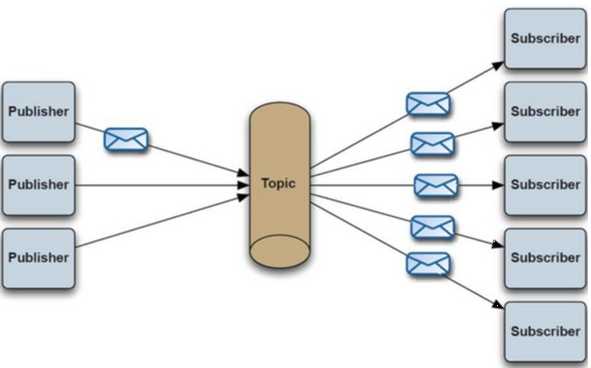
- 发布订阅:生产者向队列投递一条消息,所有监听该队列的消费者都能够监听得到这条消息
ActiveMQ各项指标
- 服务性能:适用于传统行业需求,对高并发、大数据的业务场景支持不足
- 数据存储:默认为kahadb存储(索引--文件),可采用google leveldb(内存数据库),或MySql/Oracle(关系型数据库)
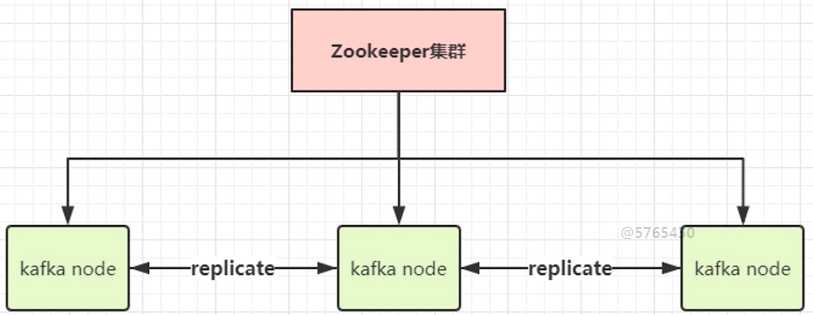
- 集群架构:可与zookeeper构建主备集群模型
集群架构模式
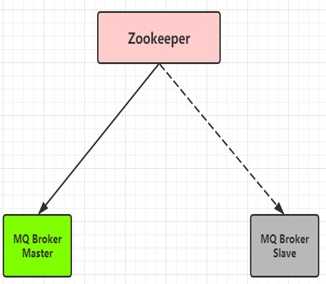
- Master-Slave:主从模式,双机热备
- 目前ActiveMQ推荐的高可靠性和容错的解决方案
- 绿色的为主节点,灰色的则为备份节点,这两个节点都是运行状态的
- zookeeper的作用:主节点宕机时,及时切换到备份的灰色节点,进行主从角色互换,以实现高可用性
- 缺陷:不能做到分布式的topic、queue,消息量巨大时MQ集群压力过大
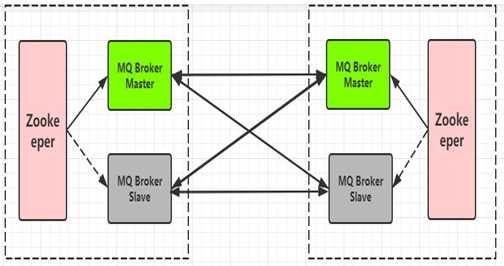
- Network:网络通信方式(Network of brokers)
- 真正解决了分布式消息存储和故障转移,broker切换的问题
- 一个broker会同等对待所有的subscription
- 需要两套或多套(Master-Slave)的集群模型实现
- 缺陷:资源浪费,部署复杂
1 broker brokerName="receiver" persistent="false" useJmx="false">
2 transportConnectors>
3 transportConnector uri="tcp://localhost:62002"/>
4 transportConnectors>
5 networkConnectors>
