Adversarial Latent Autoencoders(译文)
2021-03-01 11:26
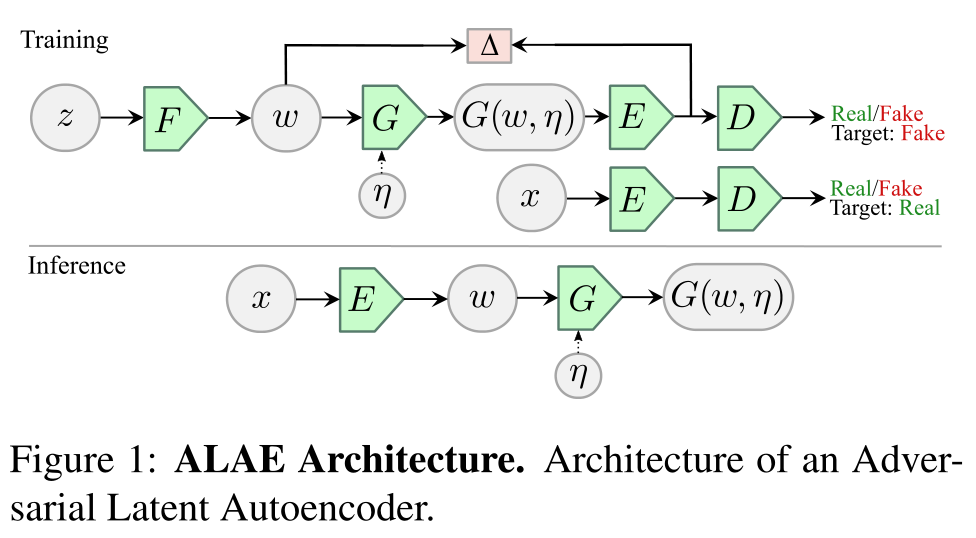
标签:分发 ima 规范化 归一化 建模 程序 ref alt 依赖 -论文地址 https://arxiv.org/abs/2004.04467 -项目源码 https://github.com/podgorskiy/ALAE 自动编码器网络是无监督的方法,旨在通过同时学习编码器-生成器映射来结合生成性和代表性。尽管进行了广泛的研究,但它们是否具有与遗传基因相同的生成能力,或者学习如何解开表征的问题还没有得到充分的解决。我们引入了一种联合处理这些问题的自动编码器,我们称之为对抗性潜在自动编码器(ALAE)。这是一个通用的架构,可以利用最近对GAN训练程序的改进。我们设计了两个自动编码器:一个基于MLP编码器,另一个基于样式生成器,我们称之为StyleALAE。我们验证了两种架构的解纠缠特性。实验结果表明,StyleALAE不仅可以生成1024×1024的人脸图像,具有与StyleGAN相当的质量,而且在相同的分辨率下还可以生成基于真实图像的人脸重建和操作。这使得ALAE成为第一个能够与一代架构相比并超越其能力的自动编码器。 生成对抗网络(GAN) [13]已经成为计算机视觉和其他领域中占主导地位的无监督方法之一。它们的优势与它们表现复杂概率分布的非凡能力有关,如面部流形[33]或卧室图像流形[53],它们通过从数据空间的已知分布中学习生成器图来实现。同样重要的是旨在从数据到潜在空间学习编码器映射的方法。它们允许以有监督的[29,46,40,14,52]或无监督的[37,58,19,25,4,3]方式学习手头任务的适当数据表示。 上述观察启发了所提出的方法。我们设计了一个不良事件架构,允许从数据中学习潜在的分布来解决纠缠。输出数据分布是通过对抗策略(B)学习的。因此,我们保留了基因的生殖特性,以及在该领域最新进展的基础上进行构建的能力。例如,我们可以无缝地包含独立的随机性来源,这已被证明对生成图像细节至关重要,或者可以利用GAN损失函数、正则化和超参数调整的最新改进[2,30,38,34,36,3]。最后,为了实现(A)和(B),我们在潜在空间(C)中施加AE互易。因此,我们可以避免使用基于在数据空间中操作的简单l2范数的重建损失,在数据空间中,重建损失通常是次优的,例如对于图像空间。我们认为(甲)、(乙)和(丙)的独特组合是该方法的主要技术创新和优势。由于它在潜在空间工作,而不是对数据空间进行自动编码,我们将其命名为对抗性潜在自动编码器(ALAE)。 我们设计了两个ALAEs,一个是用多层感知器(MLP)和对称发生器作为编码器,另一个是用从StyleGAN [24]得到的发生器,我们称之为StyleALAE。为此,我们设计了一个配套编码器和一个不断发展的架构。我们定性和定量地验证了这两种架构都学习了一个比复合架构更清晰的潜在空间。此外,我们还展示了面部和卧室图像生成的定性和定量结果,这些结果可与最高分辨率为1024 × 1024的StyleGAN相媲美。由于StyleALAE还学习了编码器网络,我们能够以最高分辨率显示人脸重建以及基于真实图像而不是生成的若干图像处理。 