Python文件I/O
2021-03-07 11:29
标签:format 多个 ioerror lin 方式 sequence dede open() coding 文件读写包括:文件打开(open),模式(文件读(r,r+),文件写(w,w+),文件追加(a)),文件关闭(close()),字符集(encoding=UTF-8),流程管理函数with(),文件的相对路径和绝对路径 open():open打开的文件是一个流,只能被read()函数消费一次,如果需要多次消费,需要重复打开 test.txt文件内容: 代码: 运行结果:第一次阅读(readline())打印了文件第一行内容,第二次阅读(read())打印了剩余的所有内容,第三次阅读(readline())没有打印任何内容,说明文件打开后是一个流,只能被消费一次 open文件,类型;以及多行读取,读取内容的保持形势 代码: 运行结果:open打开的文件是一个io流,用readlines()打开文件为一个list保存 遍历文件方式,一次性全部读取转为list: 代码: 运行结果: 遍历文件方式:逐行读取 代码: 运行结果: 关于文件open()的mode参数: ‘r‘:读 ‘w‘:写 ‘a‘:追加 ‘r+‘ == r+w(可读可写,文件若不存在就报错(IOError)) ‘w+‘ == w+r(可读可写,文件若不存在就创建) ‘a+‘ ==a+r(可追加可写,文件若不存在就创建) 对应的,如果是二进制文件,就都加一个b就好啦: ‘rb‘ ‘wb‘ ‘ab‘ ‘rb+‘ ‘wb+‘ ‘ab+‘ open(),close()和with() open和close函数本身是需要成对出现的,如果打开后不关闭,会导致系统内存被占用的情况,消耗服务器资源; python 简化了该写法,即用 with open(...) as ... ,不需要在手动关闭文件,建议以后用该写法 字符集: 文件读取与文件本身的编码格式息息相关,如果是UTF-8的文件,用GBK编码格式去读取,如果内容有非法编码字符,读取就会报错如:UnicodeDecodeError:‘gbk‘ codec can‘t decode byte 0xb4 in position 111: illegal multibyte sequence 具体关于字符集可以阅读如下文章:https://www.cnblogs.com/gavin-num1/p/5170247.html Python文件I/O 标签:format 多个 ioerror lin 方式 sequence dede open() coding 原文地址:https://www.cnblogs.com/wangwang365/p/14262505.html
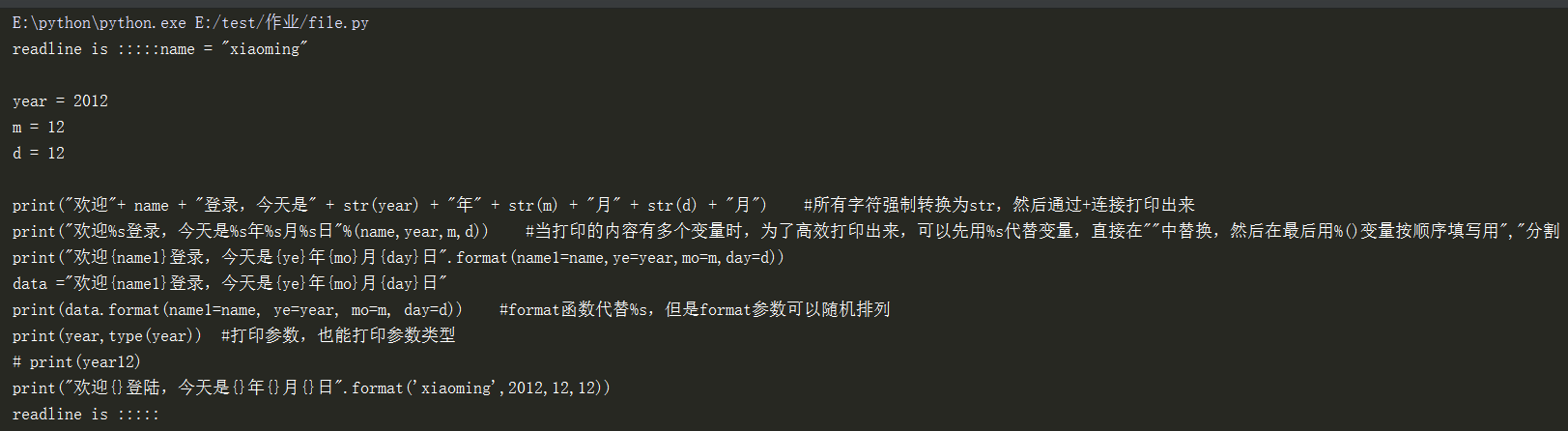
name = "xiaoming"
year = 2012
m = 12
d = 12
print("欢迎"+ name + "登录,今天是" + str(year) + "年" + str(m) + "月" + str(d) + "月") #所有字符强制转换为str,然后通过+连接打印出来
