算法刷题及总结_数组篇拓展
2021-03-02 22:26
标签:spi 空格替换 复杂 多个 思维 ash load duplicate stat 在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。 没什么好说的,暴力法,双循环解决。[]( ̄▽ ̄)* 由于采用了双循环依次比较相互之间两个元素,所以时间复杂度显而易见为O(n^2),空间复杂度为O(1)。当然,因为已知2
在暴力解法中,我们先遍历每一个元素,然后再从其余的元素中查找这个元素是否存在,其实这里要的就是能高效的判断一个元素是否已经存在,我们可以使用哈希表,因为哈希表判断是否存在的时间复杂度是 O(1)。 伪代码 以上算法实现的复杂度分析:时间复杂度是 O(n),空间复杂度是 O(n)。 数组代替哈希表。在题目中,有一个信息,我们需要注意下,那就是数组中每个元素的大小在 0 ~ n - 1 的范围内。利用这个信息,我们就可以使用数组代替上面方案二的哈希表,主要的思路见伪代码。 伪代码 以上算法实现的复杂度分析:时间复杂度是 O(n),空间复杂度是 O(n)。 原地置换:对于这种数组元素在 [0, n-1] 范围内的问题,可以将值为 i 的元素调整到第 i 个位置上进行求解。(此种思想很重要( ̄▽ ̄)/)在调整过程中,如果第 i 位置上已经有一个值为 i 的元素,就可以知道 i 值重复。当然,对于本题变种(需要指出第一个重复出现的数字)就可能会无法通过全部case,因为这个调换元素的过程是随机的,而且本身数组中元素排列也是随机的,无法确保选出的数字是第一个出现的数字。 由上面思路不难分析得出,时间复杂度 O(N),空间复杂度 O(1)。综上所述,此为最优解法。 可能有人会有疑问,nums[nums[i]]这里,如果nums[i]是一个特别大的数字,不会导致数组越界异常吗?其实这里题目做了一个限制,数组元素在 [0, n-1] 范围内。所以同学们得好好读题,如果没有这个限制,确实会出现问题的哦~ 在一个 n * m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个高效的函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。 没什么好说的,毫无技术含量的暴力法,双循环解决。[]( ̄▽ ̄)*对了,由于本题涉及到二维数组,所以在对m进行赋值时,及求二维数组的列时,必须先判断二维数组是否为空或者说二维数组的行大于0。 以上代码的复杂度分析是:时间复杂度是 O(nm),空间复杂度是 O(1)。继续优化吧╮(╯▽╰)╭ 二分法。走火入魔了,这种方法也是本人第一想法。在看到本题描述的数组特性,从左到右是依次递增的,那么可以看成是多个排序好的一维数组,所以可以分成多个二分法的小问题。 伪代码 根据以上算法不难分析,其时间复杂度为O(nlogm),空间复杂度为O(1)。 如果本题所描述的数组为每行从左到右依次递增,并且每行的第一个整数大于上一行最后一个整数。那么本题直接可以采用二分法,而且是最优解法。其时间复杂度为O(logn)。因为所有行可以单独拆分再组合排列成一条从左到右递增,依次排列的大的一维数组。这不是重点,重点是确定具体的元素与给定的目标元素对比的过程,细节见代码。比较巧妙的方法,随时复习~ 线性查找。 由于给定的二维数组具备每行从左到右递增以及每列从上到下递增的特点,当访问到一个元素时,可以排除数组中的部分元素。从二维数组的右上角或者左下角开始查找。如果当前元素等于目标值,则返回 true。如果当前元素大于目标值,则移到左边一列。如果当前元素小于目标值,则移到下边一行。 伪代码 若数组为空,返回 false 初始化行下标为 0,列下标为二维数组的列数减 1 重复下列步骤,直到行下标或列下标超出边界 获得当前下标位置的元素 num 如果 num 和 target 相等,返回 true 如果 num 大于 target,列下标减 1 如果 num 小于 target,行下标加 1 循环体执行完毕仍未找到元素等于 target ,说明不存在这样的元素,返回 false。 时间复杂度:O(n+m)。访问到的下标的行最多增加 n 次,列最多减少 m 次,因此循环体最多执行 n + m 次。 其实本题方法三可以以另外一种思路看待,殊途同归。如下图所示,我们将矩阵逆时针旋转 45° ,并将其转化为图形式,发现其类似于 二叉搜索树 ,即对于每个元素,其左分支元素更小、右分支元素更大。因此,通过从 “根节点” 开始搜索,遇到比 target 大的元素就向左,反之向右,即可找到目标值 target 。算法和代码与方法三是一样的,就不展示了,理解一下思路。 “根节点” 对应的是矩阵的 “左下角” 和 “右上角” 元素,本文称之为 标志数 ,以 matrix 中的 左下角元素 为标志数 flag ,则有: 若 flag > target ,则 target 一定在 flag 所在 行的上方 ,即 flag 所在行可被消去。 利用字符串的replace方法。取巧,无意义,掌握方法本身。 由于每次替换从 1 个字符变成 3 个字符,使用字符数组可方便地进行替换。建立字符数组地长度为 s 的长度的 3 倍,这样可保证字符数组可以容纳所有替换后的字符。算法很简单,我就不赘述伪代码了。 利用StringBuffer,即动态字符串数组存储和改变字符串内容。通过遍历先找出所有空格,统计数量,为字符串分配合适的空间并随机分配字符(空格即可)。然后遍历确保每个空格都被02%替换。 伪代码 在字符串尾部填充任意字符,使得字符串的长度等于替换之后的长度。因为一个空格要替换成三个字符(%20),所以当遍历到一个空格时,需要在尾部填充两个任意字符。 令 P1 指向字符串原来的末尾位置,P2 指向字符串现在的末尾位置。P1 和 P2 从后向前遍历,当 P1 遍历到一个空格时,就需要令 P2 指向的位置依次填充 02%(注意是逆序的),否则就填充上 P1 指向字符的值。从后向前遍是为了在改变 P2 所指向的内容时,不会影响到 P1 遍历原来字符串的内容。 当 P2 遇到 P1 时(P2
时间复杂度 O(n): 遍历统计、遍历修改皆使用 O(n)时间。 输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。 根据题目示例 matrix = [[1,2,3],[4,5,6],[7,8,9]] 的对应输出 [1,2,3,6,9,8,7,4,5] 可以发现,顺时针打印矩阵的顺序是 “从左向右、从上向下、从右向左、从下向上” 循环。因此,考虑设定矩阵的“左、上、右、下”四个边界,模拟以上矩阵遍历顺序。 伪代码 时间复杂度 O(MN) : M, N 分别为矩阵行数和列数。 本题不涉及很多算法,但是需要对于边界界定有一个清晰的认识,这也是模拟过程的关键。所以注意i++和++i的区别,并且if判断语句也是另外一个关键点,控制行列。同时前面曾经总结过一个类似的螺旋矩阵,注意两者之间的区别。综上,注意小细节问题~ 在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。 s 只包含小写字母。 通过题意可以知道,本题需要统计每个字符的出现次数并且能够进行遍历。第一时间应该想到的就是利用哈希表。以字符为key,出现的次数设为value,建立键值对,记录信息。可以利用containsKey()方法来区别字符出现在次数。如果是首次出现,就将该key对应的value设为true;反之设为false,则表明已经出现过了。在将所有字符的出现信息记录完毕之后,从头遍历哈希表确认第一个只出现过一次的字符并返回即可。如图所示。 伪代码 利用HashMap初始化字典,记为 dic ; 遍历字符串 s 中的每个字符 c,字符统计 ; 建立键值对关系: 若dic中不包含键(key)c :则向dic中添加键值对(c, True) ,代表字符c的数量为1; 若dic中包含键(key)c :则修改键c的键值对为(c, False) ,代表字符c的数量>1 。 查找数量为1的字符:遍历字符串s中的每个字符c; 若dic中键c对应的值为True则返回c。 返回 ‘ ‘ ,代表字符串中无数量为1的字符。 时间复杂度 O(n):n为字符串s的长度;需遍历s两轮,使用 O(n);HashMap查找操作的复杂度为O(1); 考虑到要统计的字符范围有限,也可以使用整型数组代替 HashMap。ASCII 码只有128个字符,虽然本题只涉及小写字母,但是为了能够存储方便,使用长度为128的整型数组来存储每个字符出现的次数(因为a对应的ASCII码为97,后面会表示到z,所以相应的数组也得有这个范围,不然会出现数组越界异常)。原理同方法一,但是可以学习此种思想。 时间复杂度 O(n):n为字符串s的长度;需遍历s两轮,使用 O(n); 在哈希表的基础上,有序哈希表中的键值对是按照插入顺序排序的。基于此,可通过遍历有序哈希表,实现搜索首个 “数量为1的字符”。哈希表是去重的,即哈希表中键值对数量≤字符串s的长度。因此,相比于方法一,此方法减少了第二轮遍历的循环次数。当字符串很长(重复字符很多)时,方法三则效率更高。在Java中使用LinkedHashMap实现有序哈希表。 时间复杂度 O(n):n为字符串s的长度;需遍历s一轮,使用 O(n); 以上均为《剑指offer》中有关数组题目的集中总结,后续数组篇估计会有更新,敬请期待。(????)?""" 算法刷题及总结_数组篇拓展 标签:spi 空格替换 复杂 多个 思维 ash load duplicate stat 原文地址:https://www.cnblogs.com/masterYHH/p/14401987.html算法刷题及总结_数组篇拓展
