Kafka核心API——Stream API
2021-03-04 03:26
标签:partition 令行 info 因此 拓扑 场景 http 时间片 词频统计 Kafka Stream是Apache Kafka从0.10版本引入的一个新Feature,它提供了对存储于Kafka内的数据进行流式处理和分析的功能。简而言之,Kafka Stream就是一个用来做流计算的类库,与Storm、Spark Streaming、Flink的作用类似,但要轻量得多。 Kafka Stream的基本概念: Kafka Stream的高层架构图: Kafka Stream关键词: 如下图所示: 下图是Kafka Stream完整的高层架构图: 从上图中可以看到, 因此,我们在使用Stream API前需要先创建两个Topic,一个作为输入,一个作为输出。到服务器上使用命令行创建两个Topic: 由于之前依赖的 接下来以一个经典的词频统计为例,演示一下Stream API的使用。代码示例: 运行以上代码,然后到服务器中使用 然后再运行 控制台输出的结果: 从输出结果中可以看到,Kafka Stream首先是对前三行语句进行了一次词频统计,所以前半段是: 当最后一行输入之后,又再做了一次词频统计,并针对新的统计结果进行输出,其他没有变化的则不作输出,所以最后打印了: 这也是 在之前的例子中,我们是从某个Topic读取数据进行流处理后再输出到另一个Topic里。但在一些场景下,我们可能不希望将结果数据输出到Topic,而是写入到一些存储服务中,例如ElasticSearch、MongoDB、MySQL等。 在这种场景下,就可以利用到 Kafka核心API——Stream API 标签:partition 令行 info 因此 拓扑 场景 http 时间片 词频统计 原文地址:https://blog.51cto.com/zero01/2498111
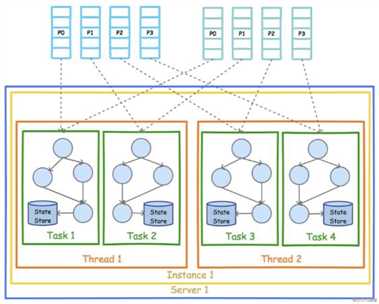
Kafka Stream 核心概念
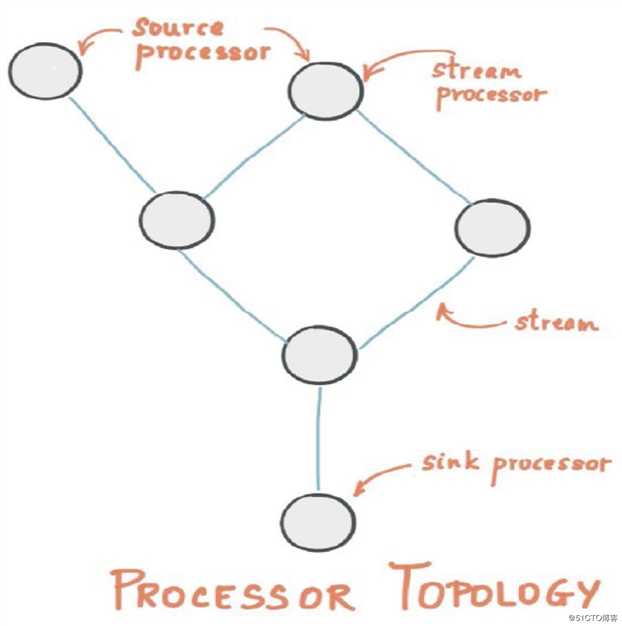
Kafka Stream使用演示
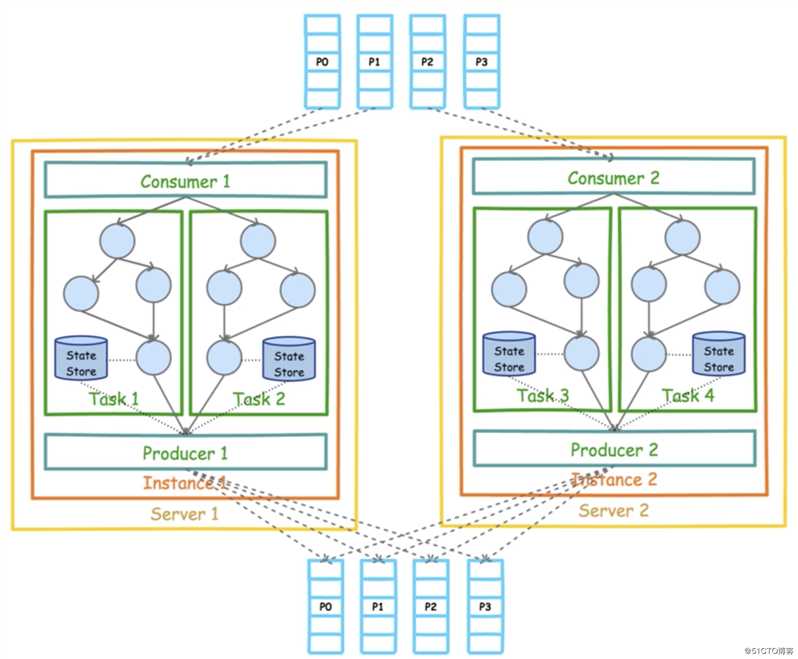
Consumer对一组Partition进行消费,这组Partition可以在一个Topic中或多个Topic中。然后形成数据流,经过各个流处理器后最终通过Producer输出到一组Partition中,同样这组Partition也可以在一个Topic中或多个Topic中。这个过程就是数据流的输入和输出。[root@txy-server2 ~]# kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic input-topic
[root@txy-server2 ~]# kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic output-topickafka-clients包中没有Stream API,所以需要另外引入Stream的依赖包。在项目中添加如下依赖:package com.zj.study.kafka.stream;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Produced;
import java.util.List;
import java.util.Properties;
public class StreamSample {
private static final String INPUT_TOPIC = "input-topic";
private static final String OUTPUT_TOPIC = "output-topic";
/**
* 构建配置属性
*/
public static Properties getProperties() {
