一文搞定Java集合类,你还在为Java集合类而烦恼吗?
2021-02-19 21:19
标签:方式 前序遍历 扩容 arraylist 红黑树 超过 ++ 面向接口 方法返回值 导读:你还在为集合类而烦恼吗?别担心,我花了几天时间整理了一下集合类,文章通俗易懂,看完这篇文章保证让你茅塞顿开。内容很全,所以文章有点长,建议收藏再看。 Contains(Object O )方法的进阶(选读(如果看不懂建议去复习一下Object的equals方法),因为涉及equals方法得内容)。你可以猜测一下以下代码的执行结果。 答案为:true,你答对了吗?ArrayList集合确实不包含x,下面来分析一下内存结构: 你可能感到奇怪这个方法为什么单独讲,这就不用我说了吧。因为很重要,所以加油呀。 遍历集合/迭代集合,以下讲解的遍历/迭代方式,是所有Collection以及子类通用的一种方法,但是在Map集合中不能使用。 迭代器 Iterator对象,的三个方法: 迭代器最初并没有指向第一个元素。 两个方法配合实现迭代。 第三个方法remove()后期聊。 练习:
文章目录
1.什么是集合,要她作甚?
2.集合存储的数据类型?
那么:你可能会说平时我们遇到的 list.add(100);是怎么个情况?
那是因为java的自动装箱,即将100自动打包装成Integer.
数据结构是数据之间存在一种或多种特定关系的数据元素的集合。数据结构是一门课程,学过的就应该比较清楚。比如,数组,栈,队列,链表,二叉树,哈希表,图,网等。3.常用的集合类
第一种:以单个元素存储。其超级父接口是:java.util.Collection;
第二种:以键值对存储。(类似于python的集合)其超级父接口是:java.util.Map;
Collection集合关系结构图:
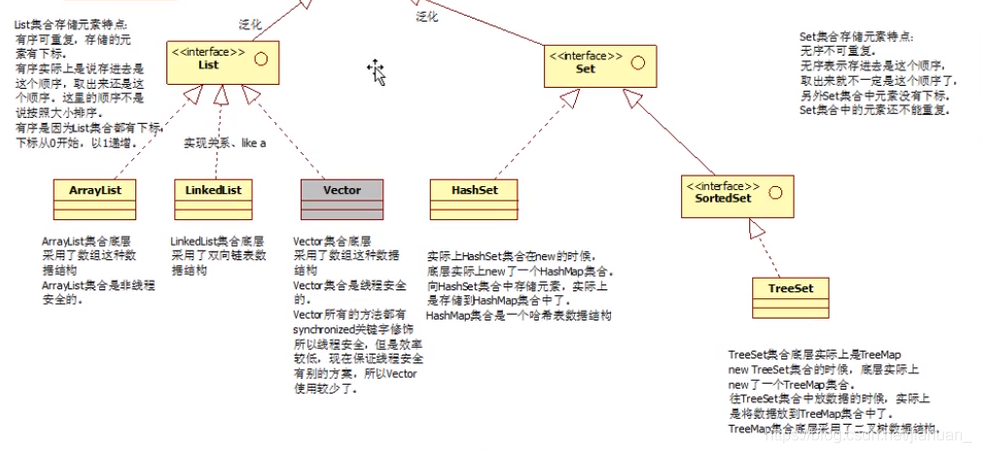
灰色为线程安全得类,但现在用得比较少,因为有更好的方案。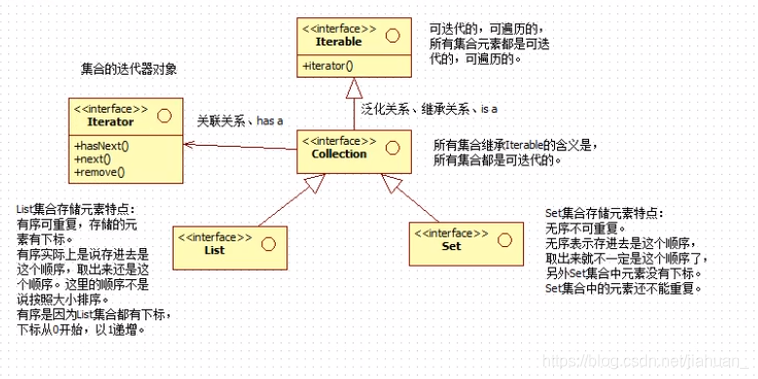


Map集合关系结构图: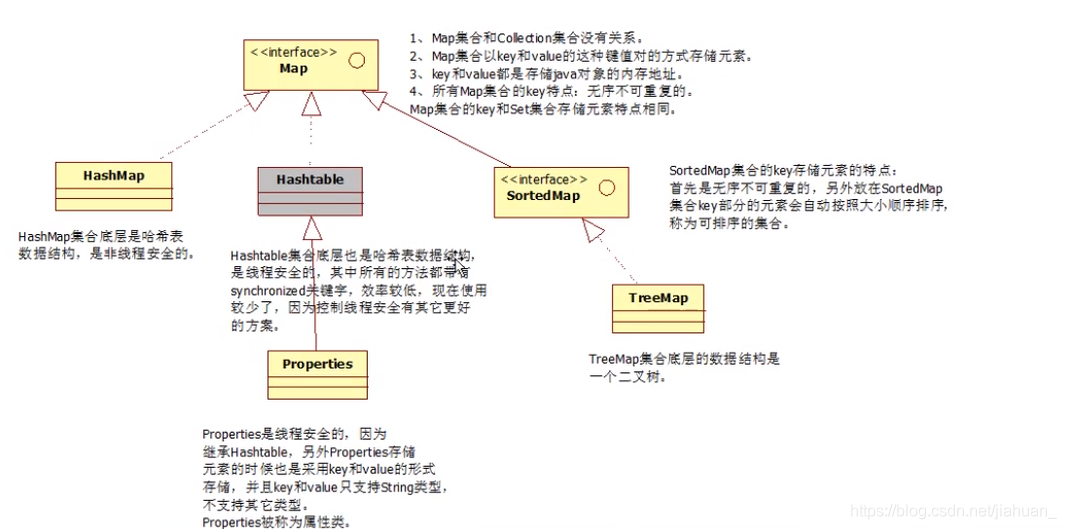


有序可重复
有序:存进去的顺序和取出来的顺序相同,每一个元素都有下标。
无序不可重复
无序:存进去取出来的顺序不一定相同,另外Set集合中元素没有下标。不可重复,存进去1,不能再存储1了。
无需不可重复的。但是SortedSet集合中的元素是可排序的。
无序:存进去的顺序和去除的顺序不一定相同,另外集合元素没有下标,不可重复。
可排序:可以按照大小顺序排序。
在Set集合中放数据,实际上放到了Map集合的key部分。
下面就一个一个的来说一说,以上的类和接口内容尽量熟记。4.Collection接口
如果没有使用泛型,只要是Object子类都可以存储。但是不能存基本数据类型哦,存储的只是对象的地址(唠叨一下)(泛型后期讲解,点点关注不失踪哦)
回顾:接口不能直接new对象,要用类实现。
关于Collection接口中常用的方法,其子类都可以用以下方法。
练习:import java.util.ArrayList;
import java.util.Collection;
