python学习之网络数据解析
2021-02-18 00:18
标签:png stripe 名称 pattern get 编程 body match 字符串分割 实际上爬虫一共就四个主要步骤: 正则表达式编译成 Pattern 对象, 可以利用 pattern 的一系列方法对文本进行匹配查找 match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要 ? group([group1, ...]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串 search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的 split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下: sub 方法用于替换。它的使用形式如下: ? repl 可以是字符串也可以是一个函数: lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析 基于requests和Xpath的TIOBE编程语言排行榜定向爬虫.py python学习之网络数据解析 标签:png stripe 名称 pattern get 编程 body match 字符串分割 原文地址:https://blog.51cto.com/13810716/2486993
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
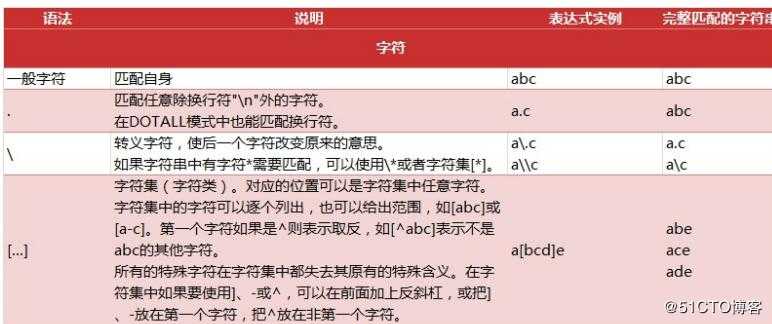
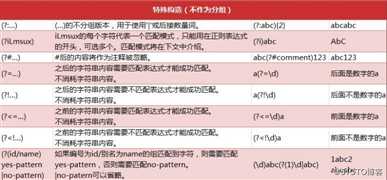
正则表达式匹配规则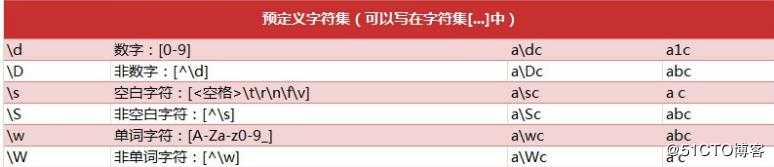
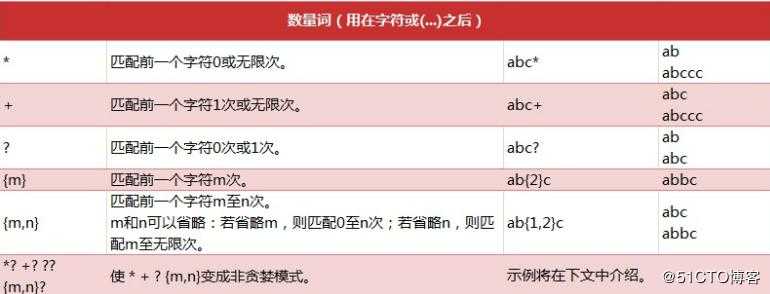

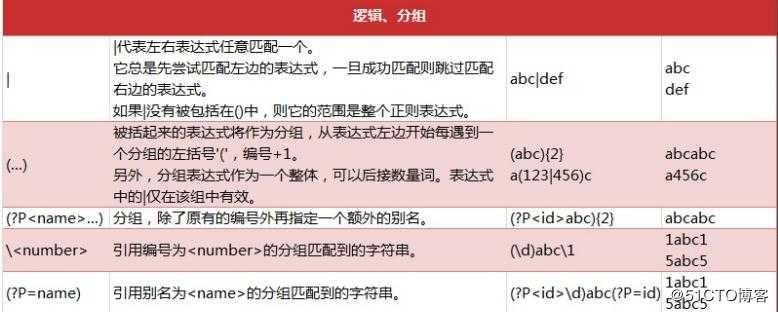
re 模块一般使用步骤
注意: re对特殊字符进行转义,如果使用原始字符串,只需加一个 r 前缀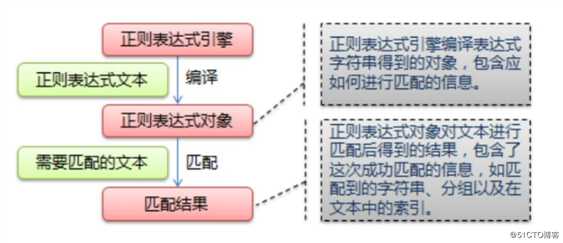
import re
text = """
2020-10-10
2020-11-11
2030/12/12
"""
#1. 使用 compile() 函数将正则表达式的字符串形式编译为一个 Pattern 对象
#注意: re对特殊字符进行转义,如果使用原始字符串,只需加一个 r 前缀
#pattern = re.compile(r‘\d{4}-\d{1,2}-\d{1,2}‘) # 2020-4-11, 无分组的规则
#pattern = re.compile(r‘(\d{4})-(\d{1,2})-(\d{1,2})‘) # 2020-4-11, 有分组的规则
pattern = re.compile(r‘(?PPattern 对象
了。
Pattern 对象的一些常用方法主要有:
? match 方法:从起始位置开始查找,一次匹配
? search 方法:从任何位置开始查找,一次匹配
? findall 方法:全部匹配,返回列表
? finditer 方法:全部匹配,返回迭代器
? split 方法:分割字符串,返回列表
? sub 方法:替换match 方法
找到了一个匹配的结果就返回, 而不是查找所有匹配的结果。它的一般使用形式如下: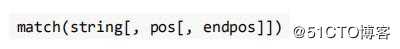
? string 待匹配的字符串
? pos 字符串的起始位置, 默认值是 0
? endpos 字符串的终点位置, 默认值是 len (字符串长度)Match 对象
时,可直接使用 group() 或 group(0);
? start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的
索引),参数默认 值为 0;
? end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符
的索引+1),参数 默认值为 0;
? span([group]) 方法返回 (start(group), end(group))search 方法
结果就返回,而不是查找所有 匹配的结果,它的一般使用形式如下:
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
findall 方法与finditer 方法
findall 方法搜索整个字符串,获得所有匹配的结果。使用形式如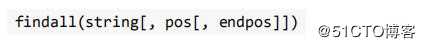
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得
所有匹配的结果。但它返回一个顺序访问每 一个匹配结果(Match 对象)
的迭代器。split 方法
