一步一步搞定Kubernetes二进制部署(四)——多节点部署
2021-03-11 19:27
YPE html>
标签:url linu RKE eset 拷贝 cli 自动 检测 flanneld
一步一步搞定Kubernetes二进制部署(四)——多节点部署前言
? 前面三篇文章已经将单节点的Kubernetes以二进制的方式进行了部署,本文将基于此单节点的配置完成多节点的二进制的Kubernetes部署。
环境和地址规划
master01地址:192.168.0.128/24
master02地址:192.168.0.131/24
node01地址:192.168.0.129/24
node02地址:192.168.0.130/24
负载均衡服务器:主nginx01:192.168.0.132/24
负载均衡服务器:备nginx02:192.168.0.133/24
Harbor私有仓库:192.168.0.134/24
一、master02配置
首先,关闭防火墙和核心防护,这个不再多说。
1、添加master02节点,将master01节点中的核心文件拷贝到master02节点上
复制/opt/kubernetes/目录下的所有文件到master02节点上
[root@master01 ~]# scp -r /opt/kubernetes/ root@192.168.0.131:/opt
The authenticity of host ‘192.168.0.131 (192.168.0.131)‘ can‘t be established.
ECDSA key fingerprint is SHA256:Px4bb9N3Hsv7XF4EtyC5lHdA8EwXyQ2r5yeUJ+QqnrM.
ECDSA key fingerprint is MD5:cc:7c:68:15:75:7e:f5:bd:63:e3:ce:9e:df:06:06:b7.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added ‘192.168.0.131‘ (ECDSA) to the list of known hosts.
root@192.168.0.131‘s password:
token.csv 100% 84 45.1KB/s 00:00
kube-apiserver 100% 929 786.0KB/s 00:00
kube-scheduler 100% 94 92.6KB/s 00:00
kube-controller-manager 100% 483 351.0KB/s 00:00
kube-apiserver 100% 184MB 108.7MB/s 00:01
kubectl 100% 55MB 117.9MB/s 00:00
kube-controller-manager 100% 155MB 127.1MB/s 00:01
kube-scheduler 100% 55MB 118.9MB/s 00:00
ca-key.pem 100% 1679 1.8MB/s 00:00
ca.pem 100% 1359 1.5MB/s 00:00
server-key.pem 100% 1675 1.8MB/s 00:00
server.pem 100% 1643 1.6MB/s 00:00
[root@master01 ~]#
2、拷贝master01节点上三个组件服务启动的文件到master02上
[root@master01 ~]# scp /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service root@192.168.0.131:/usr/lib/systemd/system/
root@192.168.0.131‘s password:
kube-apiserver.service 100% 282 79.7KB/s 00:00
kube-controller-manager.service 100% 317 273.0KB/s 00:00
kube-scheduler.service 100% 281 290.5KB/s 00:00
[root@master01 ~]#
3、修改master02节点的配置文件
主要是对kube-apiserver文件的ip地址进行修改即可
[root@master02 ~]# cd /opt/kubernetes/cfg/
[root@master02 cfg]# ls
kube-apiserver kube-controller-manager kube-scheduler token.csv
下面对kube-apiserver修改#修改第5和第7行的ip地址
2 KUBE_APISERVER_OPTS="--logtostderr=true 3 --v=4 4 --etcd-servers=https://192.168.0.128:2379,https://192.168.0.129:2379,https://192.168.0.130:2379 5 --bind-address=192.168.0.131 6 --secure-port=6443 7 --advertise-address=192.168.0.131 8 --allow-privileged=true 9 --service-cluster-ip-range=10.0.0.0/24 10 --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction 11 --authorization-mode=RBAC,Node 12 --kubelet-https=true 13 --enable-bootstrap-token-auth 14 --token-auth-file=/opt/kubernetes/cfg/token.csv 15 --service-node-port-range=30000-50000 16 --tls-cert-file=/opt/kubernetes/ssl/server.pem 17 --tls-private-key-file=/opt/kubernetes/ssl/server-key.pem 18 --client-ca-file=/opt/kubernetes/ssl/ca.pem 19 --service-account-key-file=/opt/kubernetes/ssl/ca-key.pem 20 --etcd-cafile=/opt/etcd/ssl/ca.pem 21 --etcd-certfile=/opt/etcd/ssl/server.pem 22 --etcd-keyfile=/opt/etcd/ssl/server-key.pem"
