标签:element sha 通过 zab src external with list get
对于所谓序列化操作实际就是将要传输的数据转换为字节流或ByteBuffer
https://en.wikipedia.org/wiki/Serialization
维基百科对于序列化的定义
可以参考java 中 ObjectOutputStream/ObjectInputStream 对于 java对象的io操作
通过下图的debug信息分析调用顺序
- 调用ObjectOutputStream#writeObject方法
- 在该方法中会判断当前要被序列化的类是否实现了 java.io.Serializable接口
- 再进一步判断是否实现了 Externalizable 接口,对于 当前接口由于其提供了 writeObject 和 readObject方法支持相关方法定义,如果是当前接口的实现类,可以直接将其转换为 Externalizable类型 调用writeObject方法
- 反之如果未实现Externalizable接口或其不是一个concrete class(实现类)利用反射获取指定待序列化类的相关方法信息,主要是判断其是否包含writeObject方法,如果含有当前方法,则会调用实现类中writeObject方法;否则则会调用默认的序列化方法java.io.ObjectOutputStream#defaultWriteFields
我们进一步分析 ArrayList#writeObject方法,可以看到 (PS : 以下代码引用自)
jdk8 java.util.ArrayList
// 序列化
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
// 当前操作是为了将ArrayList中其他支持序列化的元素进行序列化操作
s.defaultWriteObject();
/**
* transient Object[] elementData;
* 对于集合中实际存储元素的 数组属性,使用了 "transient" 修饰表示其不支持被序列化操作
* 因此其通过以下操作实现数组数据的序列化操作
* 1: 首先写入当前数组中元素的数量
* 2: 循环整个数组,将数组中的元素进行单一序列化操作
*/
// Write out size as capacity for behavioural compatibility with clone()
// 类似于分割符的概念
s.writeInt(size);
// 将数组中的元素进行序列化操作
// Write out all elements in the proper order.
for (int i=0; i) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
// 反序列化
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
/**
* 对于反序列化操作
* 当对象创建成功后
* 1:首先读取存储的元素数量,并完成赋值
* 2:根据元素数量按照list 容量分配规则,创建合适的容量(分配新的数组空间)
* 3:根据序列化文件中存储的元素数据,将读取到的元素数据顺序写入到数组中
*/
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
/**
* 以下操作是为了计算集合容量,以及开辟新的数组空间
*/
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
/**
* 将解析到的数据写入到数组中
*/
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i) {
a[i] = s.readObject();
}
}
}
代码debug信息
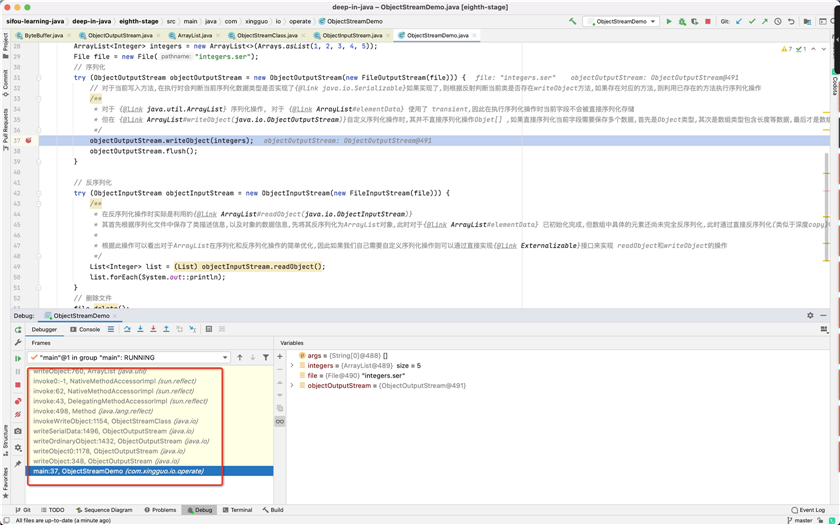
完整的代码
/*
* Copyright (c) 2020, guoxing, Co,. Ltd. All Rights Reserved
*/
package com.xingguo.io.operate;
import java.io.*;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* ObjectStreamDemo
* {@link java.io.ObjectOutputStream}
* {@link java.io.ObjectInputStream}
* 一般利用此操作支持对象序列化操作
*
* @author guoxing
* @date 2020/12/5 7:16 PM
* @since
*/
public class ObjectStreamDemo {
public static void main(String[] args) throws Exception {
/**
* 以 {@link java.util.ArrayList}为例
* {@link java.io.Externalizable}
* {@link java.io.Serializable}
*/
ArrayList integers = new ArrayList(Arrays.asList(1, 2, 3, 4, 5));
File file = new File("integers.ser");
// 序列化
try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(file))) {
// 对于当前写入方法,在执行时会判断当前序列化数据类型是否实现了{@link java.io.Serializable}如果实现了,则根据反射判断当前类是否存在writeObject方法,如果存在对应的方法,则利用已存在的方法执行序列化操作
/**
* 对于 {@link java.util.ArrayList} 序列化操作, 对于 {@link ArrayList#elementData} 使用了 transient,因此在执行序列化操作时当前字段不会被直接序列化存储
* 但在 {@link ArrayList#writeObject(java.io.ObjectOutputStream)}自定义序列化操作时,其并不直接序列化操作Objet[] ,如果直接序列化当前字段需要保存多个数据,首先是Object类型,其次是数组类型包含长度等数据,最后才是数组中的每个元素; 对于以上的操作实际会浪费一些序列化的性能,因此当前操作优化了当前操作,对于 {@link ArrayList#elementData}数据的序列化操作其首先储存数组的长度,然后循环解析数组中的每个元素并保存
*/
objectOutputStream.writeObject(integers);
objectOutputStream.flush();
}
// 反序列化
try (ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(file))) {
/**
* 在反序列化操作时实际是利用的{@link ArrayList#readObject(java.io.ObjectInputStream)}
* 其首先根据序列化文件中保存了类描述信息,以及对象的数据信息,先将其反序列化为ArrayList对象,此时对于{@link ArrayList#elementData} 已初始化完成,但数组中具体的元素还尚未完全反序列化,此时通过直接反序列化(类似于深度copy)每个元素,将其写入到数组中,实现完全的反序列化
*
* 根据此操作可以看出对于ArrayList在序列化和反序列化操作的简单优化,因此如果我们自己需要自定义序列化操作则可以通过直接实现{@link Externalizable}接口来实现 readObject和writeObject的操作
*/
List list = (List) objectInputStream.readObject();
list.forEach(System.out::println);
}
// 删除文件
file.delete();
}
}
java学习-io-序列化
标签:element sha 通过 zab src external with list get
原文地址:https://www.cnblogs.com/xingguoblog/p/14152004.html