Java并发容器J.U.C
2021-03-07 20:27
标签:example 现在 final 要求 public collect 复杂度 多个 adp 从上面的源码中得到 以上代码显示 如果出现并发 由于在 不能用于实时读的场景,像拷贝数组,新增元素都需要时间,所以调用 在多线程环境下, 在多线程环境下,使用 跳表(SkipList):使用空间换时间的算法,令链表的每个结点不仅记录next结点位置,还可以按照level层级分别记录后继第level个结点。 关注微信公众号:【入门小站】解锁更多知识点 Java并发容器J.U.C 标签:example 现在 final 要求 public collect 复杂度 多个 adp 原文地址:https://www.cnblogs.com/rumenz/p/14259265.html
J.U.C是java.util.concurrent的简写,里面提供了很多线程安全的集合。
CopyOnWriteArrayList介绍
CopyOnWriteArrayList相比于ArrayList是线程安全的,字面意思是写操作时复制。CopyOnWriteArrayList使用写操作时复制技术,当有新元素需要加入时,先从原数组拷贝一份出来。然后在新数组里面加锁添加,添加之后,将原来数组的引用指向新数组。 public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); //加锁
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
//引用指向更改
setArray(newElements);
return true;
} finally {
lock.unlock(); //释放锁
}
}
CopyOnWriteArrayList的add操作是在加锁的保护下完成的。加锁是为了多线程对CopyOnWriteArrayList并发add时,复制多个副本,把数据搞乱。public E get(int index) {
return get(getArray(), index);
}
get是没有加锁的
get,会有以下3中情况。
CopyOnWriteArrayList多线程代码演示。package com.rumenz.task;
import java.util.List;
import java.util.concurrent.*;
//线程安全
public class CopyOnWrireArrayListExample {
public static Integer clientTotal=5000;
public static Integer threadTotal=200;
private static List
CopyOnWriteArrayList使用场景
add的时候需要拷贝原数组,如果原数组内容比较多,比较大,可能会导致young gc和full gc。get操作后,有可能得到的数据是旧数据,虽然CopyOnWriteArrayList能做到最终一致性,但是没有办法满足实时性要求。CopyOnWriteArrayList适合读多写少的场景,比如白名单,黑名单等场景CopyOnWriteArrayList由于add时需要复制数组,所以不适用高性能的互联网的应用。
CopyOnWriteArraySet介绍public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList
CopyOnWriteArraySet底层是用CopyOnWriteArraySet来实现的。可变操作(add,set,remove等)都需要拷贝原数组进行操作,一般开销很大。迭代器支持hasNext(),netx()等不可变操作,不支持可变的remove操作,使用迭代器速度很快,并且不会与其它线程冲突,在构造迭代器时,依赖不变的数组快照。
CopyOnWriteArraySet多线代码演示package com.rumenz.task;
import java.util.List;
import java.util.Set;
import java.util.concurrent.*;
//线程安全
public class CopyOnWrireArraySetExample {
public static Integer clientTotal=5000;
public static Integer threadTotal=200;
private static Set
CopyOnWriteArraySet使用场景
ConcurrentSkipListSetpublic ConcurrentSkipListSet() {
m = new ConcurrentSkipListMap
ConcurrentSkipListSet是jdk6新增的类,支持自然排序,位于java.util.concurrent。ConcurrentSkipListSet都是基于Map集合的,底层由ConcurrentSkipListMap实现。
ConcurrentSkipListSet的add,remove,contains是线程安全的。但是对于批量操作addAll,removeAll,containsAll并不能保证原子操作,所以是线程不安全的,原因是addAll,removeAll,containsAll底层调用的还是add,remove,contains方法,在批量操作时,只能保证每一次的add,remove,contains是原子性的(即在进行add,remove,contains,不会被其它线程打断),而不能保证每一次批量操作都不会被其它线程打断,因此在addAll、removeAll、retainAll 和 containsAll操作时,需要添加额外的同步操作。public boolean addAll(Collection extends E> c) {
