七个关键因素:如何选择出最佳机器学习算法?
2021-03-10 20:30
标签:实现 k近邻 定义数据 重要性 测试 algorithm 支持向量机 也会 向量 任意的机器学习问题都可以应用多种算法,生成多种模型。例如,垃圾邮件检测分类问题可以使用多种模型来解决,包括朴素贝叶斯模型、逻辑回归模型和像BiLSTMs这样的深度学习技术。 拥有丰富的选择是好的,但难点在于,如何决定在生产中实现哪个模型。虽然我们有许多性能指标来评估一个模型,但为每个问题实现每个算法是不明智的。这需要大量的时间和大量的工作,因此,知道如何为特定的任务选择正确的算法至关重要。 在本文中,我们将研究可以帮助选择最适合你的项目和特定业务需求的算法的因素,理解这些因素将使你理解模型将要执行的任务和问题的复杂性。 当我们讨论算法的可解释性时,讨论的是它解释其预测的能力,缺乏这种解释的算法被称为黑箱算法。 像k-最近邻算法(k-nearest neighbor,KNN)这样的算法通过特征重要性具有较高的可解释性,而线性模型这样的算法通过赋予特征的权重具有可解释性。当考虑你的机器学习模型最终会做什么时,了解算法的可解释性变得非常重要。 对于诸如检测癌细胞或判断房屋贷款的信用风险等分类问题,必须了解系统结果背后的原因。仅仅预测是不够的,我们需要能够评估它。即使预测是准确的,我们也必须了解导致这些预测的过程。如果理解结果背后的原因是问题的要求,那么需要相应地选择合适的算法。 在选择合适的机器学习算法时,数据点的特征和数量起着至关重要的作用。根据用例的不同,机器学习模型将与各种不同的数据集一起工作,这些数据集的数据点和特征也会有所不同。在某些情况下,选择模型需要理解模型如何处理不同大小的数据集。 像神经网络这样的算法可以很好地处理大量数据和大量特征。但有些算法,如支持向量机,只能处理有限数量的特征。在选择算法时,一定要考虑到数据的大小和特征的数量。 数据通常来自于开源和自定义数据资源的混合,因此它也可以以各种不同的格式出现。最常见的数据格式是分类的和数值的。任何给定的数据集可能只包含分类数据、数字数据或两者的组合。 算法只能处理数值数据,因此如果你的数据在格式上是分类的或非数值的,那么你将需要考虑将其转换为数值数据的过程。 在选择模型之前,了解数据的线性是必要的一步。确定数据的线性有助于确定决策边界或回归线的形状,这反过来指导我们使用的模型。一些诸如身高-体重的关系可以用线性函数表示,这意味着当一个增加时,另一个通常以相同的值增加,这种关系可以用线性模型表示。 了解这一点将帮助你选择合适的机器学习算法。如果数据几乎是线性可分的,或者可以使用线性模型表示,那么支持向量机、线性回归或逻辑回归等算法是一个不错的选择。此外,还可以采用深度神经网络或集成模型。 训练时间是算法学习和创建模型所花费的时间。对于像针对特定用户的电影推荐这样的用例,每次用户登录时都需要对数据进行培训。但是对于像库存预测这样的用例,需要每秒钟都对模型进行训练。因此,考虑训练模型所花费的时间是至关重要的。 众所周知,神经网络需要大量的时间来训练一个模型。传统的机器算法,如k近邻算法和逻辑回归算法,花费的时间要少得多。一些算法,如随机森林,需要根据所使用的CPU内核不同的训练时间。 预测时间是模型进行预测所需要的时间。对于产品通常是搜索引擎或在线零售商店的互联网公司来说,快速预测时间是用户体验顺畅的关键。在这些情况下,速度非常重要,如果预测速度太慢,即使有良好结果的算法也没有用。 然而,在一些业务需求中,准确性比预测时间更重要。比如在我们前面提到的癌细胞的例子中,或者在检测欺诈交易时。支持向量机、线性回归、逻辑回归和几种类型的神经网络等算法可以进行快速预测。然而,像KNN和ensemble模型这样的算法通常需要更多的时间来进行预测。 如果可以将整个数据集加载到服务器或计算机的RAM中,则可以应用大量算法。然而,当这是不可能的,你可能需要采用增量学习算法。 增量学习是一种机器学习方法,通过输入数据不断地扩展已有模型的知识,即进一步训练模型。增量学习算法的目的是适应新的数据而不忘记已有的知识,因此不需要对模型进行再训练。 在为机器学习任务选择算法时,性能似乎是最明显的指标。但仅凭性能还不足以选择出最佳算法,你的模型需要满足其他标准,如内存需求、训练和预测时间、可解释性和数据格式。通过综合更广泛的因素,你可以做出更自信的决定。如果很难在几个选定的模型中选择最佳算法,你也可以在验证数据集上测试它们。 当决定实现一个机器学习模型时,选择正确的模型意味着分析你的需求和预期结果。虽然这可能需要一些额外的时间和努力,但回报是更高的准确性和改进的性能。 长按识别二维码可添加关注 七个关键因素:如何选择出最佳机器学习算法? 标签:实现 k近邻 定义数据 重要性 测试 algorithm 支持向量机 也会 向量 原文地址:https://blog.51cto.com/15057819/2564790
图源:unsplash
可解释性
数据点的数量和特征

图源:unsplash数据格式

图源:unsplash线性数据
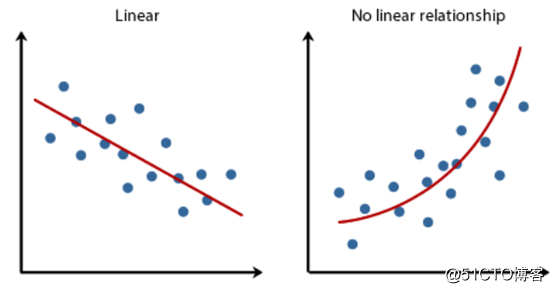
通过散点图理解数据的线性度训练时间
预测时间

图源:unsplash存储需求
留言点赞发个朋友圈
我们一起分享AI学习与发展的干货
编译组:杨娴、符馨元
相关链接:
https://towardsdatascience.com/how-to-select-the-right-machine-learning-algorithm-b907a3460e6f
如转载,请后台留言,遵守转载规范推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
读芯君爱你
文章标题:七个关键因素:如何选择出最佳机器学习算法?
文章链接:http://soscw.com/index.php/essay/62917.html