1.剑指 Offer 03. 数组中重复的数字【难度指数:★☆☆】
题目描述
示例 1:
输入:
[2, 3, 1, 0, 2, 5, 3]
输出:2 或 3
限制:
2 方法一(暴力法)
解题思路
代码实现
public static boolean duplicate(int[] nums,int[] duplication) {
for (int i = 0; i 算法分析
方法二(哈希表)
解题思路
代码实现
public static boolean duplicate(int[] nums,int[] duplication) {
// 初始化一个哈希表
Set算法分析
时间复杂度 O(n),对于数据规模 10 万级别的话,运行速度是可以接受的。但是这里的空间复杂度则变为 O(n),因为哈希表需要申请额外的 n 个空间,这里用到的是典型的空间换时间的思想。
方法三(数组代替哈希表)
解题思路
代码实现
public static boolean duplicate(int[] nums,int[] duplication) {
// 初始化一个数组
int[] bucket = new int[nums.length];
Arrays.fill(bucket, -1);
for (int i = 0; i 算法分析
可以看出,时间复杂度和空间复杂度都是和用哈希表的解决方案是一样的。但是使用数组绝对会有性能的提高,主要表现在如下的两个方面:
方法四(原地置换)
解题思路
代码实现
public static boolean duplicate(int[] nums,int[] duplication) {
for (int i = 0; i 算法分析
值得注意
2.剑指 Offer 04. 二维数组中的查找 【难度指数:★★☆】
题目描述
示例:
现有矩阵 matrix 如下:
[
[1, 4, 7, 11, 15],
[2, 5, 8, 12, 19],
[3, 6, 9, 16, 22],
[10, 13, 14, 17, 24],
[18, 21, 23, 26, 30]
]
给定 target = 5,返回 true。
给定 target = 20,返回 false。
限制:
0 方法一(暴力法)
解题思路
代码实现
public boolean findNumberIn2DArray(int[][] matrix, int target) {
int m = matrix.length;
if (m == 0) return false;
int n = matrix[0].length;
for (int i = 0; i 算法分析
方法二(二分法)
解题思路
代码实现
public boolean findNumberIn2DArray(int[][] matrix, int target) {
int n = matrix.length;
int m = 0;
if (n > 0) {
m = matrix[0].length;
}
for (int i = 0; i target) {
right = middle - 1;
}
else if (matrix[i][middle] 算法分析
思维拓展
public boolean searchMatrix(int[][] matrix, int target) {
int m = matrix.length;
if (m == 0) return false;
int n = matrix[0].length;
int left = 0;
int right = m * n - 1;
while (left 方法三(线性查找)
解题思路
代码实现
public boolean findNumbersIn2DArray(int[][] matrix, int target) {
int m = matrix.length;
if (m = 0 && j target) {
i--;
}
else {
return true;
}
}
return false;
}
算法分析
空间复杂度:O(1)。
思维拓展(二叉搜索树)
若 flag 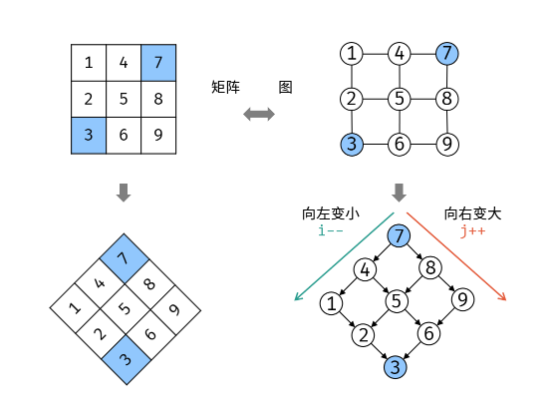
时间复杂度 O(m+n):其中,n和m分别为矩阵行数和列数,此算法最多循环 m+n次。
空间复杂度 O(1) : i, j 指针使用常数大小额外空间。
3.剑指 Offer 05. 替换空格 【★☆☆】
题目描述
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例 1:
输入:s = "We are happy."