public class CollectionTest1 {
public static void main(String[] args) {
//多态
Collection W = new ArrayList();
// 自动装箱
W.add(200);
W.add(new Object());
// 自动装箱
W.add(true);
// 获取集合的元素
System.out.println(W.size());
// 清空集合
W.clear();
W.add("浩克");
System.out.println(W.contains("浩克"));
// 删除集合中特定元素
W.remove("浩克");
System.out.println(W.isEmpty());
W.add("皮卡丘");
W.add("大熊猫");
Object[] objs = W.toArray();
for(int i=0 ;iContains方法的进阶
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
public class ColletionTest2 {
public static void main(String[] args) {
Collection c = new ArrayList();//多态
c.add("abc");
c.add("100");
c.add("def");
c.add(100);
c.add(new Object ());
// 遍历
Iterator it = c.iterator();//获得迭代器
// 第二步:通过获得的迭代器遍历集合。
while(it.hasNext()){
Object obj = it.next();
System.out.println(obj);
}
}
}
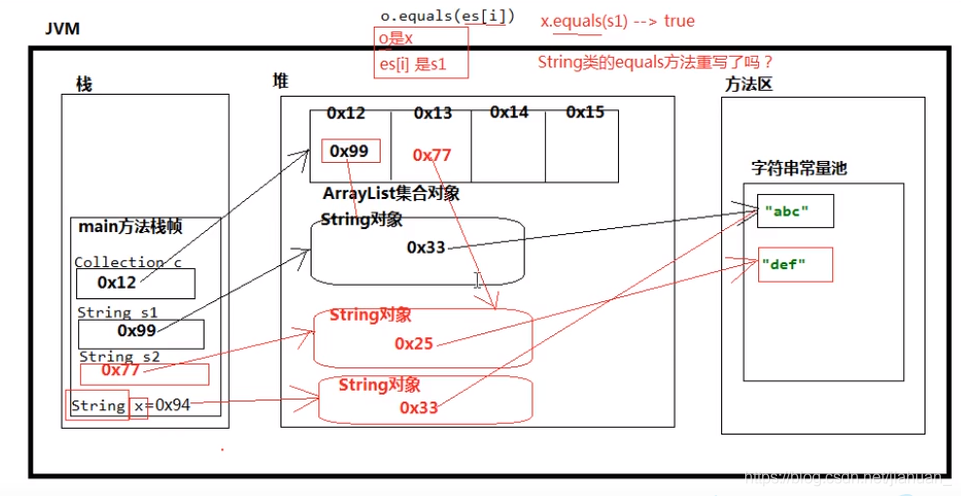
结论:放在集合里得元素得重写equals方法,如果没有重写比较的是内存地址,重写了比较的是内容,remove方法同理,也是跟comtains方法一样。import java.util.ArrayList;
import java.util.Collection;
public class CollectionTest4 {
public static void main(String[] args) {
Collection c =new ArrayList();
String u1 = new String("abc");
c.add(u1);
String u2 = new String ("abc");
c.remove(u2);
System.out.println(c.size());
}
}
5.iterator方法
Iterator为Iterable中的方法,被Collection接口继承。
解释:Collection接口以及子类调用父类Iterable方法:iterator();放回一个迭代器Iterator对象。(不要搞混哦,注意首字母的大小写,大小写不同,含义不同。)
迭代器的执行原理:
