Windows使用Ik分词器插件
2021-03-03 21:27
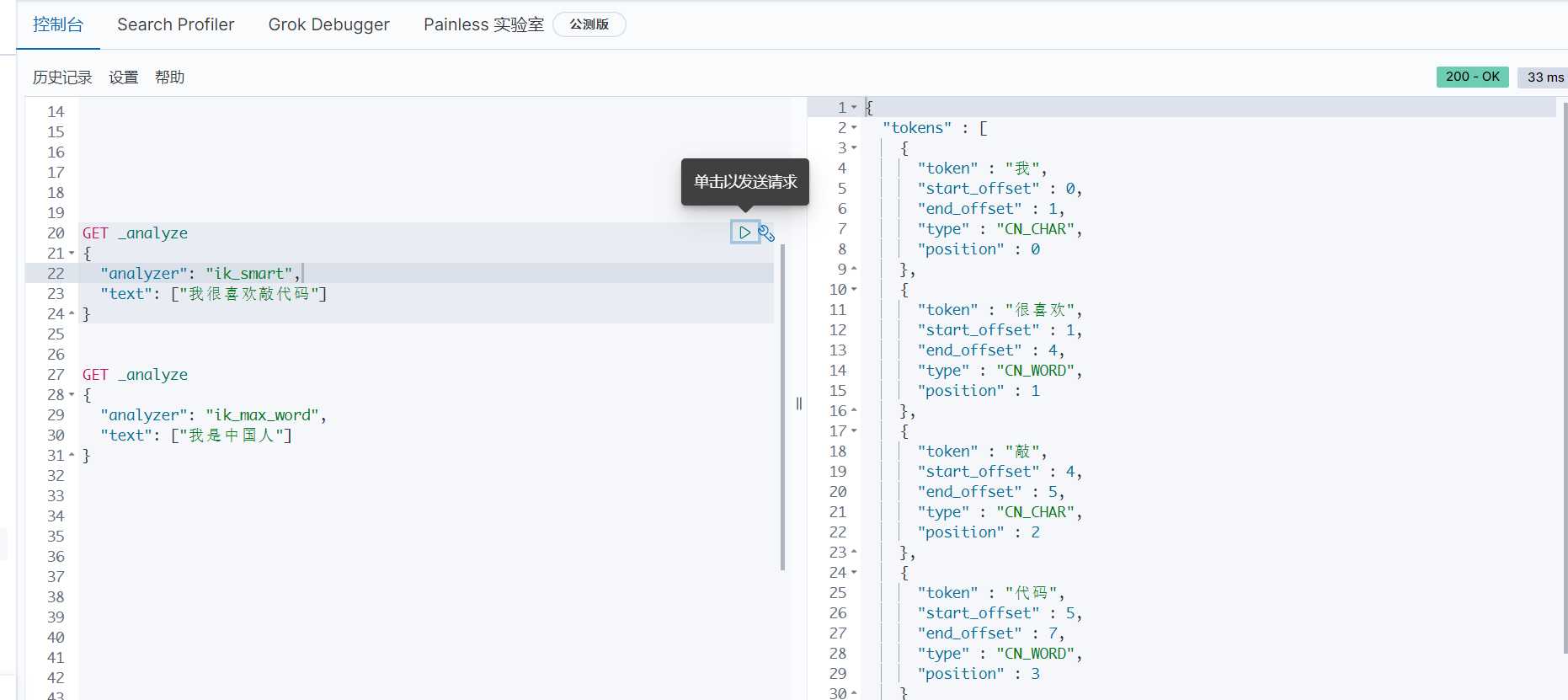
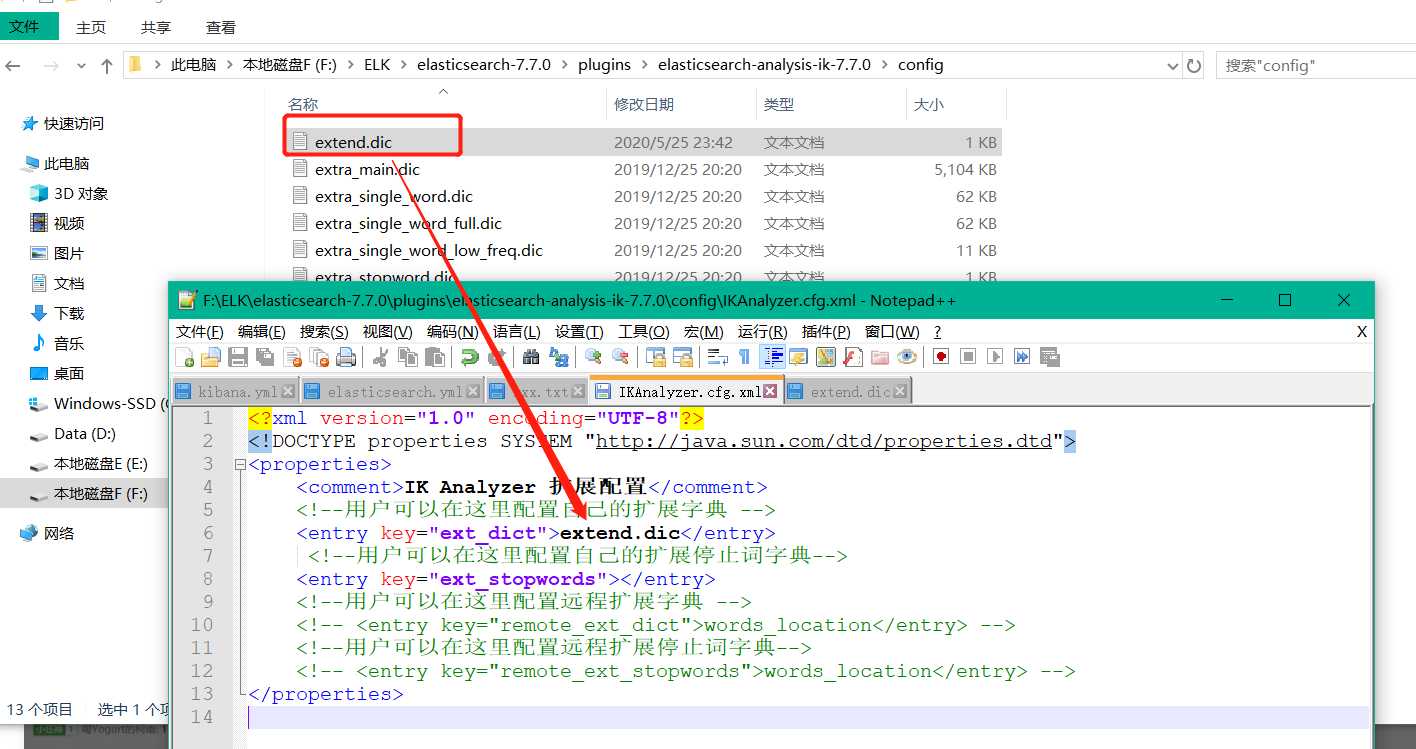
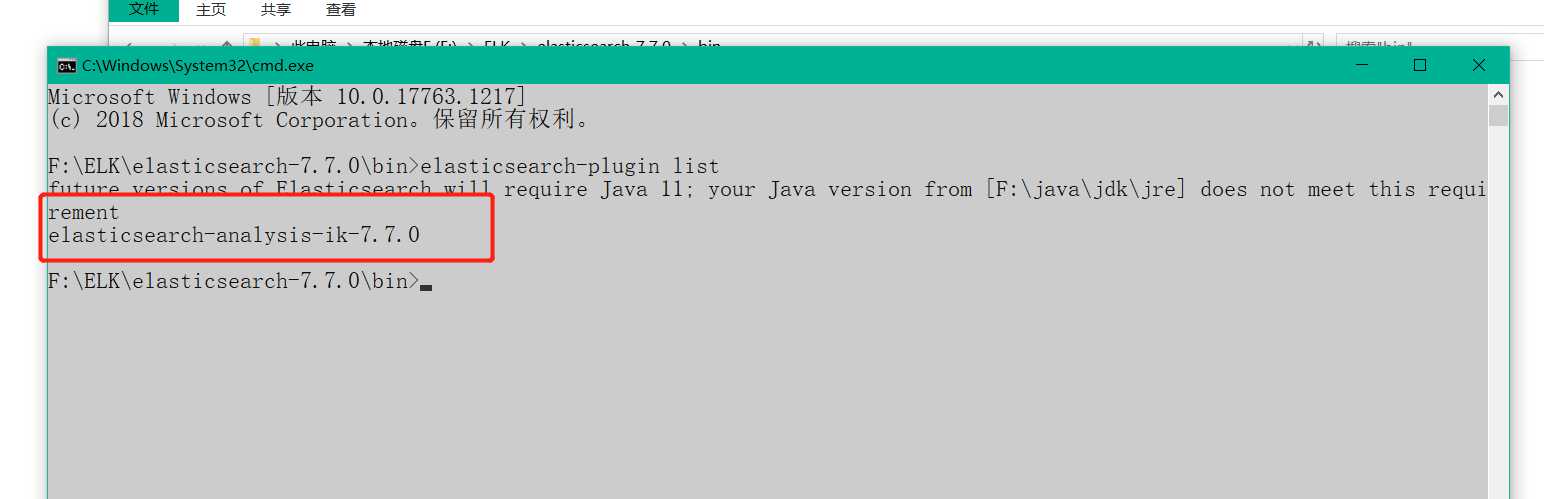
标签:自己的 arc ref info 需要 技术 中国人 信息 github 什么是Ik分词器? 分词:即把一段中文或者别的划分成一个个关键字,我们在搜索的的时候回把自己的信息进行分词,回把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词。 