Properties properties = new Properties();
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "49.232.153.84:9092");
properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-app");
properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
return properties;
}
public static KafkaStreams createKafkaStreams() {
Properties properties = getProperties();
// 构建流结构拓扑
StreamsBuilder builder = new StreamsBuilder();
// 构建wordCount这个Processor
wordCountStream(builder);
Topology topology = builder.build();
// 构建KafkaStreams
return new KafkaStreams(topology, properties);
}
/**
* 定义流计算过程
* 例子为词频统计
*/
public static void wordCountStream(StreamsBuilder builder) {
// 不断的从INPUT_TOPIC上获取新的数据,并追加到流上的一个抽象对象
KStreamKTable与KStream的关系与区别,如下图: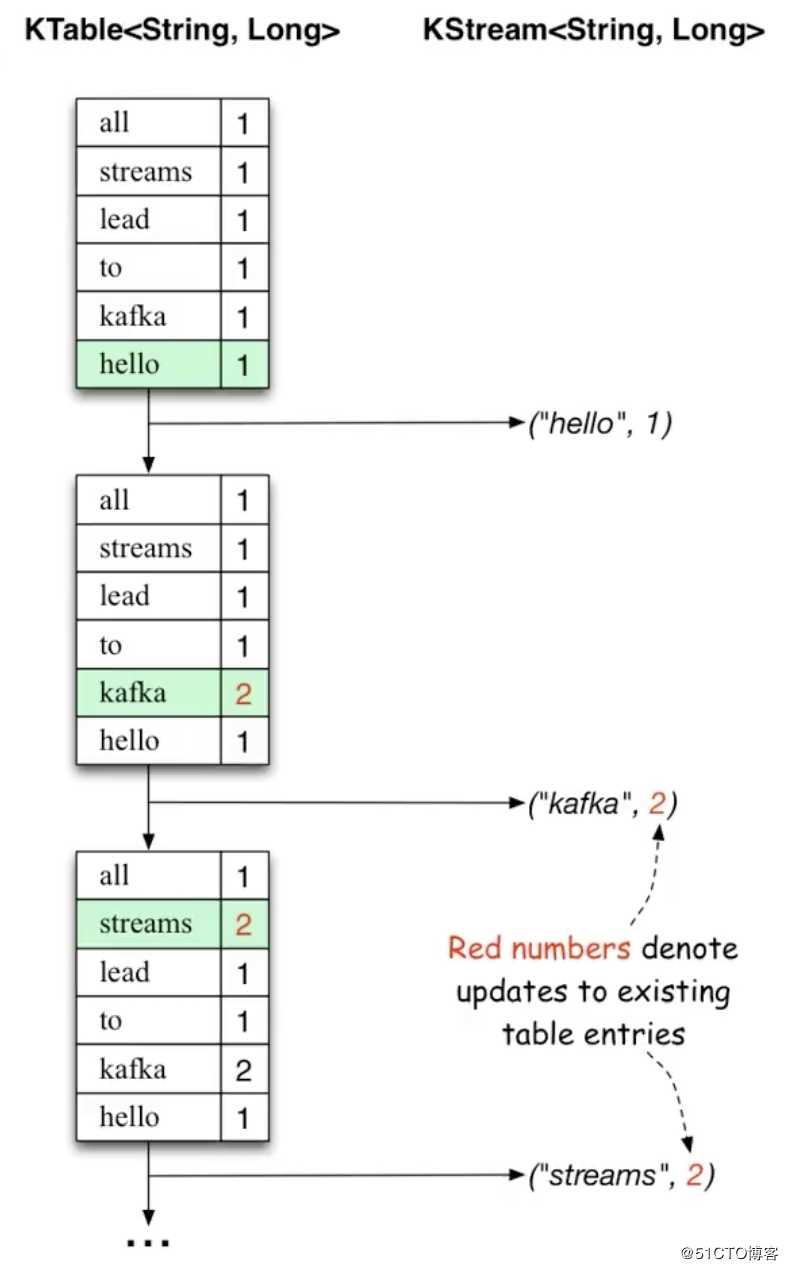
KTable类似于一个时间片段,在一个时间片段内输入的数据就会update进去,以这样的形式来维护这张表KStream则没有update这个概念,而是不断的追加kafka-console-producer.sh脚本命令向input-topic生产一些数据,如下:[root@txy-server2 ~]# kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic input-topic
>Hello World Java
>Hello World Kafka
>Hello Java Kafka
>Hello Javakafka-console-consumer.sh脚本命令从output-topic中消费数据,并进行打印。具体如下:[root@txy-server2 ~]# kafka-console-consumer.sh --bootstrap-server 172.21.0.10:9092 --topic output-topic --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer --from-beginningworld 2
hello 3
java 2
kafka 2
hello 4
java 3world 2
hello 3
java 2
kafka 2hello 4
java 3KTable和KStream的一个体现,从测试的结果可以看出Kafka Stream是实时进行流计算的,并且每次只会针对有变化的内容进行输出。
foreach方法
foreach方法,该方法用于迭代流中的元素。我们可以在foreach中将数据存入例如Map、List等容器,然后再批量写入到数据库或其他存储中间件即可。foreach方法使用示例:public static void foreachStream(StreamsBuilder builder) {
KStream
下一篇:Wpf项目基础知识
文章标题:Kafka核心API——Stream API
文章链接:http://soscw.com/index.php/essay/59806.html