python学习之爬虫理论总结
2021-02-18 03:19
标签:https 基础上 缓存 名称 robots 参数 浏览器 镜像 自动 根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种. 搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从 1.大多情况下,网页里90%的内容对用户来说都是无用的。 聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在 ? HTTP协议-80端口 浏览器发送HTTP请求的过程 URL 客户端发送一个HTTP请求到服务器的请求消息,包括以下格式: Get 和 Post 详解 HTTP响应由四个部分组成,分别是: 状态行 、 消息报头 、 空行 、 响应正文 服务器和客户端的交互仅限于请求/响应过程,结束之后便断开,在下一次请求时,服 制作爬虫的基本步骤 分析网页 python学习之爬虫理论总结 标签:https 基础上 缓存 名称 robots 参数 浏览器 镜像 自动 原文地址:https://blog.51cto.com/13810716/2486958
通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的
是将互联网上的网 页下载到本地,形成一个互联网内容的镜像备份。
通用网络爬虫 从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索
引从而提供支持,它决定着 整个引擎系统的内容是否丰富,信息是否即时,因此其性
能的优劣直接影响着搜索引擎的效果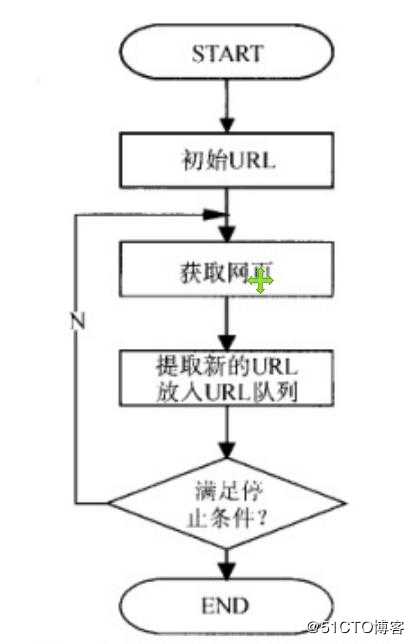
搜索引擎如何获取一个新网站的URL:
爬虫限制
一些命令或文件的内容。
取目标页,同时告诉搜索引擎无需将的当前页的Pagerank
传递到目标页.
全称是“网络爬虫排除标准”(Robots Exclusion
Protocol),网站通过Robots协议告诉搜索引擎哪些页面可
以抓取,哪些页面不能抓取。局限性
聚焦爬虫
于:聚焦爬虫在实施网页 抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的
网页信息。
要学习的,就是聚焦爬虫。HTTP和HTTPS
HyperTextTransferProtocol ,
超文本传输协议是一种发布和接收HTML页面的方法。
? HTTPS-443端口
HypertextTransferProtocoloverSecureSocketLayer ,
简单讲是HTTP的安全版,在HTTP下加入SSL 层。
HTTP工作原理
网络爬虫抓取过程可以理解为模拟浏览器操作的过程。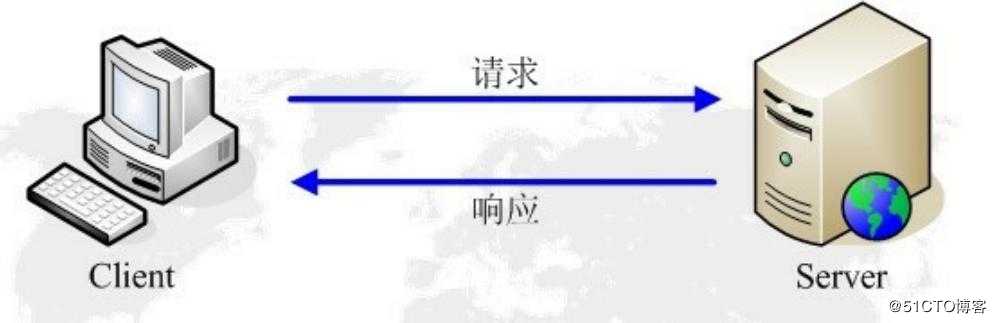
1.当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向HTTP服务
器发送HTTP请求。HTTP请求主要分为“Get”和“Post”两种方法。
Request请求去获取http://www.baidu.com的html文件,服务器把Response文
件对象发送回给浏览器。