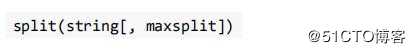
? maxsplit 指定最大分割次数,不指定将全部分割
sub 方法

import re
#****************************split***************************
#text = ‘1+2*4+8-9/10‘
##字符串方法: ‘172.25.254.250‘.split(‘.‘) => [‘172‘, ‘25‘, ‘254‘, ‘250‘]
#pattern = re.compile(r‘\+|-|\*|/‘)
##将字符串根据+或者-或者*或者/进行切割.
#result = re.split(pattern, text)
#print(result)
#***********************sub**************************************
def repl_string(matchObj):
# matchObj方法: group, groups, groupdict
items = matchObj.groups()
#print("匹配到的分组内容: ", items) # (‘2019‘, ‘10‘, ‘10‘)
return "-".join(items)
#2019/10/10 ====> 2019-10-10
text = "2019/10/10 2020/12/12 2019-12-10 2020-11-10"
pattern = re.compile(r‘(\d{4})/(\d{1,2})/(\d{1,2})‘) # 注意: 正则规则里面不要随意空格
#将所有符合条件的信息替换成‘2019-10-10‘
#result = re.sub(pattern, ‘2019-10-10‘, text)
#将所有符合条件的信息替换成‘year-month-day‘
result = re.sub(pattern, repl_string, text)
print(result)
1). 如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换
后的字符串,另外,repl 还 可以使用 id 的形式来引用分组,但不能使用编号 0;
2). 如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字
符串用于替换(返回的字符 串中不能再引用分组)。
? count 用于指定最多替换次数,不指定时全部替换。
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码
范围 主要在[u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是 够用的贪婪模式与非贪婪模式:abbbc
使用贪婪的数量词的正则表达式 ab ,匹配结果: abbb。
使用非贪婪的数量词的正则表达式 ab? ,匹配结果: a。
即使前面有 ,但是 ? 决定了尽可能少匹配 b,所以没有 b。常用的正则常量:
"ASCII": ‘A‘
"IGNORECASE": ‘I‘
"MULTILINE":‘M‘
"DOTALL":‘S‘
import re
#******************************** 1. re.ASCII *****************************
#text = "正则表达式re模块是python中的内置modelue."
##匹配所有的\w+(字母数字下划线, 默认也匹配中文), 不想匹配中文时,指定flags=re.A
#result = re.findall(r‘\w+‘, string=text, flags=re.A)
#print(result)
#******************************** 2. re.IGNORECASE *****************************
#text = ‘hello world heLLo westos Hello python‘
##匹配所有he\w+o, 忽略大小写, re.I
#result = re.findall(r‘he\w+o‘, text, re.I)
#print(result) # [‘hello‘, ‘heLLo‘, ‘Hello‘]
##******************************** 3. re.S *****************************
#text = ‘hello \n world‘
#result = re.findall(r‘^he.*?ld$‘, text, re.S)
#print(result)
##************************匹配中文**********************
#pattern = r‘[\u4e00-\u9fa5]‘
#text = "正则表达式re模块是python中的内置modelue."