4、制作master02的etcd证书
为了保存信息,因此需要将master02节点加入到etcd集群中,那么就需要对应的证书。
我们可以直接将master01的证书拷贝给master02使用
在master01上操作
[root@master01 ~]# scp -r /opt/etcd/ root@192.168.0.131:/opt
root@192.168.0.131‘s password:
etcd.sh 100% 1812 516.2KB/s 00:00
etcd 100% 509 431.6KB/s 00:00
etcd 100% 18MB 128.2MB/s 00:00
etcdctl 100% 15MB 123.7MB/s 00:00
ca-key.pem 100% 1679 278.2KB/s 00:00
ca.pem 100% 1265 533.1KB/s 00:00
server-key.pem 100% 1675 1.4MB/s 00:00
server.pem 100% 1338 1.7MB/s 00:00
[root@master01 ~]#
#建议再在master02上验证一下是否复制成功5、启动master02上的三大组件服务
1、开启apiserver组件服务
[root@master2 cfg]# systemctl start kube-apiserver.service
[root@master2 cfg]# systemctl enable kube-apiserver.service
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-apiserver.service to /usr/lib/systemd/system/kube-apiserver.service.
2、开启 controller-manager 组件服务
[root@master02 cfg]# systemctl start kube-controller-manager.service
[root@master02 cfg]# systemctl enable kube-controller-manager.service
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-controller-manager.service to /usr/lib/systemd/system/kube-controller-manager.service.
3、开启scheduler组件服务
[root@master02 cfg]# systemctl start kube-scheduler.service
[root@master02 cfg]# systemctl enable kube-scheduler.service
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-scheduler.service to /usr/lib/systemd/system/kube-scheduler.service.
[root@master02 cfg]#
4、建议使用systemctl status 命令查看三个服务的状态是否是active(running)状态
优化kubectl命令(设置一下环境变量即可)
systemctl status kube-controller-manager.service
systemctl status kube-apiserver.service
systemctl status kube-scheduler.service #在下面的文件末尾加入一行,声明命令位置
[root@master02 cfg]# vim /etc/profile
export PATH=$PATH:/opt/kubernetes/bin/
[root@master02 cfg]# source /etc/profile
[root@master02 cfg]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/opt/kubernetes/bin/
6、验证master02是否加入Kubernetes的集群中
只需要使用kubectl命令查看是否有node节点信息即可(笔者在实验环境中遇到过执行命令阻塞问题,可以尝试换个终端或者重启该节点服务器再次验证)
[root@master02 kubernetes]# kubectl get node
NAME STATUS ROLES AGE VERSION
192.168.0.129 Ready 18h v1.12.3
192.168.0.130 Ready 19h v1.12.3
二、nginx负载均衡搭建
两台nginx服务器一台为master一台为backup,使用keepalived软件服务实现负载高可用功能
nginx01:192.168.0.132/24
nginx02:192.168.0.133/24
开启两台服务器,设置主机名、关闭防火墙和核心防护,如下所示配置,以nginx01为例
[root@localhost ~]# hostnamectl set-hostname nginx01
[root@localhost ~]# su
[root@nginx01 ~]# systemctl stop firewalld.service
[root@nginx01 ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@nginx01 ~]# setenforce 0 && sed -i "s/SELINUX=enforcing/SELNIUX=disabled/g" /etc/selinux/config
#修改为静态ip地址,重启网络服务后关闭网络管理服务
[root@nginx01 ~]# systemctl stop NetworkManager
[root@nginx01 ~]# systemctl disable NetworkManager
Removed symlink /etc/systemd/system/multi-user.target.wants/NetworkManager.service.
Removed symlink /etc/systemd/system/dbus-org.freedesktop.NetworkManager.service.
Removed symlink /etc/systemd/system/dbus-org.freedesktop.nm-dispatcher.service.
