14个Q&A,讲述python与数据科学的“暧昧情事”
2021-03-10 02:28
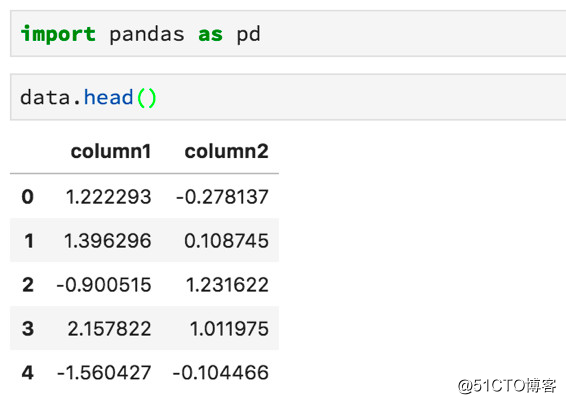
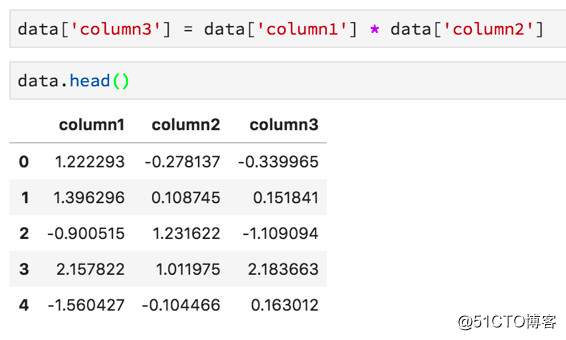
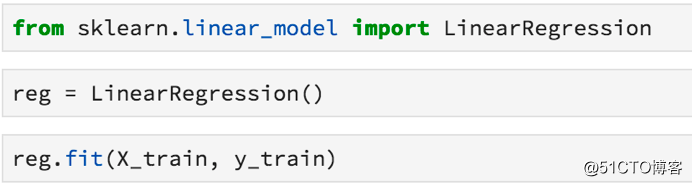
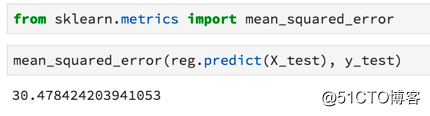
标签:资料 保存 flow 新版本 线数据 单击 通过 dsd 修复 Python最近火了,大红大紫那种。PYPL(编程语言受欢迎程度) 四月官方榜单宣布,Python荣获NO.1,竟然连朋友圈里的文科生都开始转发Python课程打卡的链接了……这是怎样一个令全民疯狂的语言? 作为编程界的“头牌”名媛,Python平易近人的态度和精明婉约的灵动深得各个大佬欢心。比如:人工智能、web开发、爬虫、系统运维、数据分析与计算等等。这几位风流多金的行业精英随便哪个都能“逆转未来”。 本文为你精心准备了一段Python与数据科学的“暧昧史”——用Python进行数据科学概述,包括Numpy,Scipy,pandas,Scikit-Learn,XGBoost,TensorFlow和Keras等模块、包、库的用法。 Python作为一种语言,十项全能,易于学习,安装简单。同时有很多扩展,非常适合进行数据科学研究。像Google、Instagram、Youtube、Reddit等明星网站都在用Python搭建核心业务。 Python不仅仅用于数据科学,还使用Python来做更多的工作——如编写脚本、构建API、构建网站等等。 关于Python的几点重要事项需要注意。 · 目前,有两种常用的Python版本。它们是版本2和3。大多数教程和本文将默认使用的是Python的最新版本Python 3。但有时会遇到使用Python 2的书籍或文章。版本之间的差异并不大,但有时在运行版本3时复制和粘贴版本2代码将无法正常工作,因此需要进行一些轻微的编辑。 · 要注意Python十分介意空白的地方(即空格和返回字符)。如果把空格放在错误的地方,程序很可能会产生错误。 · 与其他语言相比,Python不需要管理内存,也有良好的社区支持。 安装用于数据科学的Python的最佳方法是使用Anaconda发行版。 Anacoda有你使用Python进行数据科学研究所需的资料,包括将在本文中介绍的许多软件包。 单击Products - > Distribution并向下滚动,可以看到适用于Mac,Windows和Linux的安装程序。即使Mac上已经有Python,也应该考虑安装Anaconda发行版,因为有利于安装其他软件包。 此外,还可以去官方Python网站下载安装程序。 包管理器 包是一段Python代码,而不是语言的一部分,包对于执行某些任务非常有帮助。通过包,我们可以复制并粘贴代码,然后将其放在Python解释器(用于运行代码)可以找到的地方。 但这很麻烦,每次启动新项目或更新包时都必须进行内容的复制和粘贴操作。因此,我们可以使用包管理器。Anaconda发行版中自带包管理器。如果没有,建议安装pip。 无论选择哪一个,都可以在终端(或命令提示符)上使用命令轻松安装和更新软件包。 Python迎合许多不同开发人员的技术要求(Web开发人员,数据分析师,数据科学家),因此使用该语言具有很多不同的编程方法。 Python是一种解释型语言,不必将代码编译成可执行文件,只需将包含代码的文本文档传递给解释器即可。 快速浏览一下与Python解释器交互的不同方法吧。 如果打开终端(或命令提示符)并键入单词‘Python‘,将启动一个shell会话。可以在对话中输入有效的Python命令,以实现相应的程序操作。 这可以是快速调试某些东西的好方法,但即使是一个小项目,在终端中调试也很困难。 如果你在文本文件中编写一系列Python命令并使用.py扩展名保存它,则可以使用终端导航到该文件,并通过输入python YOUR_FILE_NAME.py来运行该程序。 这与在终端中逐个输入命令基本相同,只是更容易修复错误并更改程序的功能。 IDE是一种专业级软件,可以进行软件项目管理。 IDE的一个好处是,使用调试功能可以告诉你在尝试运行程序之前出错的位置。 这些方法都不是用python进行数据科学的最佳方式,最好是使用Jupyter Notebooks。 Jupyter Notebooks使你能够一次运行一“块”代码,这意味着你可以在决定下一步做什么之前看到输出信息-这在数据科学项目中非常重要,我们经常需要在获取输出之前查看图表。 如果你正在使用Anaconda,且已经安装了Jupyter lab。要启动它,只需要在终端中输入‘jupyter lab‘即可。 如果正在使用pip,则必须使用命令‘python pip install jupyter‘安装Jupyter lab。 NumPy软件包中包含许多有用的函数,用于执行数据科学工作所需的数学运算。 它作为Anaconda发行版的一部分安装,并且使用pip安装,就像安装Jupyter Notbooks一样简单(‘pip install numpy‘)。 我们在数据科学中需要做的最常见的数学运算是矩阵乘法,计算向量的点积,改变数组的数据类型以及创建数组! 以下是如何将列表编入NumPy数组的方法: 以下是如何在NumPy中进行数组乘法和计算点积的方法: 以下是如何在NumPy中进行矩阵乘法: Scipy包中包含专门用于统计的模块(包的代码的子部分)。 