6 networkConnector
7 uri="static:( tcp://localhost:61616,tcp://remotehost:61616)"/>
8 networkConnectors>
9 broker>
RocketMQ
介绍
- 高并发、高可靠性、海量数据场景
- 底层通信框架采用Netty NIO
- 用NameServer代替Zookeeper
- 支持集群、负载均衡、水平扩展
- 灵拷贝,顺序写,随机读
- 消息失败重试机制,消息可查询
术语
- Producer:消息生产者,负责产生消息,一般由业务系统负责产生消息
- Consumer:消息消费者,负责消费消息,一般是后台系统负责异步消费
- Push Consumer:Consumer的一种,需要向Consumer对象注册监听
- Pull Consumer:Consumer的一种,需要主动请求Broker拉取消息
- Producer Group:生产者集合,一般用于发送一类消息
- Consumer Group:消费者集合,一般用于接受一类消息进行消费
- Broker : MQ消息服务(中转角色,用于消息存储与生产消费转发)
集群架构
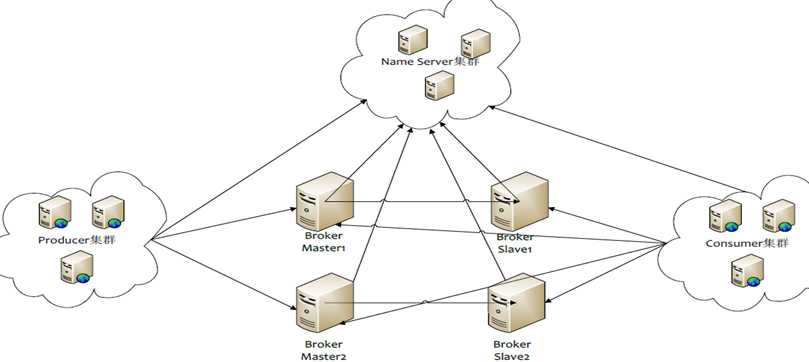
RabbitMQ
概述
- 实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)
集群架构
- 主备模式:warren(兔子窝),主节点挂了,从节点提供服务,类似ActiveMQ利用Zookeeper做主/备
- 远程模式:远距离通信和复制,实现双活模式,简称Shovel模式,配置复杂
- 镜像模式:高可用,数据同步,实现简单,三节点,类似MongoDB的replicate
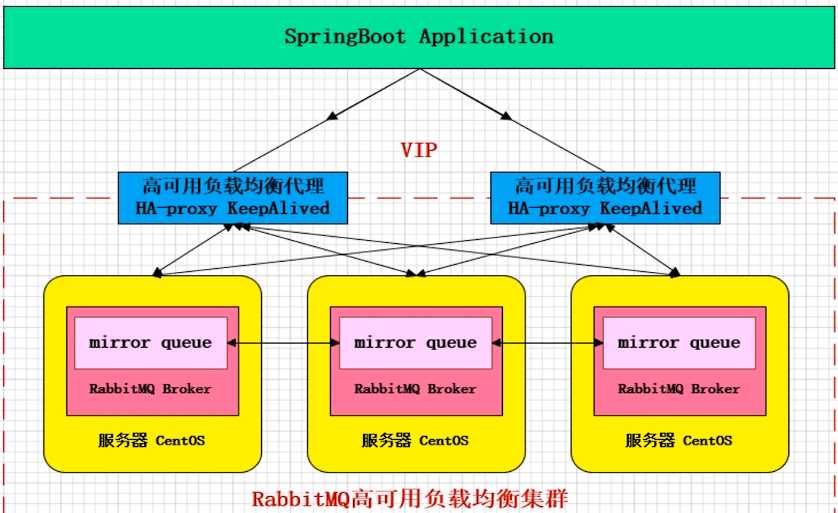
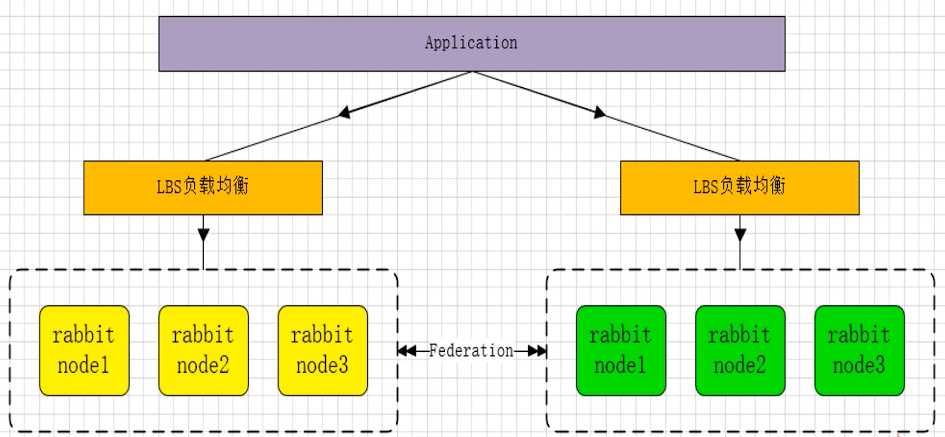