boolean hasNext()方法:如果还有元素可以迭代返回true.
Object next();这个方法让迭代器往前进一位,并且返回指向的元素。import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
public class ColletionTest2 {
public static void main(String[] args) {
Collection c = new ArrayList();//多态
c.add("abc");
c.add("100");
c.add("def");
c.add(100);
c.add(100);
c.add(new Object ());
// 遍历
Iterator it = c.iterator();//获得迭代器
// 第二步:通过获得的迭代器遍历集合。
while(it.hasNext()){
Object obj = it.next();
System.out.println(obj);
}
}
}
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class CollectionTest5 {
public static void main(String[] args) {
Collection c =new ArrayList();
c.add(15);
c.add("fas");
c.add(2222);
Iterator it = c.iterator();
while (it.hasNext()){
Object o = it.next();
it.remove();//用迭代对象的remove方法删除
System.out.println(o);
}
System.out.println(c.size());
}
}
6.List接口
有序可重复。
有下标。
List接口特有的常用方法:import java.util.*;
public class ListTest1 {
public static void main(String[] args) {
List myList = new LinkedList();
// List myList2 = new ArrayList();
// List myList3 = new Vector();
// 添加元素
myList.add("cad");
myList.add("dfsa");
myList.add(6656);
myList.add(6656);//默认在最后添加
myList.add(1,"King");//在指定位置添加元素
Iterator it = myList.iterator();
while (it.hasNext()){
Object o = it.next();
System.out.println(o);
}
// 获取特定元素
Object obj = myList.get(1);
System.out.println(obj);
// 获取指定对象最后一次出现的索引
System.out.println(myList.lastIndexOf(6656));