我们的方法直接建立在普通的GAN架构上[12]。此后,在合成图像生成领域取得了许多进展。LAPGAN [5]和StackGAN [55,56]训练一堆以多分辨率金字塔组织的GANs,以生成高分辨率图像。HDGAN [57]通过在网络层次结构中加入层次嵌套的敌对目标进行了改进。在[51]中,他们使用多尺度发生器和鉴别器架构,以语义标签图为条件,用GAN合成高分辨率图像,而在BigGAN [3]中,他们通过应用更好的正则化技术来改进合成。在PGGAN [23]中,我展示了如何通过逐步增加GAN的发生器和鉴别器来合成高分辨率图像。StyleGAN [24]中使用了相同的原理,这是当前最先进的人脸图像生成技术,我们在这里将其应用于我们的StyleALAE架构。最近关于遗传神经网络的其他工作集中在提高训练的稳定性和鲁棒性上[44]。引入了新的损失函数[2],以及梯度正则化方法[39,36],权重归一化技术[38]和学习速率均衡[23]。正如我们在后面的章节中所解释的,我们的框架可以接受这些改进。 GAN 我们引入了一种新的自动编码器结构,通过修改原来的GAN范式。我们首先把发生器G和鉴别器D分别分解成两个网络:F,G,和E,D。这意味着 其中qG(x|w,η)表示g的条件分布。类似地,对于E的输出,分布变为 其中qE(w|x)是表示E的条件分布,在(4)中,如果我们用pD(x)代替q(x),我们得到分布qE,D(w),它描述了当真实数据分布是E的输入时E的输出。 通过这种方式,我们可以将网络对(G,E)解释为自动编码潜在空间的生成器-编码器网络。如果我们用\(Δ(p||q)\)表示两个分布p和q之间的差异的度量,我们建议通过交替使用以下两种优化来调整GAN损耗(1)来实现目标(5) 其中Δ的左右参数表示映射p(z)的网络生成的分布,分别对应于qF(w)和qE(w)。我们将根据(6) (7)优化的网络称为对抗性潜在自动编码器(ALAE)。ALAE架构的构建模块如图1所示。 数据分发。在由编码器网络和生成器网络组成的架构中,编码器的任务是将输入数据映射到以潜在分布为特征的空间上,而生成器的任务是将潜在代码映射到由数据分布描述的空间上。不同的策略用于学习数据分布。例如,一些方法对生成器的输出施加相似性标准[28,41,35,48],或者甚至学习相似性度量[31]。取而代之的是其他技术,建立一个对抗性的游戏,以确保生成器输出与训练数据分布相匹配[6,9,47,49,20]。后一种方法是我们用于ALAE的方法。 互惠。自动跟踪器的另一个方面是它们是否以及如何实现互惠。这个属性与架构从代码w重建数据样本x的能力有关,反之亦然。显然,这要求 在潜在空间中强加互惠性具有显著的优势,简单的L2、L1或其他规范可以有效地使用,而不管它们是否不适合数据空间。例如,众所周知,图像像素差异的元素L2范数不反映人类的视觉感知。另一方面,当用于潜在空间时,它的意思是不同的。例如,一个像素的图像平移可能导致图像空间中的大L2差异,而在潜在空间中,其表示几乎不会改变。最终,在图像空间中使用L2被认为是自动编码器在重建/生成清晰图像方面不如GANs成功的原因之一[31]。解决同一个问题的另一种方法是敌对地强加互惠,如[6,9]所示。表1总结了大多数最新一代编码器架构的主要特征。 