Ribbon提供的负载均衡算法IRule(四)
2021-03-09 23:31
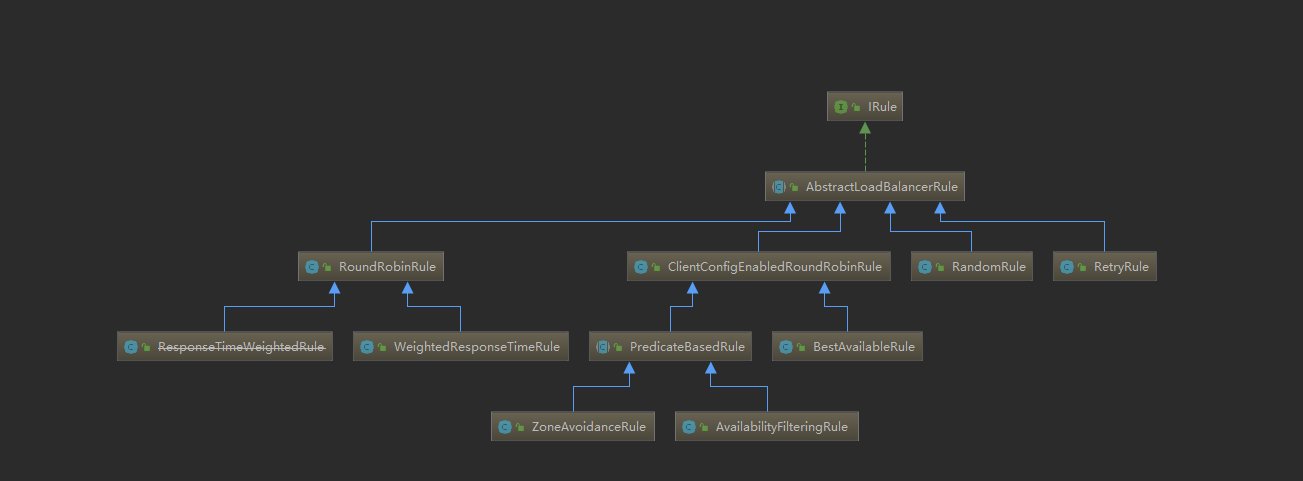
标签:失败 抽象类 factor dynamic exce alt add span interrupt Ribbon的源码地址:https://github.com/Netflix/ribbon IRule:根据特定算法中从服务器列表中选取一个要访问的服务,Ribbon默认的算法为ZoneAvoidanceRule; Ribbon中的7中负载均衡算法: (1)RoundRobinRule:轮询; (2)RandomRule:随机; (3)AvailabilityFilteringRule:会先过滤掉由于多次访问故障而处于断路器状态的服务,还有并发的连接数量超过阈值的服务,然后对剩余的服务列表按照轮询策略进行访问; (4)WeightedResponseTimeRule:根据平均响应时间计算所有服务的权重,响应时间越快的服务权重越大被选中的概率越大。刚启动时如果统计信息不足,则使用RoundRobinRule(轮询)策略,等统计信息足够,会切换到WeightedResponseTimeRule; (5)RetryRule:先按照RoundRobinRule(轮询)策略获取服务,如果获取服务失败则在指定时间内进行重试,获取可用的服务; (6)BestAvailableRule:会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务; (7)ZoneAvoidanceRule:复合判断Server所在区域的性能和Server的可用性选择服务器,在没有Zone的情况下是类似轮询的算法; ribbion的负载均衡算法结构: 1、打开消费者工程,增加如下的配置 2、启动类增加 @EnableEurekaClient 注解 3、然后重启这个消费者服务,访问;可以查看到随机访问生产者服务。 WeightedResponseTimeRule这个策略每30秒计算一次服务器响应时间,以响应时间作为权重,响应时间越短的服务器被选中的概率越大。它有一个LoadBalancerStats类,这里面有三个缓存,它的作用是记住发起请求服务提供者的一些参数,例如响应时间 有了缓存数据后权重是怎么处理的呢,下面看WeightedResponseTimeRule,它有一个定时任务,定时去计算权重 根据文档要求进行配置权重算法 Debugger一下,可以看到进入了自己定义的权重里面来了,而且服务节点数什么都是对的,所以如果Ribbon提供的算法你觉得不够好,你就可以自己定义一个,其实和我之前自定义一个GhyPing一样,自己定义一个类然后继承抽象类 AbstractLoadBalancerRule,实现它的抽象方法 Ribbon提供的负载均衡算法IRule(四) 标签:失败 抽象类 factor dynamic exce alt add span interrupt 原文地址:https://www.cnblogs.com/xing1/p/14159970.html一、Ribbon算法的介绍
二、配置指定的负载均衡算法
@Configuration
public class ConfigBean
{
@Bean
@LoadBalanced //Ribbon 是客户端负载均衡的工具;
public RestTemplate getRestTemplate()
{
return new RestTemplate();
}
//配置负载均衡的策略为随机,默认算法为轮询算法
@Bean
public IRule myRule()
{
//return new RoundRobinRule();
return new RandomRule();
}
}
@SpringBootApplication
@EnableEurekaClient //本服务启动后自动注册到eureka中(如果用了注册中心记得加)
public class DeptProvider8001_App
{
public static void main(String[] args)
{
SpringApplication.run(DeptProvider8001_App.class, args);
}
}
三、RetryRule(重试)
//具备重试机制的实例选择功能
public class RetryRule extends AbstractLoadBalancerRule {
//默认使用RoundRobinRule实例
IRule subRule = new RoundRobinRule();
//阈值为500ms
long maxRetryMillis = 500;
public RetryRule() {
}
public RetryRule(IRule subRule) {
this.subRule = (subRule != null) ? subRule : new RoundRobinRule();
}
public RetryRule(IRule subRule, long maxRetryMillis) {
this.subRule = (subRule != null) ? subRule : new RoundRobinRule();
this.maxRetryMillis = (maxRetryMillis > 0) ? maxRetryMillis : 500;
}
public void setRule(IRule subRule) {
this.subRule = (subRule != null) ? subRule : new RoundRobinRule();
}
public IRule getRule() {
return subRule;
}
public void setMaxRetryMillis(long maxRetryMillis) {
if (maxRetryMillis > 0) {
this.maxRetryMillis = maxRetryMillis;
} else {
this.maxRetryMillis = 500;
}
}
public long getMaxRetryMillis() {
return maxRetryMillis;
}
@Override
public void setLoadBalancer(ILoadBalancer lb) {
super.setLoadBalancer(lb);
subRule.setLoadBalancer(lb);
}
public Server choose(ILoadBalancer lb, Object key) {
long requestTime = System.currentTimeMillis();