你可以使用‘from scipy import stats‘命令将其导入(在程序中使其功能可用)到你的笔记本中。该软件包包含计算数据统计测量、执行统计测试、计算相关性、汇总数据和研究各种概率分布所需的一切。 以下是使用Scipy快速访问数组的汇总统计信息(最小值,最大值,均值,方差,偏斜和峰度)的方法: 数据科学家必须花费大量的时间来清理和整理数据。幸运的是,Pandas软件包可以帮助我们用代码而不是手工来完成这项工作。 使用Pandas执行的最常见任务是从CSV文件和数据库中读取数据。 它还具有强大的语法,可以将不同的数据集组合在一起(数据集在Pandas中称为DataFrame)并执行数据操作。 使用.head方法查看DataFrame的前几行: 使用方括号选择一列: 通过组合其他列来创建新列: 为了使用pandas read_sql方法,必须提前建立与数据库的连接。 连接数据库最安全的方法是使用Python的SQLAlchemy包。 SQL本身就是一种语言,并且连接到数据库的方式取决于你正在使用的数据库。 有时我们倾向于在数据作为Pandas DataFrame形式到达我们的项目之前,对其进行一些计算。 如果你正在使用数据库或从Web上抓取数据(并将其存储在某处),那么移动数据并对其进行转换的过程称为ETL(提取,转换,加载)。 你从一个地方提取数据,对其进行一些转换(通过添加数据来总结数据,查找均值,更改数据类型等),然后将其加载到可以访问的位置。 有一个非常酷的工具叫做Airflow,它非常善于帮助管理ETL工作流程。更好的是,它是用Python编写的,由Airbnb开发。 有时ETL过程可能非常慢。如果你有数十亿行数据(或者如果它们是一种奇怪的数据类型,如文本),可以使用许多不同的计算机分别进行处理转换,并在最后一秒将所有数据整合到一起。 这种架构模式称为MapReduce,它很受Hadoop的欢迎。 如今,很多人使用Spark来做这种数据转换/检索工作,并且有一个Spark的Python接口叫做PySpark。 MapReduce架构和Spark都是非常复杂的工具,这里我不详细介绍。只要知道它们的存在,如果你发现自己正在处理非常缓慢的ETL过程,PySpark可能会有所帮助。 我们已经知道可以使用Scipy的统计模块运行统计测试、计算描述性统计、p值以及偏斜和峰度等事情,但Python还能做些什么呢? 你应该知道的一个特殊包是Lifelines包。 使用Lifelines包,你可以从称为生存分析的统计子字段计算各种函数。 生存分析有很多应用。我们可以用它来预测客户流失(当客户取消订阅时)以及零售商店何时可能会被盗窃。 这些与包的创造者想象它将被用于完全不同(生存分析传统上是医学统计工具)的领域。但这只是展示了构建数据科学问题的不同方式! 这是一个重要的主题,机器学习正在风靡世界,是数据科学家工作的重要组成部分。 简而言之,机器学习是一组允许计算机将输入数据映射到输出数据的技术。有一些情况并非如此,但它们属于少数,以这种方式考虑ML通常很有帮助。 Python有两个非常好的机器学习包。 在使用Python进行机器学习的时候都会花大部分时间用于使用Scikit-Learn包(有时缩写为sklearn)。 这个包实现了一大堆机器学习算法,并通过一致的语法公开它们。这使得数据科学家很容易充分利用每种算法。 使用Scikit-Learn的一般框架是这样的——将数据集拆分为训练和测试数据集: 实例化并训练一个模型: 使用metrics模块测试模型的工作情况: 在Python中常用于机器学习的第二个包是XGBoost。 Scikit-Learn实现了一系列算法,XGBoost只实现了一个梯度提升的决策树。 训练模型的工作方式与Scikit-Learn算法的工作方式大致相同。 Scikit-Learn中提供的机器学习算法几乎可以满足任何问题。话虽这么说,但有时你需要使用最先进的算法。 由于使用它们的系统几乎优于其他所有类算法,因此深度神经网络的普及率急剧上升。 但是很难说神经网络正在做什么以及它为什么这样做。因此,它们在金融、医学、法律和相关专业中的使用并未得到广泛认可。 神经网络的两大类是卷积神经网络(用于对图像进行分类并完成计算机视觉中的许多其他任务)和循环神经网络(用于理解和生成文本)。 探索神经网工作时超出了本文的范围的机理,如果你想做这类工作,只要知道你需要寻找的包是TensorFlow(Google contibution!)还是Keras。 Keras本质上是TensorFlow的包装器,使其更易于使用。 一旦训练了模型,就可以在其他软件中访问它的预测,方法是创建一个API。 API允许模型从外部源一次一行地接收数据并返回预测。因为Python是一种通用的编程语言,也可用于创建Web服务,所以很容易使用Python通过API为模型提供服务。 如果需要构建API,应该查看pickle和Flask。Pickle允许训练有素的模型被保存在硬盘驱动器上,以便以后使用。而Flask是创建Web服务的最简单方法。 最后,如果你想围绕数据科学项目构建功能齐全的Web应用程序,则应使用Django框架。 Django在Web开发社区非常受欢迎,并且用于构建Instagram和Pinterest的第一个版本(以及许多其他版本)。 14个Q&A,讲述python与数据科学的“暧昧情事” 标签:资料 保存 flow 新版本 线数据 单击 通过 dsd 修复 原文地址:https://blog.51cto.com/15057819/2567752

