小说免费看!python爬虫框架scrapy 爬取纵横网
2021-02-17 06:17
标签:pre char xpath pip cmd 学习python 方便 src 测试 文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。 作者: 风,又奈何 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http://t.cn/A6Zvjdun 项目创建: cmd命令行切换到工作目录创建scrapy项目 两条命令 scarpy startproject与scrapy genspider 然后用pycharm打开项目 确定内容 首先打开网页看下我们需要爬取的内容 其实小说的话结构比较简单 只有三大块 卷 章节 内容 因此 items.py代码: 内容提取spider文件编写 还是我们先创建一个main.py文件方便我们测试代码 然后我们可以在spider文件中先编写 运行main.py看看有没有输出 发现直接整个网页的内容都可以爬取下来,说明该网页基本没有反爬机制,甚至不用我们去修改user-agent那么就直接开始吧 打开网页 F12查看元素位置 并编写xpath路径 然后编写spider文件 需要注意的是我们要对小说内容进行一定量的数据清洗,因为包含某些html标签我们需要去除 有时候我们会发现无法进入下个链接,那可能是被allowed_domains过滤掉了 我们修改下就可以 唉 突然发现了到第一卷的一百多章后就要VIP了 那我们就先只弄一百多章吧 不过也可以去其他网站爬取免费的 这次我们就先爬取一百多章吧 接下来就是内容的保存了,这次就直接保存为本地txt文件就行了 首先去settings.py文件里开启 ITEM_PIPELINES 然后编写pipelines.py文件 由于选址失误导致了我们只能爬取免费的一百多章节,尴尬,不过我们可以类比运用到其他网站爬取全文免费的书籍 怎么样 使用scrapy爬取是不是很方便呢 如果你处于想学Python或者正在学习Python,Python的教程不少了吧,但是是最新的吗?说不定你学了可能是两年前人家就学过的内容,在这小编分享一波2020最新的Python教程。获取方式,私信小编 “ 资料 ”,即可免费获取哦! 小说免费看!python爬虫框架scrapy 爬取纵横网 标签:pre char xpath pip cmd 学习python 方便 src 测试 原文地址:https://www.cnblogs.com/python0921/p/12700269.html

前言
准备
D:\pythonwork>scrapy startproject zongheng
New Scrapy project ‘zongheng‘, using template directory ‘c:\users\11573\appdata\local\programs\python\python36\lib\site-packages\scrapy\templates\project‘, created in:
D:\pythonwork\zongheng
?
You can start your first spider with:
cd zongheng
scrapy genspider example example.com
?
D:\pythonwork>cd zongheng
?
D:\pythonwork\zongheng>cd zongheng
?
D:\pythonwork\zongheng\zongheng>scrapy genspider xuezhong http://book.zongheng.com/chapter/189169/3431546.html
Created spider ‘xuezhong‘ using template ‘basic‘ in module:
zongheng.spiders.xuezhong

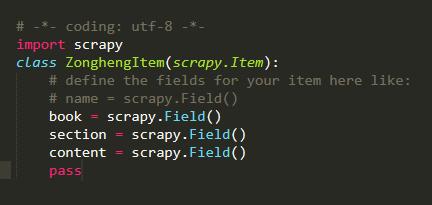
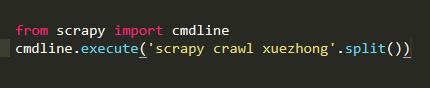
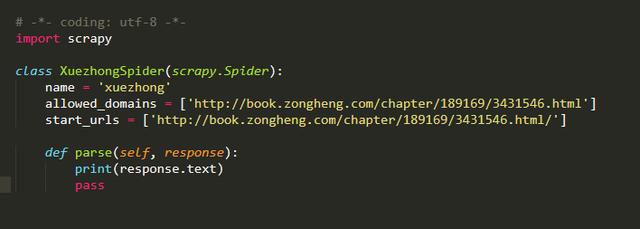
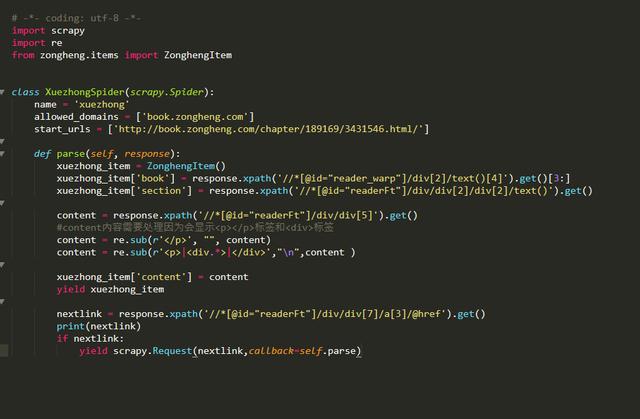
内容保存
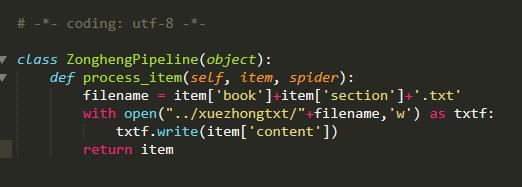
文章标题:小说免费看!python爬虫框架scrapy 爬取纵横网
文章链接:http://soscw.com/index.php/essay/56440.html