#result = re.findall(pattern, text)
#print(result)XPath库
效率非常高。
XPath (XML Path Language) 是一门在 xml文档中查找信息的语言,可用来在 xml
/html文档中对元素和属性进行遍历。
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。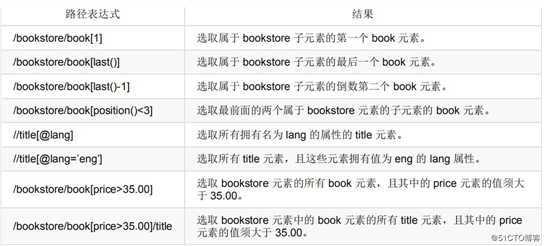
XPath常用规则汇总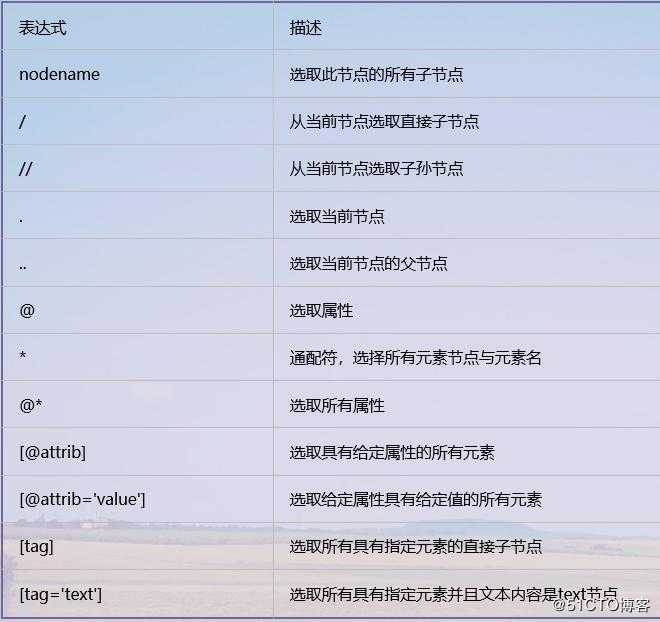
import csv
import requests
from colorama import Fore
from fake_useragent import UserAgent
from lxml import etree
from requests import HTTPError
def download_page(url, parmas=None):
"""
根据url地址下载html页面
:param url:
:param parmas:
:return: str
"""
try:
ua = UserAgent()
headers = {
‘User-Agent‘: ua.random,
}
#请求https协议的时候, 回遇到报错: SSLError
#verify=Flase不验证证书
response = requests.get(url, params=parmas, headers=headers)
except HTTPError as e:
print(Fore.RED + ‘[-] 爬取网站%s失败: %s‘ % (url, str(e)))
return None
else:
# content返回的是bytes类型, text返回字符串类型
return response.text
def parse_html(html):
"""
编程语言的去年名次、今年名次、编程语言名称、评级Rating和变化率Change等信息。
:param html:
:return:
"""
#1). 通过lxml解析器解析页面信息, 返回Element对象
html = etree.HTML(html)
#2). 根据Xpath路径寻找语法获取编程语言相关信息
#获取每一个编程语言的Element对象
#
languages = html.xpath(‘//table[@id="top20"]/tbody/tr‘)
# 依次获取每个语言的去年名次、今年名次、编程语言名称、评级Rating和变化率Change等信息。
for language in languages:
# 注意: Xpath里面进行索引时,从1开始
now_rank = language.xpath(‘./td[1]/text()‘)[0]
last_rank = language.xpath(‘./td[2]/text()‘)[0]
name = language.xpath(‘./td[4]/text()‘)[0]
rating = language.xpath(‘./td[5]/text()‘)[0]
change = language.xpath(‘./td[6]/text()‘)[0]
yield {
‘now_rank‘: now_rank,
‘last_rank‘: last_rank,
‘name‘: name,
‘rating‘: rating,
‘change‘: change
}
def save_to_csv(data, filename):
# 1). data是yield返回的字典对象
# 2). 以追加的方式打开文件并写入
# 3). 文件的编码格式是utf-8
# 4). 默认csv文件写入会有空行, newline=‘‘
with open(filename, ‘a‘, encoding=‘utf-8‘, newline=‘‘) as f:
csv_writer = csv.DictWriter(f, [‘now_rank‘, ‘last_rank‘, ‘name‘, ‘rating‘, ‘change‘])
# 写入csv文件的表头
# csv_writer.writeheader()
csv_writer.writerow(data)
def get_one_page(page=1):
url = ‘https://www.tiobe.com/tiobe-index/‘
filename = ‘tiobe.csv‘
html = download_page(url)
items = parse_html(html)
for item in items:
save_to_csv(item, filename)
print(Fore.GREEN + ‘[+] 写入文件%s成功‘ %(filename))
if __name__ == ‘__main__‘:
get_one_page()