目录

1. 为何选择Python?

2. 安装Python

3. 使用Python进行数据科学研究
在终端
使用文本编辑器


在IDE中

某些IDE附带了项目模板(用于特定任务),你可以使用这些模板根据最佳实践设置项目。Jupyter Notebooks

4. Python中的数字计算
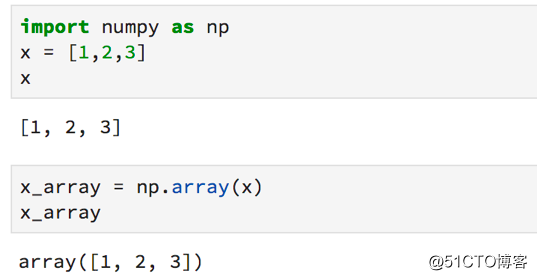



5. Python中的统计分析


6. Python中的数据操作
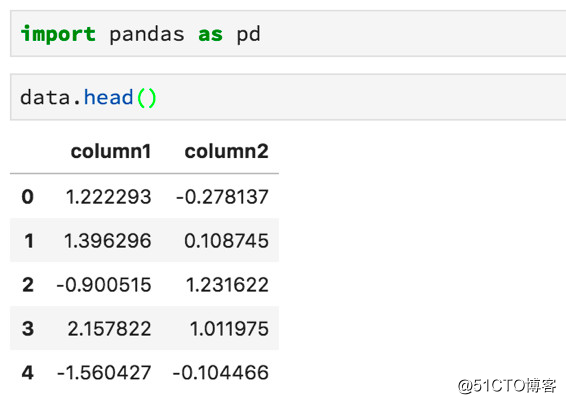

7.在Python中使用数据库

8.Python中的数据工程

9. Python中的大数据工程

10. Python中的进一步统计

11. Python中的机器学习
Scikit-Learn

XGBoost
最近这个包(和算法)因其在Kaggle比赛(任何人都可以参加的在线数据科学比赛)上被使用而取得成功,变得非常受欢迎。
12. Python中的深度学习

13. Python中的数据科学API

14. Python中的Web应用程序

留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货
编译组:张怡雯、赵璇
相关链接:
https://towardsdatascience.com/data-science-with-python-explained-9333b7cef747
如需转载,请后台留言,遵守转载规范推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017 论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾长按识别二维码可添加关注
读芯君爱你

文章标题:14个Q&A,讲述python与数据科学的“暧昧情事”
文章链接:http://soscw.com/index.php/essay/62554.html