Ik分词器两种分词模式: 安装 下载安装 https://github.com/medcl/elasticsearch-analysis-ik/releases ,解压到 elasticsearch下的plugin目录,重启加载即可,可以看到Ik分词器被加载了。 可以通过 elasticsearch-plugin 命令查看加载进来的插件: 查看不同的分词效果,其中 ik_smart 为最少分词效果 ik_max_word 为最细粒度划分!穷尽词库的可能! 我们输入 “我很喜欢敲代码“,发现 ”敲代码“ 三个字被拆开了。 类似这种需要的次,我们需要自己加入到我们的分词字典当中! 保存完成之后重启 Es和Kibana 访问即可! Windows使用Ik分词器插件 标签:自己的 arc ref info 需要 技术 中国人 信息 github 原文地址:https://www.cnblogs.com/leizzige/p/12961820.htmlIK分词器插件
ik_max_word: 会将文本做最细粒度的拆分,比如会将"中华人民共和国国歌"拆分为"中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌",会穷尽各种可能的组合;ik_smart: 会做最粗粒度的拆分,比如会将"中华人民共和国国歌"拆分为"中华人民共和国,国歌"。
在Kibana中使用分词器
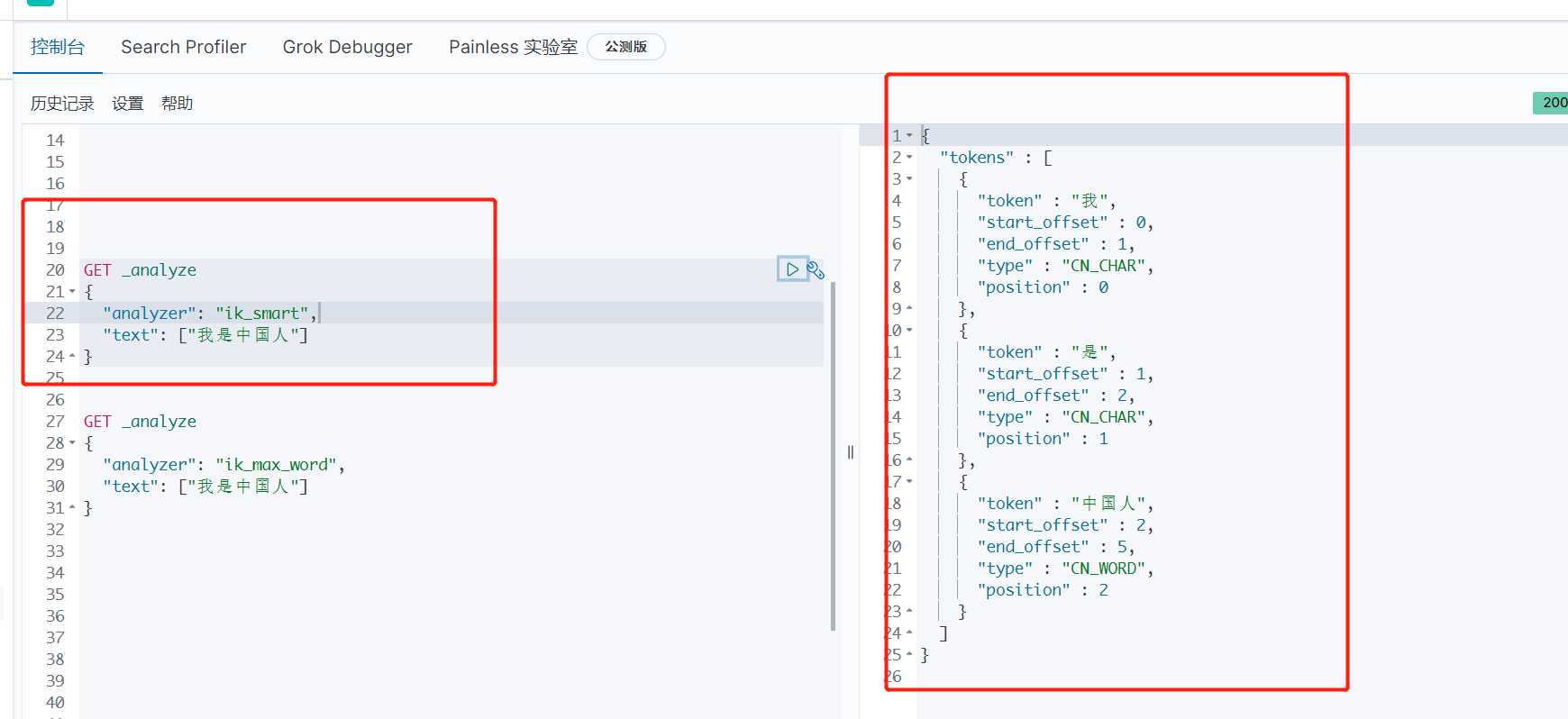
GET _analyze
{
"analyzer": "ik_smart",
"text": ["我是中国人"]
}
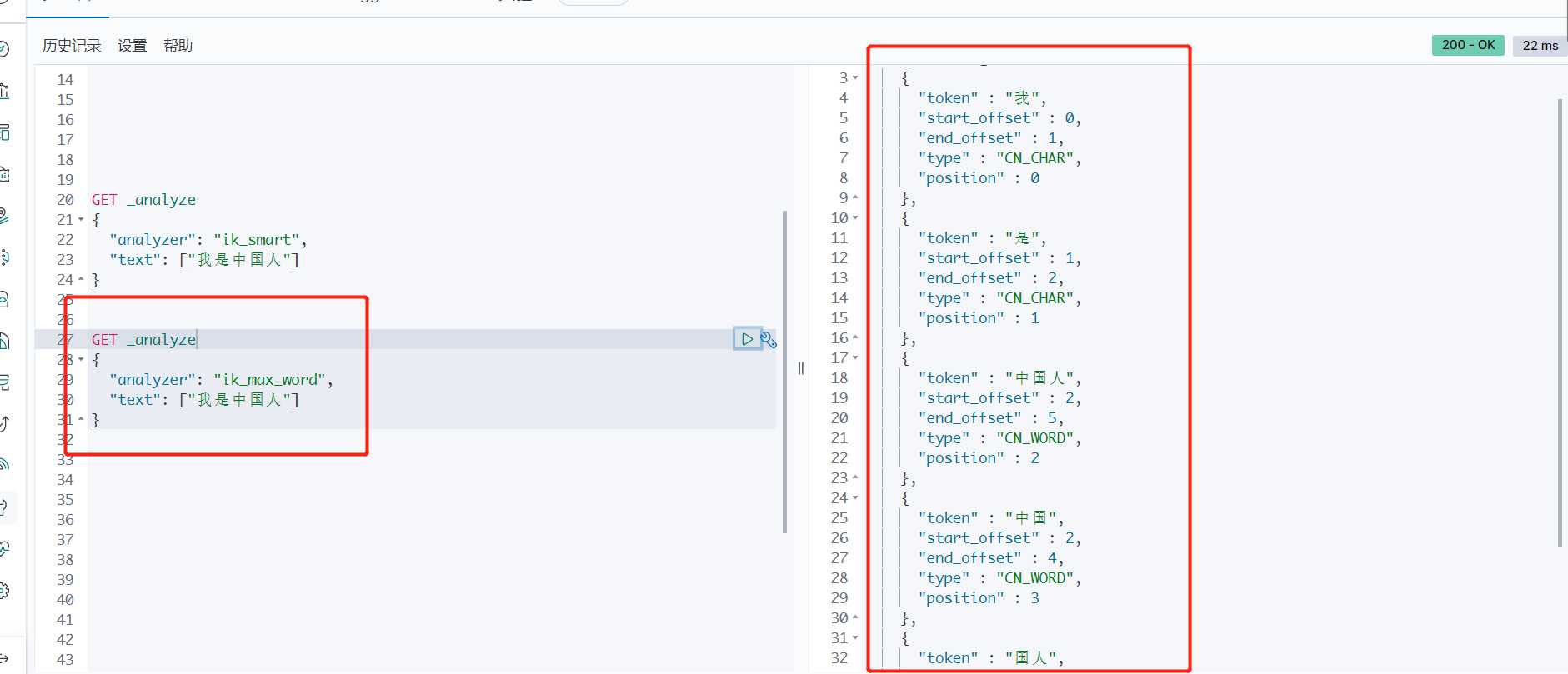
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["我是中国人"]
}
问题: