在R语言中写一个C函数
2021-03-08 05:28
标签:命令编译 list 参考资料 call 区间 tab -- pdf 转换 那么如何用C语言写一个R包呢?本文的重点不放在R包的编写和发布上,而是如何在R中调用C编写的函数。当然,如果你知道了如何调用C函数,那么发布一个C编写的R包也就没有什么难度了。 .C()是最基础的调用方法,使用.C()要注意以下几个问题: 将上述保存为myC.c的源文件,下面我们要做的是将该源文件编译成.so的共享对象文件。在终端上使用下列命令编译,注意大小写: 编译完成,如果提示没有错误,应该有一个myC.so的文件产生。 输出结果如下, 结果中不光有我们需要的部分,还有一些返回的列表。这个时候我们就需要把这个C函数进行包装了,也就是写一个wrapper. 通过这个wrapper可以像R函数那样使用: 为该C函数写一些R的wrapper 下面我们就比较一个R代码和C代码的速度。 结果用R函数运行时间为0.007秒,用C函数运行时间为0.031秒! .C()调用的函数是很简单初级的C函数,只有简单的数据类型可以从R语言传递给C函数,而且内存的申请必须在R语言中进行。相比之下, .Call()就显得高级多了。通过.Call()调用的C函数中,可以有复杂的数据类型,可以有返回值,可以在该函数中申请新的内存,不需要对实参进行复制,甚至某些语句可以使用简单的R语言来写。 注意,在上述代码中多了SEXP这类变量类型,其意思为S-expression的简写,该种变量类型在头文件Rinternals.h中有定义,它是R语言和C语言之间变量传递的纽带。 2.正数加一 使用allocVector申请内存空间,其有两个参数,一个是变量类型,一个是变量数量,如上例子中,使用INTSXP表示申请内存空间为整型,1表示申请内存空间的大小为1个整型空间大小。 如上,如果传入的是含有多个元素的向量,建议转换成C语言指针,这样能够大大加快运行速度,特别是含有较多的元素的时候。 下面是我们在R中创建不同大小的模拟数据集,然后调用上述C函数。同时,为了比较运行速度,此处加入了R语言函数,以及一个C++写的函数【参考:install_github("Yiguan/CheckOverlap")】。这3种方法都采用了完全相同的实现方式,即两个for语句的嵌套循环。下面比较一下它们的运行速度。 下图为三种语言在不同样本量大小的情况下的运行时间(秒): 本文主要介绍了R语言中的C的API,即如何写一个可以在R语言中调用的C函数。 在R语言中写一个C函数 标签:命令编译 list 参考资料 call 区间 tab -- pdf 转换 原文地址:https://blog.51cto.com/15069450/2577095使用C++制作一个R包
为什么要用C语言写?应为C快!尤其是对于循环,C的速度优势体现的极为明显。很多R包或者函数都是用C语言写的,比如我现在几乎每次打开R都用导入的data.table包,本以为是用C++写的,没想到也是用C语言写的。
同时,理解R语言中的C API有助于我们理解R中函数的运行方式和使用方法。
在R语言中调用C函数,最简单的是.C(),除此之外,还可以使用.Call()和.External()调用C函数。.C()调用C函数
1)R语言中的变量必须以指针的方式传递给C函数;
2)C函数的返回类型类型必须是void
3)C中没有返回语句,C运行的结果通过修饰参数返回给R
4)R以列表list的形式承接C函数返回内容
下面是R中数据形式对应到C函数的参数的形式:
注意,如果要使用复数形式,那么在C语言中应该加上#include
以具体例子来看如何在R中调用C函数。
首先写一个两个整数相加的C函数#include R CMD SHLIB myC.c
然后我们就可以在R中调用该函数了,具体如下:dyn.load("myC.so")
.C("addme", as.integer(1),as.integer(3))4
[[1]]
[1] 1
[[2]]
[1] 3myadd myadd(1,3)
## 4
下面我们来比较一下使用C函数和R中的函数把一个字符串逆序输出的执行速度差异。
C函数源代码:#include myRev # 创建一个A-Z的长字符串
aa
嗯哼??翻车了?图片图片R语言比C还快?这个问题我们后面再说。
上面的两个例子展示了如何写简单的C函数,如何使用.C()调用该函数,包括如何写一个函数包装。.Call()调用C函数
且看下面的几个例子:
#include
R语言中的变量必须以SEXP变量类型传递给C函数,C函数的返回值类型必须以SEXP类型返回给R语言。实际上,SEXP是一个结构体的指针。其中包含了具体的变量类型,与R中数据类型的对应关系如下:REALSXP : 实数向量
INTSXP : 整数向量
LGLSXP : 逻辑向量
STRSXP : 字符向量
VECSXP : 列表
CLOSXP : 函数
ENVSXP : 环境变量#include
PROTECT()用于保护在C函数中创建的变量,如果没有该语句,R语言的内存管理会将所有内存回收,我们要返回的变量会被删除。
UNPROTECT()函数用于去除相应内存的保护,以便系统将内存回收。其只有一个参数,即需要去保护的变量的数量。上例子中,我们只申请了一个被保护变量,所以这儿只填入1作为参数就可以了。
因为C函数传入和返回的参数都是以SEXP结构体的形式进行的,所以在C函数中对这些数据进行操作时,关键是要把数据形式转换成C语言自身的数据类型。如上例中,从R中传入的参数为innum,我们使用INTERGER(innum)来说明该参数为整型【实际上,就一个整型指针】,然后我们通过*对该地址取值,然后加一,然后将该整型结果赋于返回变量out,由于out是一个整型列表,所以使用[0]表示将加一之后的结果放在第一个列表元素中。注意,C语言中的计数是从0开始的,R语言是从1开始的。
然后和.C()的方法一样,对该C函数文件进行编译,然后再R中直接使用,比如.Call("addone",3),就可以了。
当然, 你可以写一个wrapper,将该C函数包装成R语言函数调用。
其他类型数据,请参考:
http://tolstoy.newcastle.edu.au/R/e17/devel/att-0724/R_API_cheat_sheet.pdf
如下图,在一个数轴上有一些随机长处和位置的线段(橙色),以及一些随机产生的黑色的点,我们的任务是判断这些点是否位于橙色线段上,如果是返回1,如果不是返回0。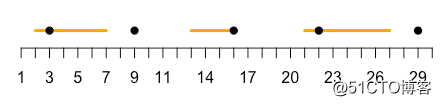
在生物学场景中,可以是判断SNP位点是否位于某个基因序列区间内。
首先,写一个C函数如下#include
将上述脚本保存为myhit.c,在终端中:R CMD SHLIB myhit.clibrary(data.table)
df = seg.start[j]) & (point[i] 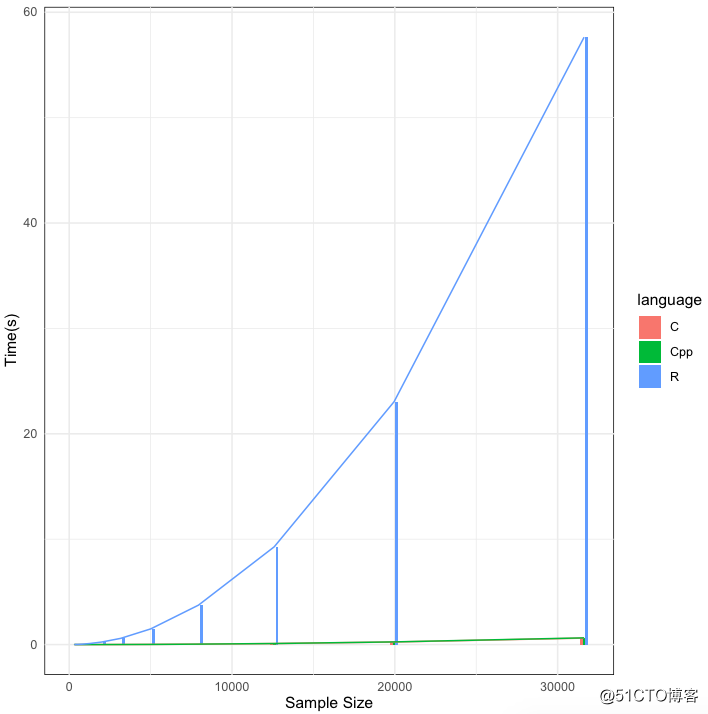
【3种语言耗时比较,横坐标为测试样本量,纵坐标为耗时(秒)】
比较一下,可以发现,C/C++几乎是一条水平直线,即随着运算量增大,它们的耗时依旧很少;相比之下,R语言的运行速度远远落后于C/C++,速度大小能够相差100倍!C和C++速度几乎相当,但是仔细看,C似乎比C++能够快一小点儿。
数值型数据R和C之间是比较容易处理的,但是字符型变量就比较麻烦一些。比如,下例中,提取一个字符串向量的第二个元素。首先,使用allocVector(STRSXP,1)申请一个长度为1的字符型空间,然后使用CHAR(STRING_ELT(ss,1))提取字符串ss的第二个元素,这儿返回的实际上是一个指针,指向了该元素的第一个字符。mkChar(p)将C语言的字符串转化成R语言的SEXP对象,并将该对象赋于out变量空间的第一个元素位置。#include 总结
.C()调用C函数的方式简单直接,但是实现的功能有限,难以写太复杂的函数。.Call()定义了R语言和C函数之间的变量SEXP,实用性和功能性丰富了很多,但是有一定的学习成本。不过如果是写比较的大,或者功能比较复杂的C函数,使用.Call()还是一个不错的选择。
另外,本文再次比较了R语言和C/C++的运行效率。对于普通R函数,比如是一些R基础包中的函数,这些函数已经是做过极大程度的性能优化了,其中很多也是用C语言写的,所以速度是有保证的。有时候它们比我们自己写的C函数还要快,所以对于这类R函数直接用应该没问题。但是对于循环,尤其是在循环次数非常多的时候,R语言的软肋就表现的很明显了,其运行速度远远慢于C/C++。
对于R语言的使用者来说,能不用循环就不用循环。如果觉得用C/C++写函数有难度,那么可以使用”向量化“的处理来代替循环,或者使用apply家族的一类函数,或者使用data.table这样的R包,也能够大大提高运行速度。
《谢谢阅读,欢迎转发分享》
参考资料:
http://adv-r.had.co.nz/C-interface.html
http://mazamascience.com/WorkingWithData/?p=1099
http://mazamascience.com/WorkingWithData/?p=1067