// 修改特定位置的元素
myList.set(0,"fdafasdf");
System.out.println(myList.get(0));
}
}
ArrayList集合类
如:new ArrayList(15);(构造方法)LinkedList集合类
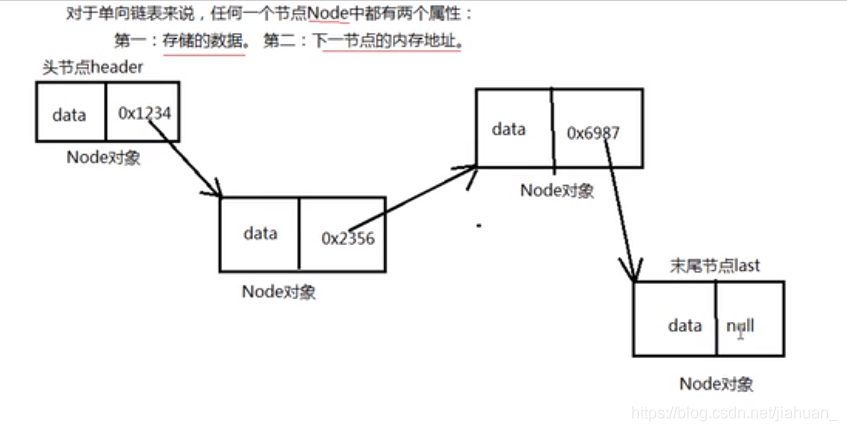
*缺点:单链表的存储地址不连续,插中间一个节点,需要从头节点开始查找,知道其上一个节点存储的地址才可。所以查找效率较低。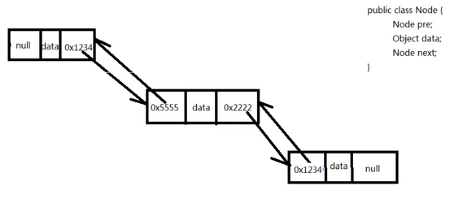
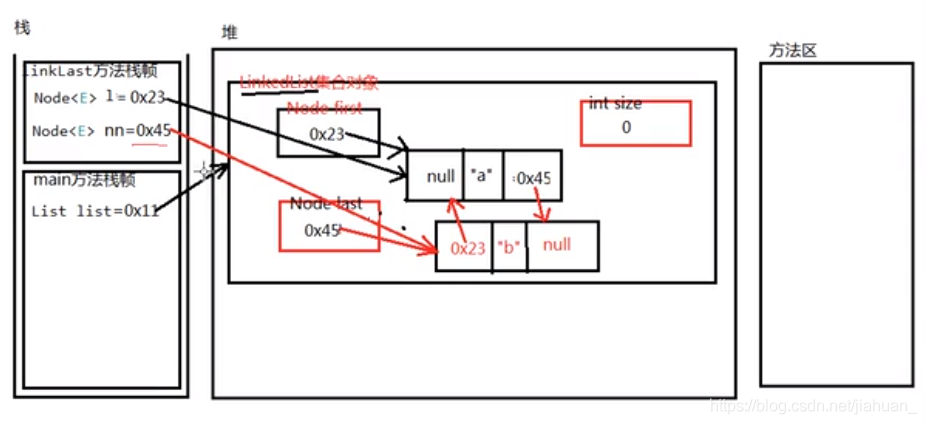
Vector集合类
那如何将非线程安全的转换成线程安全的呢?
1.java.util.Collections;
2.注意java.util.Collection 是集合接口。
但是:java.util.Collection是集合工具类。
练习:import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class VectorTest1 {
public static void main(String[] args) {
List myList = new ArrayList();
// 变成线程安全的
Collections.synchronizedList(myList);
myList.add("444");
System.out.println(myList.get(0));
}
}
7.Set接口的常用集合类
HashSet集合类
TreeSet集合类
import java.util.Set;
import java.util.TreeSet;
public class TreeSetTest1 {
public static void main(String[] args) {
Set8.Map接口
== Map集合中常用的方法:==
练习:public class MapTest2 {
public static void main(String[] args) {
//创建map集合对象
Map
package Day3;
import java.util.HashSet;
import java.util.Set;
public class MapTest1 {
// 声明静态内部类
private static class InnerClass{
public static void m1(){
System.out.println("静态方法m1执行!");
}
// 实例方法
public void m2(){
System.out.println("实例方法执行!");
}
}
public static void main(String[] args) {
MapTest1.InnerClass.m1();
MapTest1.InnerClass aa= new MapTest1.InnerClass();
aa.m2();
Set
第一种方法:获取所有的key,通过遍历key,遍历value,通过key,找value.
