UDP/爬虫/HTML
2021-03-08 00:27
标签:制作 bye 改ip cep 操作 height port ip地址 学习 将两段代码制作成PY文件放在桌面 然后就按图中操作即可 ——————————————————————————分界线———————————————————————— 用requests库的get函数访问360浏览器20遍,打印返回状态,text()内容,计算text()属性和content()属性所返回网页内容的长度 代码 爬大学排名网页内容 ——————————————————————————分界线———————————————————————— HTML之初学习 UDP/爬虫/HTML 标签:制作 bye 改ip cep 操作 height port ip地址 学习 原文地址:https://www.cnblogs.com/lalalala-fan/p/12881305.html
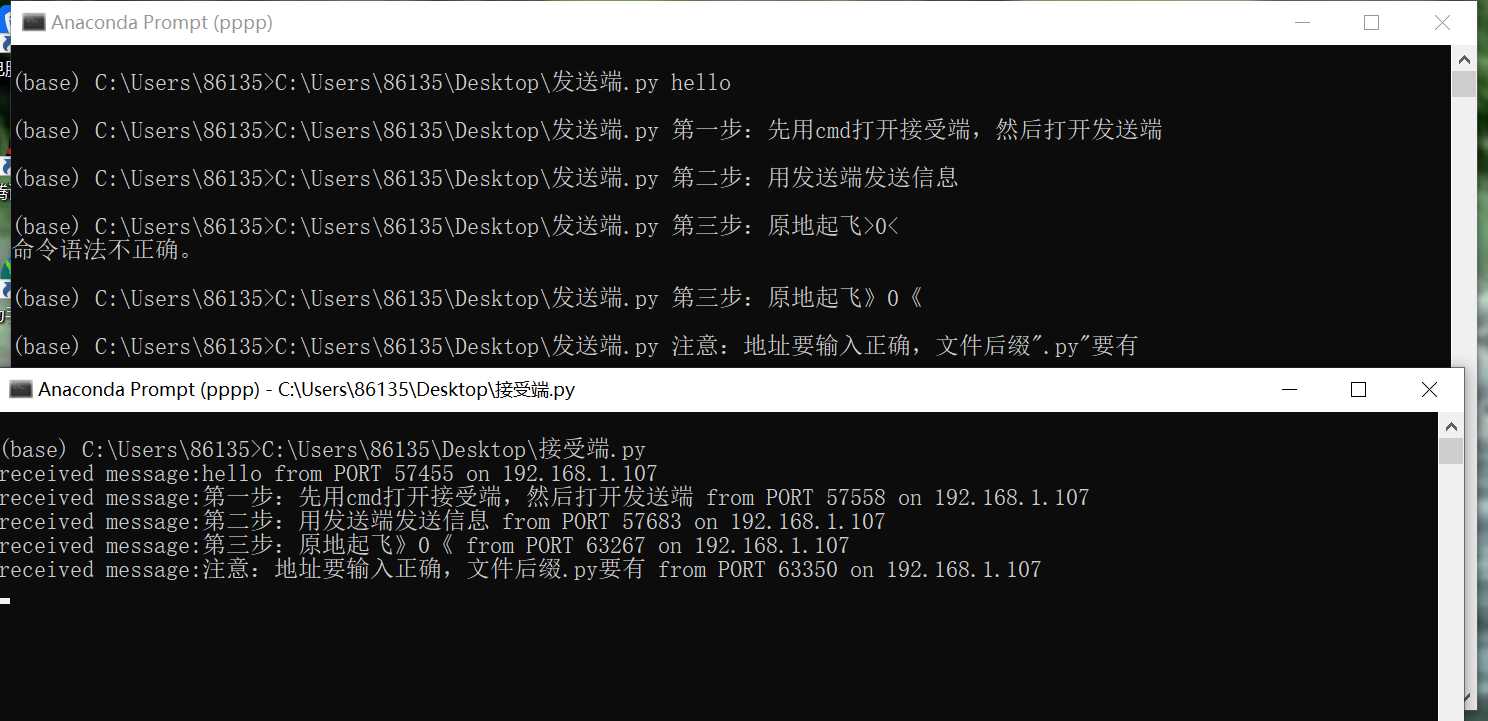
#接受端代码(更改IP地址即可,其余无须修改)
import socket
#使用IPV4协议,使用UDP协议传输数据
s=socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
#绑定端口和端口号,空字符串表示本机任何可用IP地址
s.bind((‘100.100.100.100‘, 5000)) #更改IP地址即可
while True:
data, addr=s.recvfrom(1024)
#显示接收到的内容
print(‘received message:{0} from PORT {1} on {2}‘.format(data.decode(),addr[1], addr[0]))
if data.decode().lower() == ‘bye‘:
break
s.close( )#接受端代码(更改IP地址即可)
import socket
import sys
s=socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.sendto(sys.argv[1].encode() , ("100.100.100.100" ,5000))
#假设100.100.100.100是接收端机器的IP地址
s.close( )

import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
soup=BeautifulSoup(r.text)
r.raise_for_status()
r.encoding=‘utf-8‘
