HTTP基础知识归纳(1)
2021-03-11 10:29
标签:规则 页面 过程 sci poi 结束 网站 主域 详细介绍 每日寄语:等风来不如追风去 如上图可知:HTTP的一次请求过程大致经过以下步骤: 有两点问题需要我们着重关注(面试会问的哦):DNS解析的过程以及TCP的三次握手和四次挥手;如果想深入了解可以参考网上的技术博客。 DNS域名解析大致经过的过程如下: URL的标准格式 其中URL最重要的3个部分是方案 其中我们应注意带有片段的URL的请求:比如:http://www.joes-hardware.com/tools.html#drills; 在这个例子中,片段drills引用了Joe的五金商店的web服务器上页面/tools.html中的一个部分,这个部分的名字叫做dirlls。那这个请求是如何进行的呢?由于HTTP服务器通常只处理整个对象,而不是对象的片段,所以浏览器向服务器发送请求的时会剔除片段向浏览器请求整个资源,浏览器接受资源后会根据片段展示所应该展示的内容。 首先,我们的明白什么是字符集以及一个字符集来说要正确编码转码一个字符需要三个关键元素 字符集:字符集就规定了某个文字对应的二进制数字存放方式(编码)和某串二进制数值代表了哪个文字(解码)的转换关系。 三者之间的关系如下图: 举例: 假如采用ASCII字符集,字符A在字符表中位置为65,65经规则转化为1000001(1000001就存储在编码字符集中),而65和1000001的对应关系就存在了字符编码中,而字符乱码是因为采用不同的编码其映射关系不同解析的数据也就不同了。 问题扩展 (摘录) 看到这里,可能很多读者都会有和我当初一样的疑问:字库表和编码字符集看来是必不可少的,那既然字库表中的每一个字符都有一个自己的序号,直接把序号作为存储内容就好了。为什么还要多此一举通过字符编码把序号转换成另外一种存储格式呢? 其实原因也比较容易理解:统一字库表的目的是为了能够涵盖世界上所有的字符,但实际使用过程中会发现真正用的上的字符相对整个字库表来说比例非常低。例如中文地区的程序几乎不会需要日语字符,而一些英语国家甚至简单的ASCII字库表就能满足基本需求。而如果把每个字符都用字库表中的序号来存储的话,每个字符就需要3个字节(这里以Unicode字库为例),这样对于原本用仅占一个字符的ASCII编码的英语地区国家显然是一个额外成本(存储体积是原来的三倍)。算的直接一些,同样一块硬盘,用ASCII可以存1500篇文章,而用3字节Unicode序号存储只能存500篇。于是就出现了UTF-8这样的变长编码。在UTF-8编码中原本只需要一个字节的ASCII字符,仍然只占一个字节。而像中文及日语这样的复杂字符就需要2个到3个字节来存储。 未完待续。。。。;如果阅读过程中发现文中的知识点有错误的话,可以反馈给我,我们共同来完善。 HTTP基础知识归纳(1) 标签:规则 页面 过程 sci poi 结束 网站 主域 详细介绍 原文地址:https://blog.51cto.com/12666319/2492919
此文章侧重点是将零碎的知识点进行归纳总结;文章大致讲以下知识点:
1、HTTP一次请求流程

2、DNS的域名解析过程
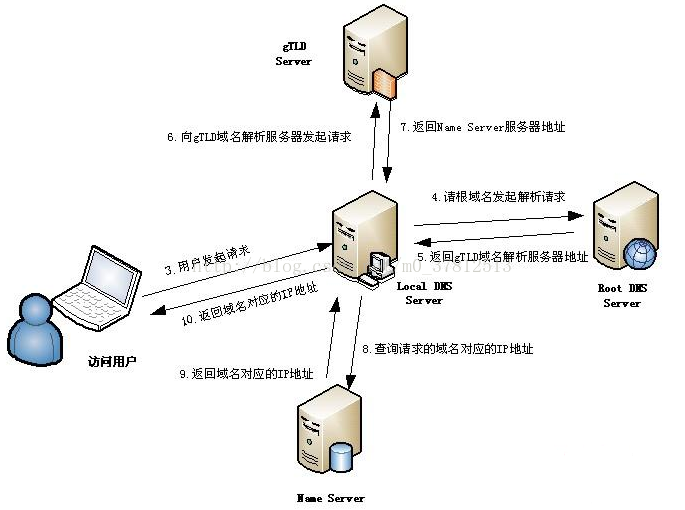
8、LDNS把解析的结果返回给用户,用户根据TTL值缓存到本地系统缓存中,域名解析过程至此结束
3、URL、URI、URN的概念及区别
名 称
描 述
URI
(Uniform Resource Identifier,URI) 统一资源标志符;唯一标志并定位信息资源。
URL
(Uniform Resource Location,URL)统一资源定位符;明确说明如何从一个精准、固定的位置获取资源。下面会详细介绍URL的标准格式。
URN
(Uniform Resource Name,URN) 统一资源名;URN是作为特定内容的唯一名称使用的,与目前的资源所在定无关。
URL的通用格式
4、字符乱码的本质
一个字符集来说要正确编码转码一个字符需要三个关键元素:
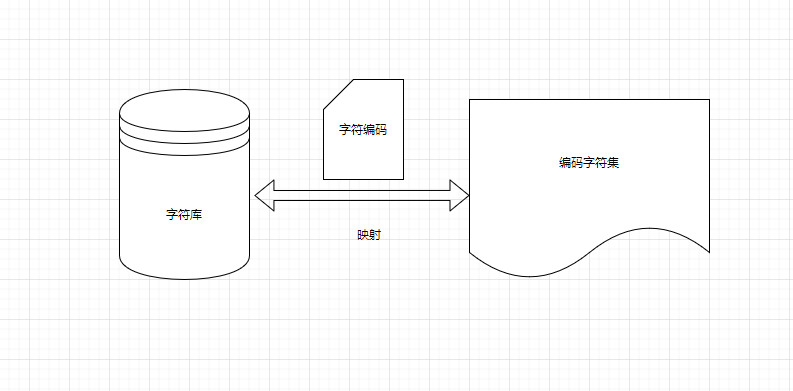
5、参考文献