python学习之爬虫网络数据采集
2021-02-17 18:20
标签:获取 %s 函数 功能 page header params png 需要 urllib库 urllib库:urlopen requests库 有些网站访问时必须带有浏览器等信息,如果不传入headers就会报错。 在进行爬虫爬取时,有时候爬虫会被服务器给屏蔽掉,这时采用的方法主要有降低访问时 python学习之爬虫网络数据采集 标签:获取 %s 函数 功能 page header params png 需要 原文地址:https://blog.51cto.com/13810716/2486979
urllib、requests这两个模块。
网络数据采集之urllib
官方文档地址:https://docs.python.org/3/library/urllib.html
urllib库是python的内置HTTP请求库,包含以下各个模块内容:
(1)urllib.request:请求模块
(2)urllib.error:异常处理模块
(3)urllib.parse:解析模块
(4)urllib.robotparser:robots.txt解析模块
urlopen进行简单的网站请求,不支持复杂功能如验证、cookie和其他HTTP高级功能,
若要支持这些功能必须使用build_opener()函数返回的OpenerDirector对象。
urllib库:User-Agent伪装后请求网站
很多网站为了防止程序爬虫爬网站照成网站瘫痪,会需要携带一些headers头部信息才能
访问, 我们可以通过urllib.request.Request对象指定请求头部信息
网络数据采集之requests库
requests官方网址: https://requests.readthedocs.io/en/master/
Requests is an elegant and simple HTTP library for Python, built for human
beings.
request方法汇总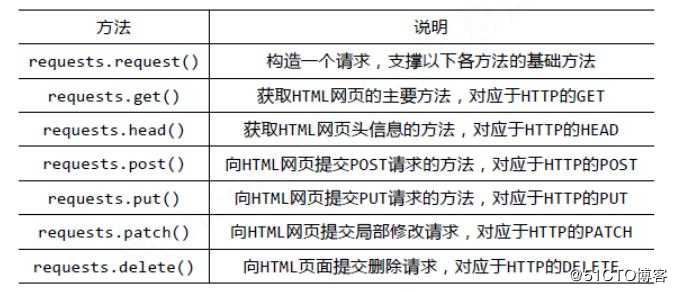
Response对象包含服务器返回的所有信息,也包含请求的Request信息。
reqursts.pyfrom urllib.error import HTTPError
import requests
def get():
# get方法可以获取页面数据,也可以提交非敏感数据
#url = ‘http://127.0.0.1:5000/‘
#url = ‘http://127.0.0.1:5000/?username=fentiao&page=1&per_page=5‘
url = ‘http://127.0.0.1:5000/‘
try:
params = {
‘username‘: ‘fentiao‘,
‘page‘: 1,
‘per_page‘: 5
}
response = requests.get(url, params=params)
print(response.text, response.url)
#print(response)
#print(response.status_code)
#print(response.text)
#print(response.content)
#print(response.encoding)
except HTTPError as e:
print("爬虫爬取%s失败: %s" % (url, e.reason))
def post():
url = ‘http://127.0.0.1:5000/post‘
try:
data = {
‘username‘: ‘admin‘,
‘password‘: ‘westos12‘
}
response = requests.post(url, data=data)
print(response.text)
except HTTPError as e:
print("爬虫爬取%s失败: %s" % (url, e.reason))
if __name__ == ‘__main__‘:
get()
#post()高级应用一: 添加 headers
headers = { ‘User-Agent‘: useragent}
response = requests.get(url, headers=headers)
UserAgent是识别浏览器的一串字符串,相当于浏览器的身份证,在利用爬虫爬取网站数据时,
频繁更换UserAgent可以避免触发相应的反爬机制。fake-useragent对频繁更换UserAgent提供
了很好的支持,可谓防反扒利器。
user_agent = UserAgent().randomimport requests
from fake_useragent import UserAgent
def add_headers():
# headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0‘}
#UserAgent实质上是从网络获取所有的用户代理, 再通过random随机选取一个用户代理。
#https://fake-useragent.herokuapp.com/browsers/0.1.11
ua = UserAgent()
#默认情况下, python爬虫的用户代理是python-requests/2.22.0。
response = requests.get(‘http://127.0.0.1:5000‘, headers={‘User-Agent‘: ua.random})
print(response)
if __name__ == ‘__main__‘:
add_headers()高级应用二: IP代理设置
间,通过代理IP访问。ip可以从网上抓取,或者某宝购买。
proxies = { "http": "http://127.0.0.1:9743", "https": "https://127.0.0.1:9743",}
response = requests.get(url, proxies=proxies)
百度的关键词接口:
https://www.baidu.com/baidu?wd=xxx&tn=monline_4_dg
360的关键词接口:http://www.so.com/s?q=keyword
import requests
from fake_useragent import UserAgent
ua = UserAgent()
proxies = {
‘http‘: ‘http://222.95.144.65:3000‘,
‘https‘: ‘https://182.92.220.212:8080‘
}
response = requests.get(‘http://47.92.255.98:8000‘,
headers={‘User-Agent‘: ua.random},
proxies=proxies
)
print(response)
#这是因为服务器端会返回数据: get提交的数据和请求的客户端IP
#如何判断是否成功? 返回的客户端IP刚好是代理IP, 代表成功。
print(response.text)