我们使用ALAE构建了一个自动编码器,它使用了一个基于StyleGAN的生成器。为此,我们使我们的潜在空间W起到与[24]中的中间潜在空间相同的作用。因此,我们的G网络成为了图2右侧所示的StyleGAN的一部分。左侧是一个新颖的架构,我们将它设计为编码器E. 因为在每一层,G都是由样式输入驱动的,所以我们对称地设计E,以便从相应的层中提取样式信息。我们通过插入实例标准化(IN)层[21]来做到这一点,它为每个通道提供实例平均值和标准偏差。具体来说,如果yE是E的第I层的输出,则IN模块提取代表该层风格的统计量μ(yEi)和σ(yEi)。输入模块还提供输入的标准化版本作为输出,该版本在管道中继续,没有来自该级别的更多样式信息。给定E和G之间的信息流,该架构有效地模仿了从E到G的多尺度风格转换,不同之处在于没有额外的输入图像来提供内容[21,22]。 其中,Ci是可学习的参数,N是层数。 Adversarial Latent Autoencoders(译文) 标签:分发 ima 规范化 归一化 建模 程序 ref alt 依赖 原文地址:https://www.cnblogs.com/bwpenguin/p/14412193.html对抗性潜在自动编码器(ALAE)
摘要
1 引言
自动编码器(AE) [28,41]网络是无监督的方法,旨在通过同时学习编码器-发生器映射来结合“生成性”和“代表性”属性。自动编码器结构研究的一般问题是它们是否能够:(a)具有与GANs相同的生成能力;和(b)学习解开表示[1]。有几部作品涉及(a) [35,31,6,9,20]。一个成功的重要试验是AE生成的人脸图像能够像GAN一样丰富和清晰[23]。已经取得了进展,但还没有宣布胜利。相当多的工作也涉及(b) [19,25,10],但不是与(a)一起。
我们引入了一种通用的AE结构,其生成能力可与GANs相媲美,同时学习了一种不太复杂的表示。我们观察到,每种AE方法都做出相同的假设:潜在空间应该具有先验固定的概率分布,并且自动编码器应该与之匹配。另一方面,在[24]中,已经显示了用GANs生成合成图像的最先进的技术,即中间潜在空间,离强加的输入空间足够远,往往具有改善的解缠结特性。2 相关工作
变化的AE体系结构[28,41]不仅因其理论基础,还因其在训练过程中的稳定性以及提供有洞察力的表示的能力而受到赞赏。事实上,它们刺激了解缠领域的研究[1],允许在[19]和[25]中随后的改进中以受控的解缠程度学习表征,导致解缠量化的更精细的度量[10,4,24],我们也用它来分析我们方法的性质。v不良事件还被扩展到学习不同于正态分布的潜在先验,从而获得显著更好的模型[48]。在结合全球网络和虚拟企业的优势方面已经取得了很大进展。AAE [35]是这些方法的先驱,其次是更直接的方法。甘比[6]和阿里[9]提供了一个优雅的完全对抗的框架,而韦根[47]和AGE [49]率先使用了自动编码的潜在空间,并倡导降低体系结构的复杂性。PIONEER [15]和IntroV AE [20]遵循这一路线,后者在这一类别中提供了最好的世代结果。第4.1节描述了提议的方法与这里列出的方法的比较。
最后,我们很快会提到在表示图像数据分布方面显示出有希望的结果的其他方法。这些方法包括自回归[50]和基于流量的方法[27]。前者放弃了潜在表象的使用,但后者没有。3 预备知识