long deadline = requestTime + maxRetryMillis;
Server answer = null;
answer = subRule.choose(key);
if (((answer == null) || (!answer.isAlive()))
&& (System.currentTimeMillis() deadline)) {
InterruptTask task = new InterruptTask(deadline
- System.currentTimeMillis());
//反复重试
while (!Thread.interrupted()) {
//选择实例
answer = subRule.choose(key);
//500ms内没选择到就返回null
if (((answer == null) || (!answer.isAlive()))
&& (System.currentTimeMillis() deadline)) {
/* pause and retry hoping it‘s transient */
Thread.yield();
}
else //若能选择到实例,就返回
{
break;
}
}
task.cancel();
}
if ((answer == null) || (!answer.isAlive())) {
return null;
} else {
return answer;
}
}
@Override
public Server choose(Object key) {
return choose(getLoadBalancer(), key);
}
@Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
}
}
四、WeightedResponseTimeRule(权重)
//该策略是对RoundRobinRule的扩展,增加了根据实例的运行情况来计算权重
//并根据权重来挑选实例,以达到更优的分配效果
public class WeightedResponseTimeRule extends RoundRobinRule {
public static final IClientConfigKey
//点击maintainWeights可以进入权重计算的方法
serverWeight.maintainWeights();
} catch (Exception e) {
logger.error("Error running DynamicServerWeightTask for {}", name, e);
}
}
}
class ServerWeight {
/*该函数主要分为两个步骤
1 根据LoadBalancerStats中记录的每个实例的统计信息,累计所有实例的平均响应时间,
得到总的平均响应时间totalResponseTime,该值用于后面的计算。
2 为负载均衡器中维护的实例清单逐个计算权重(从第一个开始),计算规则为:
weightSoFar+totalResponseTime-实例平均相应时间,其中weightSoFar初始化为0,并且
每计算好一个权重需要累加到weightSoFar上供下一次计算使用。
示例:4个实例A、B、C、D,它们的平均响应时间为10,40,80,100,所以总的响应时间为