- 多活模式:采用双中心模式,两套数据中心各部署一套RabbitMQ集群,各中心间实现部分队列消息共享
- Federation插件:不需构建Cluster,在Broker间传递消息的高性能插件,使用AMQP协议,可接受不连续的传输
- Federation Exchange:Downstream从Upstream主动拉取订阅的消息
Kafka
介绍
- 基于Pull的模式处理消息消费,追求高吞吐量,开始的目的是用于日志收集和传输
- 支持复制,不支持事务,对消息的重复、错误、丢失没有严格要求
- 适合产生大量数据的互联网服务的数据收集业务
- 分布式、跨平台、实时性、伸缩性
性能
- 顺序写
- 提高磁盘利用率
- consumer通过offset顺序消费数据,而不删除已消费过的数据,从而避免随机写
- Page Cache(空中接力)
- 高性能,高吞吐
- 后台异步、主动Flush
- 多个异步级别的scheduler,将连续小块组成大的物理文件
- 预读策略、IO调度
Page Cache
- 操作系统级别实现的一种主要磁盘存储策略
- 把磁盘中的数据缓存到内存中,减少IO操作(四次拷贝)
- 高并发互联网项目:MySQL->分库分表->MongoDB->Redis->本地缓存
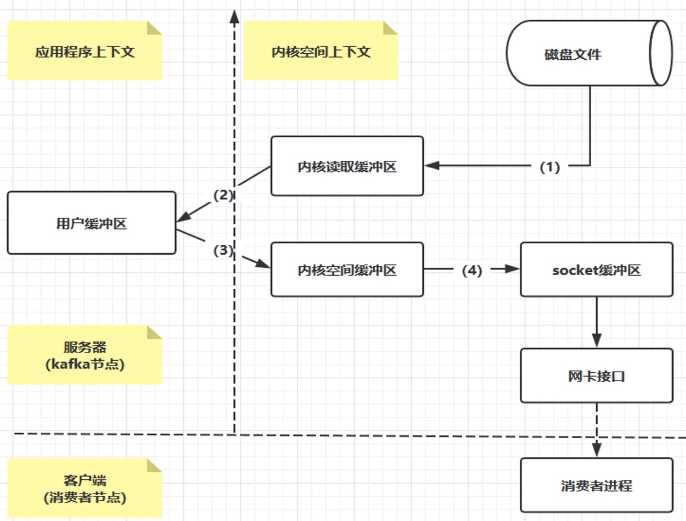
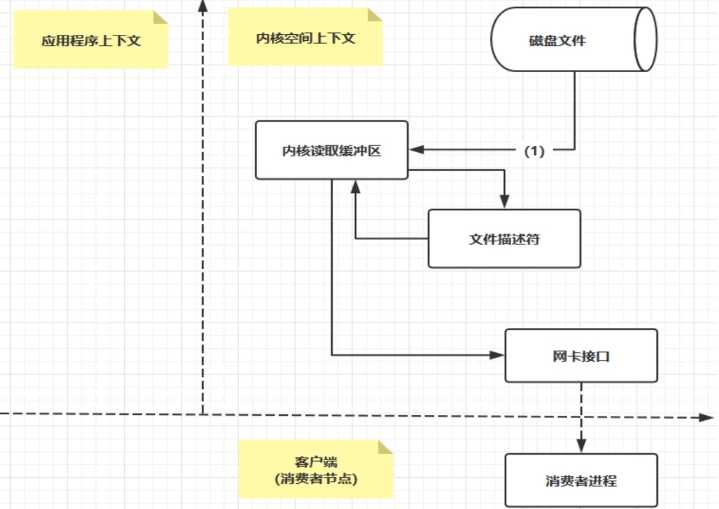
ZeroCopy
- 与应用程序不关联(一次拷贝)
- 从磁盘拷贝到内存读取缓冲区后,直接把数据发送到网卡接口,给消费者使用
- 应用程序不做copy
- 如有10个消费者,传统文件读写需要40次IO操作,ZeroCopy只需1+10次
集群
[Java] 分布式消息队列(MQ)
标签:不能 要求 netty 数据存储 connector down 定义 镜像 ESS
原文地址:https://www.cnblogs.com/cxc1357/p/12676184.html
评论