3.浏览器分析Response中的HTML,发现其中引用了很多其他文件,比如Images
文件,CSS文件,JS文件。浏览器会自动再次发送Request去获取图片,CSS文件,
或者JS文件。
URL(Uniform/UniversalResourceLocator的缩写):统一资源定位符,是用于完
整地描述Internet上网页和其他资源的地址的一种标识方法。
基本格式: scheme://host[:port#]/path/.../[?query-string][#anchor]
? query-string:参数,发送给http服务器的数据
? anchor:锚(跳转到网页的指定锚点位置)客户端HTTP请求
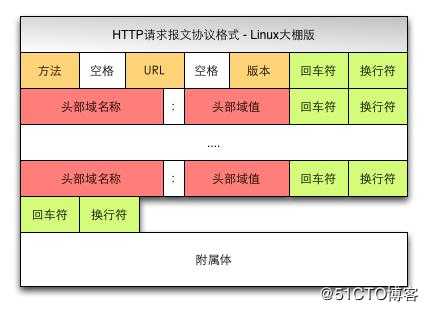
请求方法Method
根据HTTP标准,HTTP请求可以使用多种请求方法.
HTTP0.9:只有基本的文本GET功能。
HTTP1.0:完善的请求/响应模型,并将协议补充完整,定义了三种请求方法:GET,POST和HEAD方法。
HTTP1.1:在1.0基础上进行更新,新增了五种请求方法:OPTIONS,PUT,DELETE,TRACE和CONNECT方法。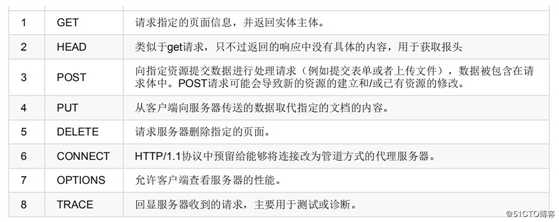
HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等),请求的参数
包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码,
常用的请求报头
Host: 主机和端口号
Connection : 客户端与服务连接类型, 默认为keep-alive
User-Agent: 客户浏览器的名称
Accept: 浏览器或其他客户端可以接受的MIME文件类型
常用的请求报头
Referer:表明产生请求的网页来自于哪个URL
Accept-Encoding:指出浏览器可以接受的编码方式。
Accept-Language:语言种类
Accept-Charset: 字符编码
常用的请求报头
Cookie:浏览器用这个属性向服务器发送Cookie
Content-Type:POST请求里用来表示的内容类型。
HTTP响应

响应状态码
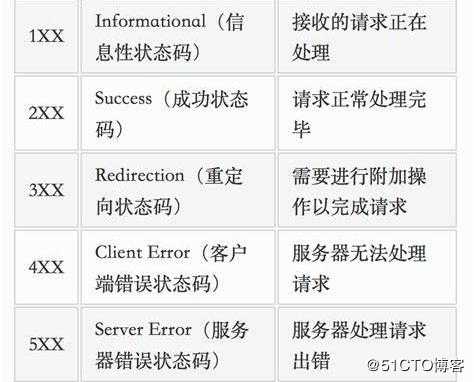
200: 请求成功
302: 请求页面临时转移至新url
307和304: 使用缓存资源
404: 服务器无法找到请求页面
403: 服务器拒绝访问,权限不够
500: 服务器遇到不可预知的情况Cookie和Session
务器会认为新的客户端。为了维护他们之间的链接,让服务器知道这是前一个用户发送
的请求,必须在一个地方保存客户端的信息。
?
Cookie:通过在客户端记录的信
息确定用户的身份。
?
Session:通过在服务器端记录
的信息确定用户的身份。图片下载器
http://image.baidu.com/search/index?tn=baiduimage&word=cat
"我想要图片,我又不想上网搜“
"最好还能自动下载"
......
这就是需求,至少要实现两个功能,一是搜索图片,二是自动下载。

pic_url = re.findall(‘"objURL":"(.*?)",‘,html,re.S)
编写爬虫代码