4 对抗性潜在自动编码器
G = G o F,D = D o E,(2)见图1。此外,我们假设F和G之间以及E和D之间的界面上的潜在空间是相同的,并且我们将它们表示为w。在最一般的情况下,我们假设F是确定性映射,而我们允许E和G是随机的。特别地,我们假设G可能可选地依赖于独立的噪声输入η,具有已知的固定分布ρ(η)。我们用G(w,η)表示这个更一般的随机发生器。
在上述条件下,我们现在考虑每个网络输出端的分布。网络F只是把p(z)映射到qF(w)上。在G的输出端,分布可以写成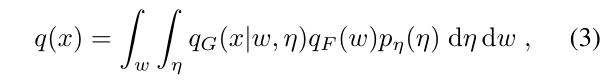
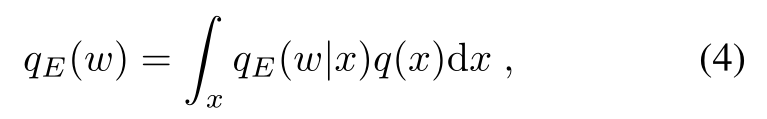
由于优化(1)会导致合成分布与真实分布相匹配,即q(x) = pD(x),因此从(4)中可以明显看出,这样做也会导致qE(w) = qE,D(w)。除此之外,我们建议确保E的输出分布与g的输入分布相同。这意味着我们建立了一个额外的目标,它要求qF(w) = qE(w)。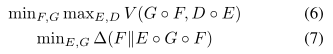
4.1 与其他自动编码器的关系
潜在分布。相反,对于潜在空间,通常的做法是设置期望的目标潜在分布,然后训练编码器通过最小化相似性的发散类型[28,41,31,47,48],或者通过建立对抗游戏[35,6,9,49,20]来匹配它。在这里,ALAE采取了一种完全不同的方法。事实上,我们并不强加潜在分布,即qE(w),以匹配目标分布。我们设置的唯一条件,由(5)给出。换句话说,我们不想让F成为特征映射,我们非常有兴趣让学习过程来决定F应该是什么。x = G(E(x)),或者等价于w = E(G(w))。在第一种情况下,网络必须包含在数据空间中运行的重构项。在后一种情况下,该术语在潜在空间中起作用。虽然大多数方法遵循第一个策略[28,41,35,31,20,48],但也有一些方法实现了第二个策略[47,49],包括ALAE。实际上,这可以通过选择(7)中的散度作为预期的编码重构误差来实现,如下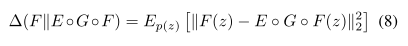
5 StyleALAE
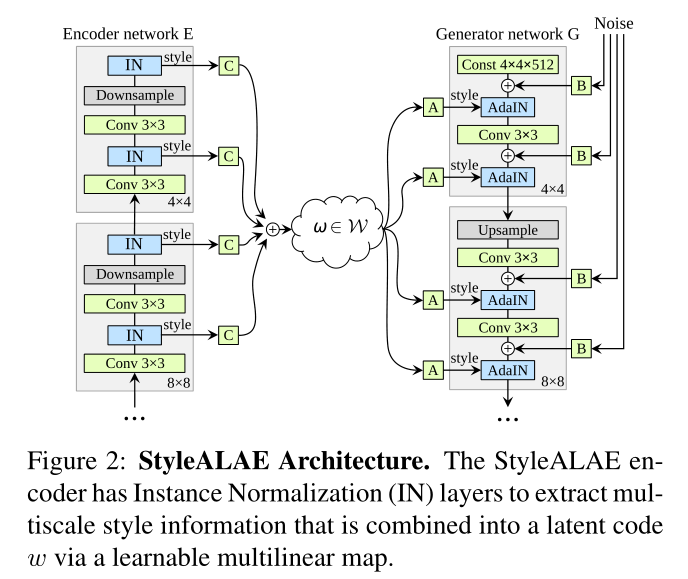
作为自适应实例规范化(AdaIN)图层[21]输入的样式集与潜在变量w线性相关。因此,我们建议将编码器输出的样式组合起来,并通过以下多线性映射w = N将其映射到潜在空间。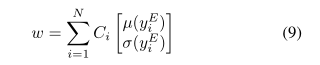
与[23,24]类似,我们使用渐进增长。我们从低分辨率图像(4×4像素)开始,通过平滑地将新块混合到E和G中来逐步提高分辨率。对于F和D网络,我们使用MLP来实现它们。在我们所有的实验中,z和w空间以及F和D的所有层都具有相同的维数。而且,对于StyleALAE我们遵循[24],选择F有8层,我们设置D有3层
文章标题:Adversarial Latent Autoencoders(译文)
文章链接:http://soscw.com/index.php/essay/58530.html