输出:"We%20are%20happy."
方法一
解题思路
代码实现
public String replaceSpace(String s) {
return s.replace(" ", "%20") ;
}
方法二(字符数组)
解题思路
代码实现
public String replaceSpace(String s) {
//确保所有字符能够都转换成%20的形式,并且存放在大小合适的字符数组里面
char[] array = new char[length * 3];
int size = 0;
for (int i = 0; i 算法分析
方法三(原地修改)
解题思路
代码实现
public String replaceSpace(StringBuffer str) {
int P1 = str.length() - 1;
for (int i = 0; i = 0 && P2 > P1) {
char c = str.charAt(P1--);
if (c == ‘ ‘) {
str.setCharAt(P2--, ‘0‘);
str.setCharAt(P2--, ‘2‘);
str.setCharAt(P2--, ‘%‘);
} else {
str.setCharAt(P2--, c);
}
}
return str.toString();
}
算法分析
空间复杂度 O(1) : 由于是原地扩展 s 长度,因此使用 O(1)额外空间。
值得注意
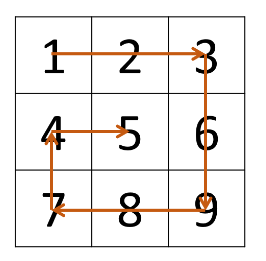
4.剑指 Offer 29. 顺时针打印矩阵【★☆☆】
题目描述
示例 1:
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
示例 2:
输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
输出:[1,2,3,4,8,12,11,10,9,5,6,7]
方法(模拟)
解题思路
代码实现
public int[] spiralOrder(int[][] matrix) {
if ( matrix.length == 0 || matrix == null) {
return new int[0];
}
// 分别表示上下左右四个分界
int left = 0;
int top = 0;
int right = matrix[0].length - 1;
int bottom = matrix.length - 1;
int size = 0;
int[] arr = new int[(right + 1) * (bottom + 1)];
while (true) {
// left——>right
for (int i = left; i bottom) {
break;
}
// top——>bottom
for (int i = top; i left
for (int i = right; i >= left; i--) {
arr[size++] = matrix[bottom][i];
}
if (--bottom top
for (int i = bottom; i >= top; i--) {
arr[size++] = matrix[i][left];
}
if (++left > right) {
break;
}
}
return arr;
}
算法分析
空间复杂度 O(1): 四个边界 left , right , top , bottom使用常数大小的额外空间(arr为必须使用的空间)。
值得注意
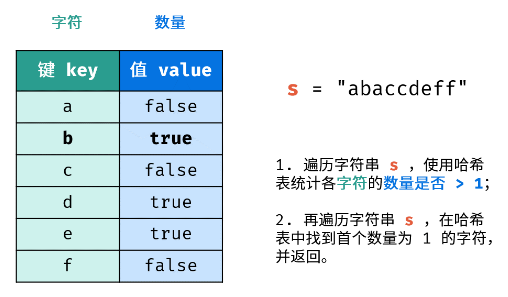
5.剑指 Offer 50. 第一个只出现一次的字符【★☆☆】
题目描述
示例:
s = "abaccdeff"
返回 "b"
s = ""
返回 " "
方法一(哈希表)
解题思路
代码实现
public char firstUniqChar(String s) {
HashMap算法分析
空间复杂度 O(1):由于题目指出s只包含小写字母,因此最多有26个不同字符,HashMap存储需占用O(26) = O(1)的额外空间。
方法二(整型数组代替哈希表)
解题思路
代码实现
public int FirstNotRepeatingChar(String str) {
int[] cnts = new int[128];
for (int i = 0; i 算法分析
空间复杂度 O(1):由上文分析,整型数组只需要O(128)的额外辅助空间,即O(1)。
除此之外,这种思想可以拓展到其他题目,比如需要某个字符的精确次数或者字符本身,此方法都可以进行判断和求解。
方法三(有序哈希表)
解题思路
代码实现
public char firstUniqChar(String s) {
//初始化
Map算法分析
空间复杂度 O(1):由上文分析,遍历有序哈希表只需要O(26)的额外辅助空间,即O(1)。