boolean modified = false;
for (E e : c)
if (add(e))
modified = true;
return modified;
}
public boolean removeAll(Collection> c) {
Objects.requireNonNull(c);
boolean modified = false;
Iterator> it = iterator();
while (it.hasNext()) {
if (c.contains(it.next())) {
it.remove();
modified = true;
}
}
return modified;
}
public boolean containsAll(Collection> c) {
for (Object e : c)
if (!contains(e))
return false;
return true;
}
ConcurrentSkipListSet代码演示package com.rumenz.task;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
import java.util.concurrent.*;
//线程安全
public class CopyOnWrireArrayListExample {
public static Integer clientTotal=5000;
public static Integer threadTotal=200;
private static SetConcurrentHashMap
ConcurrentHashMap中key和value都不允许为null,ConcurrentHashMap针对读操作做了大量的优化。在高并发场景很有优势。
HashMap进行put操作会引起死循环,导致CPU利用率到100%,所以在多线程环境不能随意使用HashMap。原因分析:HashMap在进行put的时候,插入的元素超过了容量就会发生rehash扩容,这个操作会把原来的元素hash到新的扩容新的数组,在多线程情况下,如果此时有其它线程在进行put操作,如果Hash值相同,可能出现在同一数组下用链表表示,造成闭环,导致get的时候出现死循环,所以是线程不安全的。
HashTable它是线程安全的,它涉及到多线程的操作都synchronized关键字来锁住整个table,这就意味着所有的线程都在竞争同一把锁,在多线程环境下是安全的,但是效率很低。
HashTable有很多的优化空间,锁住整个table这么粗暴的方法可以变相的柔和点,比如在多线程的环境下,对不同的数据集进行操作时其实根本就不需要去竞争一个锁,因为他们不同hash值,不会因为rehash造成线程不安全,所以互不影响,这就是锁分离技术,将锁的粒度降低,利用多个锁来控制多个小的table,多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMapJDK1.7版本的核心思想。
ConcurrentHashMap代码演示案例package com.rumenz.task;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.*;
//线程安全
public class ConcurrentHashMapExample {
public static Integer clientTotal=5000;
public static Integer threadTotal=200;
private static MapConcurrentSkipListMap
ConcurrentSkipListMap内部使用SkipList结构实现。跳表是一个链表,但是通过跳跃式的查找方式使得插入,读取数据时的时间复杂度变成O(log n)。
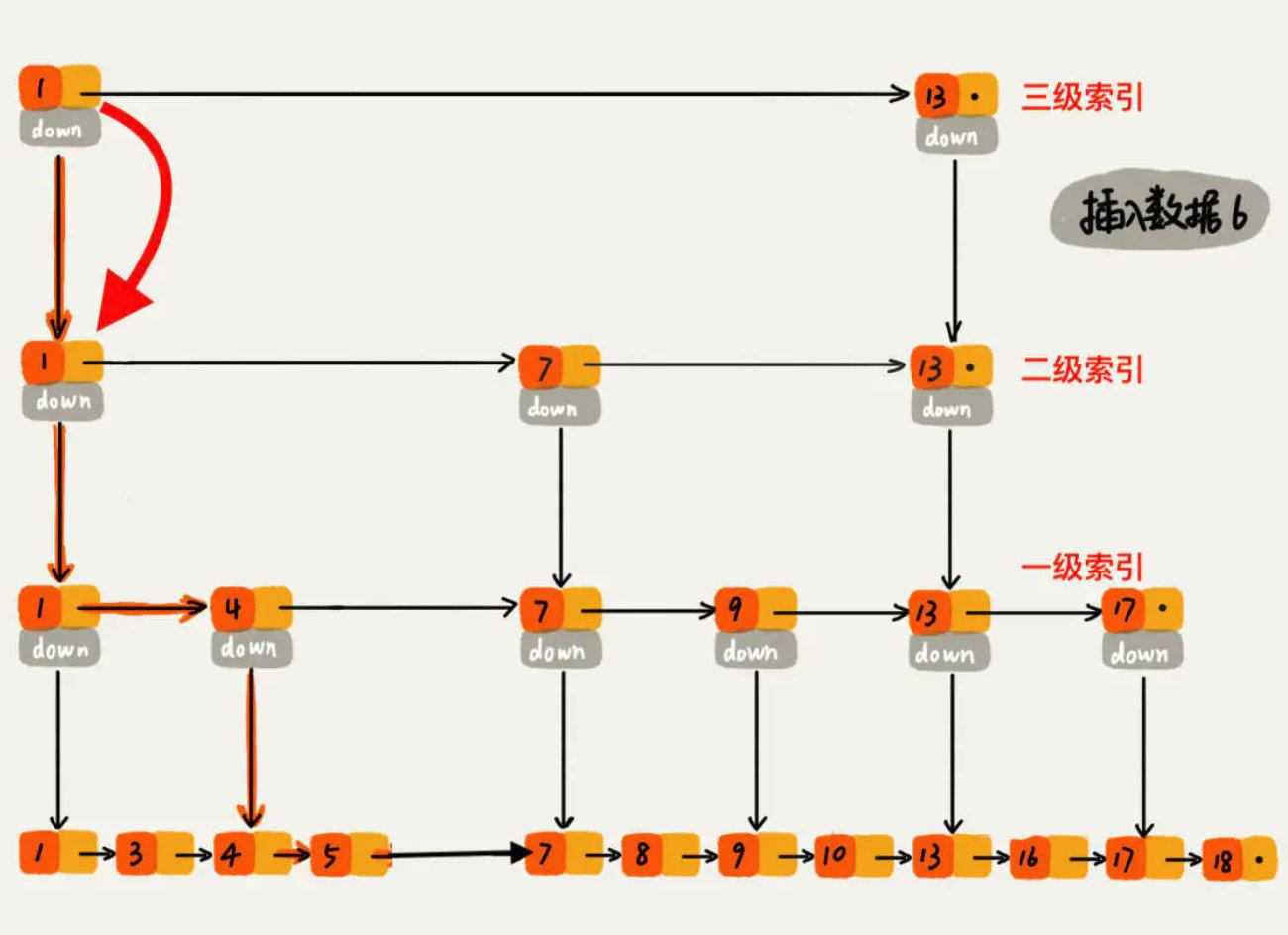
ConcurrentSkipListMap代码案例package com.rumenz.task;
import java.util.Map;
import java.util.concurrent.*;
//线程安全
public class ConcurrentSkipListMapExample {
public static Integer clientTotal=5000;
public static Integer threadTotal=200;
private static Map
ConcurrentHashMap与ConcurrentSkipListMap的对比
ConcurrentHashMap比ConcurrentSkipListMap性能要好一些。ConcurrentSkipListMap的key是有序的,ConcurrentHashMap做不到。ConcurrentSkipListMap支持高并发,它的时间复杂度是log(N),和线程数无关,也就是说任务一定的情况下,并发的线程越多,ConcurrentSkipListMap的优势就越能体现出来。