第二种方式:直接转换成Set集合。
Set集合中元素的类型是:Map.Entry.public class MapTest3 {
public static void main(String[] args) {
Map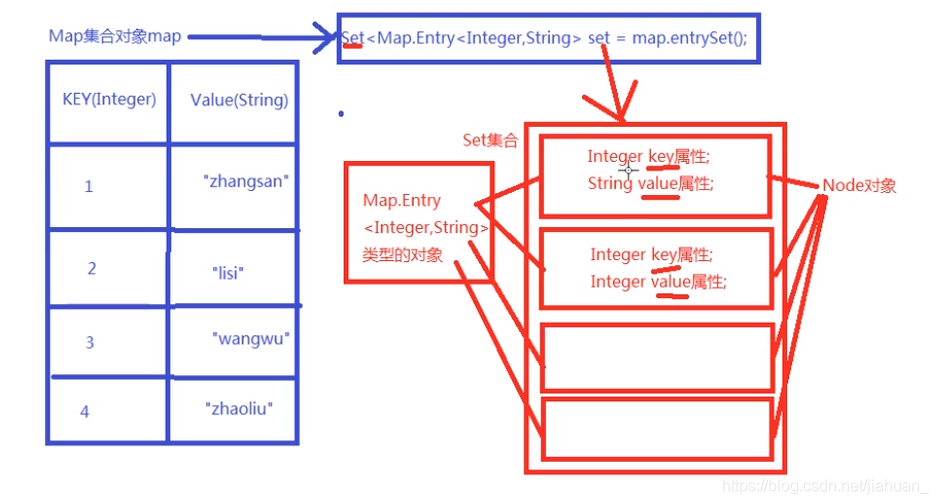
HashMap集合类
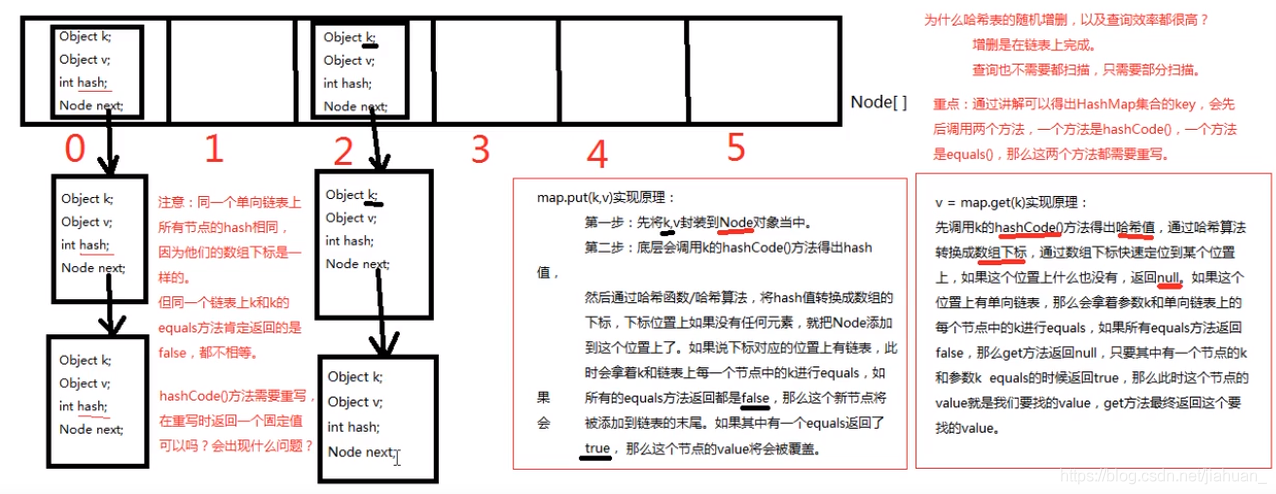
重点:重写放在HashMap集合key部分的元素和HashSet集合中的元素,需要同时重写hashCode和equals方法。public class HashMapTest1 {
public static void main(String[] args) {
MapHashtable集合类
Properties集合类
public class PropertiseTest1 {
public static void main(String[] args) {
Properties pro= new Properties();
pro.setProperty("url","dfaf");
pro.setProperty("fasd","fasd");
//通过key获取value
String a=pro.getProperty("url");
String b= pro.getProperty("fasd");
String c =pro.getProperty("url");
String d =pro.getProperty("fasd");
System.out.println(a);
System.out.println(b);
System.out.println(c);
System.out.println(d);
}
}
>
文章标题:一文搞定Java集合类,你还在为Java集合类而烦恼吗?
文章链接:http://soscw.com/index.php/essay/57699.html