print("欢迎%s登录,今天是%s年%s月%s日"%(name,year,m,d)) #当打印的内容有多个变量时,为了高效打印出来,可以先用%s代替变量,直接在""中替换,然后在最后用%()变量按顺序填写用","分割
print("欢迎{name1}登录,今天是{ye}年{mo}月{day}日".format(name1=name,ye=year,mo=m,day=d))
data ="欢迎{name1}登录,今天是{ye}年{mo}月{day}日"
print(data.format(name1=name, ye=year, mo=m, day=d)) #format函数代替%s,但是format参数可以随机排列
print(year,type(year)) #打印参数,也能打印参数类型
# print(year12)
print("欢迎{}登陆,今天是{}年{}月{}日".format(‘xiaoming‘,2012,12,12))
1 file = open("test.txt","r",encoding = ‘UTF-8‘) #以r模式打开文件test.txt,文件编码格式为UTF-8,流命名为file
2 print("readline is :::::{re}".format(re=file.readline())) #阅读第一行内容,并打印出来
3 print(file.read()) #阅读所有内容并打印出来
4 print("readline is :::::{re}".format(re=file.readline())) #阅读剩余内容并打印出来
5 file.close() #关闭阅读文件流
1 file1 = open("test.txt","r",encoding="UTF-8") #以r模式打开文件test.txt,文件编码格式为UTF-8,流命名为file1
2 print(file1,type(file1)) #打印file1,类型
3 print(file1.readlines()) #打印多行读取(readlines())file1结果
4 print(type(file1.readlines())) #打印多行读取(readlines())file1的类型
5 file1.close() #关闭file1

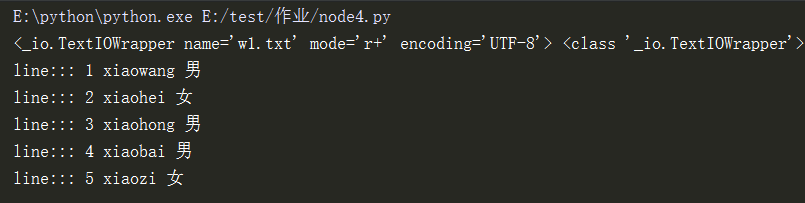
1 with open("w1.txt","r+",encoding="UTF-8") as f: #打开文件
2 print(f.readlines(),type(f.readlines())) #全部读取,保持在一个list中
3 with open("w1.txt","r+",encoding="UTF-8") as f1:
4 for line in f1.readlines(): #循环遍历list
5 print("line:::",line.strip().split(" "))
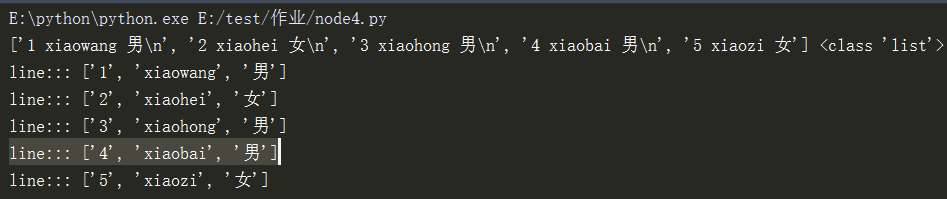
1 with open("w1.txt","r+",encoding="UTF-8") as f2: #打开文件
2 print(f2,type(f2)) #打印f2,及其数据类型
3 for line in f2: #逐行遍历
4 print("line:::",line.strip())