230,每个实例的权重为总响应时间与实例自身的平均响应时间的差的累积所得,所以实例A
B,C,D的权重分别为:
A:230-10=220
B:220+230-40=410
C:410+230-80=560
D:560+230-100=690
需要注意的是,这里的权重值只是表示各实例权重区间的上限,并非某个实例的优先级,所以不
是数值越大被选中的概率就越大。而是由实例的权重区间来决定选中的概率和优先级。
A:[0,220]
B:(220,410]
C:(410,560]
D:(560,690)
实际上每个区间的宽度就是:总的平均响应时间-实例的平均响应时间,所以实例的平均响应时间越短
,权重区间的宽度越大,而权重区间宽度越大被选中的概率就越大。
*/
public void maintainWeights() {
ILoadBalancer lb = getLoadBalancer();
if (lb == null) {
return;
}
if (!serverWeightAssignmentInProgress.compareAndSet(false, true)) {
return;
}
try {
logger.info("Weight adjusting job started");
AbstractLoadBalancer nlb = (AbstractLoadBalancer) lb;
//根据负载均衡器的状态信息进行计算
LoadBalancerStats stats = nlb.getLoadBalancerStats();
if (stats == null) {
// no statistics, nothing to do
return;
}
double totalResponseTime = 0;
// 计算所有实例的平均响应时间的总和
for (Server server : nlb.getAllServers()) {
// 如果服务实例的状态快照不在缓存中,那么这里会进行自动加载
ServerStats ss = stats.getSingleServerStat(server);
totalResponseTime += ss.getResponseTimeAvg();
}
// 逐个计算每个实例的权重
Double weightSoFar = 0.0;
// create new list and hot swap the reference
List
//将计算结果进行保存
setWeights(finalWeights);
} catch (Exception e) {
logger.error("Error calculating server weights", e);
} finally {
serverWeightAssignmentInProgress.set(false);
}
}
}
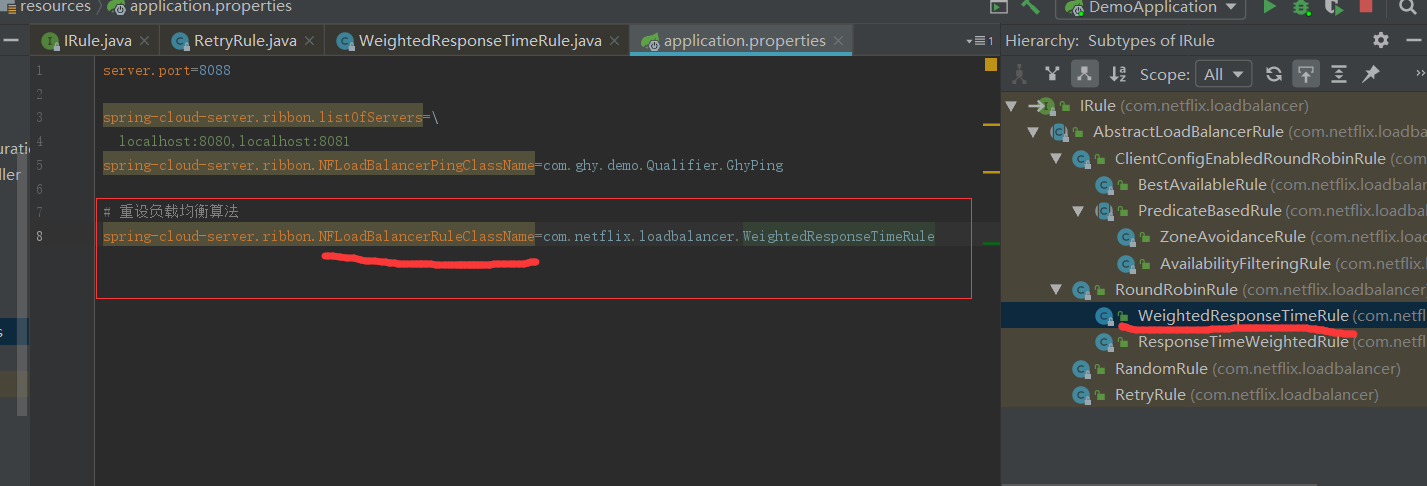
void setWeights(List五、利用配置来重设负载均衡算法
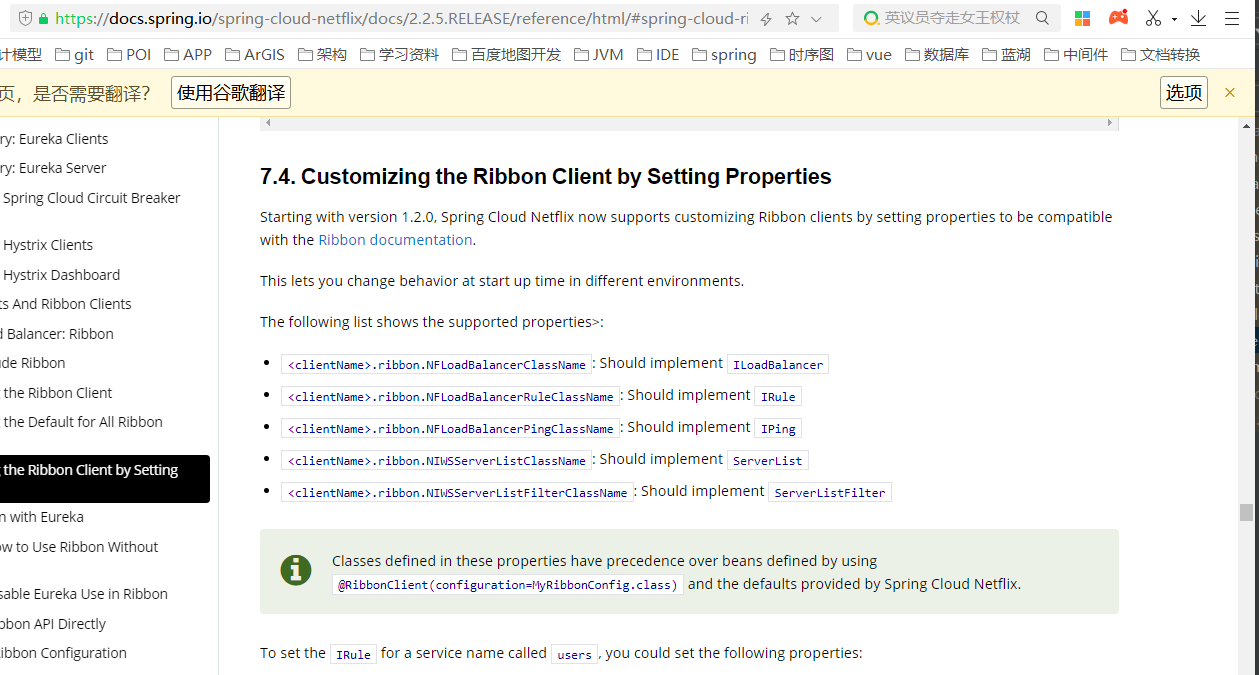
上一篇:Java自学
文章标题:Ribbon提供的负载均衡算法IRule(四)
文章链接:http://soscw.com/index.php/essay/62509.html