return r.text,r.status_code,len(r.text),r.encoding,len(soup.text)
except:
return ""
url="https://www.baidu.com" #这是一个网页链接,自行更改即可
for i in range(20):
print(i)
print(getHTMLText(url))

import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
allUniv=[]
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=‘utf-8‘
return r.text
except:
return ""
def fillUnivList(soup):
data=soup.find_all(‘tr‘)
for tr in data:
ltd=tr.find_all(‘td‘)
if len(ltd)==0:
continue
singleUniv=[]
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
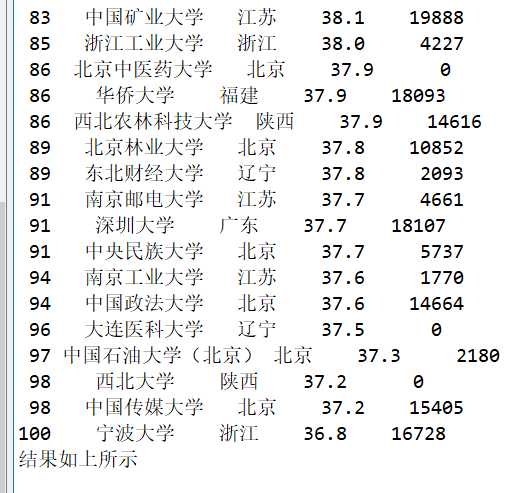
def printUnivList(num):
print("{:^4}{:^10}{:^5}{:^8}{:^10}".format("排名","学校名称","省市","总分","年费"))
for i in range(num):
u=allUniv[i]
print("{:^4}{:^10}{:^5}{:^8}{:^10}".format(u[0],u[1],u[2],u[3],u[6]))
return u
def main(num):
url = ‘http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html‘
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
fillUnivList(soup)
printUnivList(num)
print("结果如上所示")
main(100)
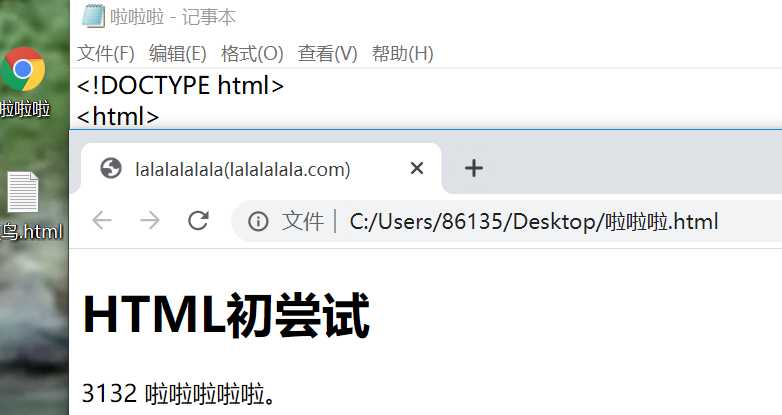
DOCTYPE html>
html>
head>
meta charset="utf-8">
title>lalalalalala(lalalalala.com)title>
head>
body>
h1>HTML初尝试h1>
p>3132 啦啦啦啦啦。p>
body>
html>
下一篇:JS实现文件上传下载功能实例解析