1、配置官方的nginx的yum源,下载nginx
[root@nginx01 ~]# vi /etc/yum.repos.d/nginx.repo
[nginx]
name=nginx.repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
enabled=1
gpgcheck=0
[root@nginx01 ~]# yum list
[root@nginx01 ~]# yum -y install nginx
2、在两台服务器上配置nginx主配置文件
主要是在stream模块中添加日志格式、日志目录以及做负载均衡的upstream设置
此处就以nginx01为例演示
[root@nginx01 ~]# vim /etc/nginx/nginx.conf
events {
10 worker_connections 1024;
11 }
12
13 stream {
14 log_format main ‘$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent‘;
15 access_log /var/log/nginx/k8s-access.log main;
16
17 upstream k8s-apiserver {
18 server 192.168.0.128:6443;
19 server 192.168.0.131:6443;
20 }
21 server {
22 listen 6443;
23 proxy_pass k8s-apiserver;
24 }
25 }
26
3、开启并且验证服务(两台都需要验证)
[root@nginx01 ~]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
[root@nginx01 ~]# systemctl start nginx
[root@nginx01 ~]# netstat -natp | grep nginx
tcp 0 0 0.0.0.0:6443 0.0.0.0:* LISTEN 41576/nginx: master
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 41576/nginx: master 服务开启没问题则什么nginx调度之负载均衡配置完毕,接下来就是使用keepalived实现高可用了
三、keepalived实现高可用集群
1、直接安装keepalived软件以及配置对应节点上的keepalived.conf文件
[root@nginx01 ~]# yum install keepalived -y
#先将原本的配置文件备份,再修改
[root@nginx01 ~]# cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
#主nginx节点的配置文件修改如下
cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_script check_nginx {
script "/etc/nginx/check_nginx.sh"
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.100/24
}
track_script {
check_nginx
}
}
#备份的nginx节点的配置文件修改如下
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_script check_nginx {
script "/etc/nginx/check_nginx.sh" #检测脚本路径,需要自己写
}
vrrp_instance VI_1 {
state BACKUP #表示备份
interface ens33
virtual_router_id 51
priority 90 #优先级低一些
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.100/24 #虚拟ip之前的文章中以及做过设置
}
track_script {
check_nginx
}
}
2、创建检测脚本
[root@nginx01 ~]# vim /etc/nginx/check_nginx.sh
count=$(ps -ef |grep nginx |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
systemctl stop keepalived
fi
#给其权限方便执行
[root@nginx01 ~]# chmod +x /etc/nginx/check_nginx.sh
3、开启keepalived服务
nginx01上:
[root@nginx01 ~]# systemctl start keepalived
[root@nginx01 ~]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; vendor preset: disabled)
Active: active (running) since 二 2020-05-05 19:16:30 CST; 3s ago
Process: 41849 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 41850 (keepalived)
CGroup: /system.slice/keepalived.service
├─41850 /usr/sbin/keepalived -D
├─41851 /usr/sbin/keepalived -D
└─41852 /usr/sbin/keepalived -D
nginx02上:
[root@nginx02 ~]# systemctl start keepalived
[root@nginx02 ~]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; vendor preset: disabled)
Active: active (running) since 二 2020-05-05 19:16:44 CST; 4s ago
Process: 41995 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 41996 (keepalived)
CGroup: /system.slice/keepalived.service
├─41996 /usr/sbin/keepalived -D
├─41997 /usr/sbin/keepalived -D
└─41998 /usr/sbin/keepalived -D
4、在两个节点上查看地址使用ip a命令
此时会发现VIP在nginx01,也就是说是在nginx的master节点上,而backup上还是没有VIP的,可以通过pkill掉nginx01上的nginx进程测试其是否会漂移到nginx02上来验证keepalived的高可用是否配置成功
[root@nginx01 ~]# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:ce:99:a4 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.132/24 brd 192.168.0.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.0.100/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::5663:b305:ba28:b102/64 scope link
valid_lft forever preferred_lft forever
[root@nginx02 ~]# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:71:48:82 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.133/24 brd 192.168.0.255 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::915f:60c5:1086:1e04/64 scope link
valid_lft forever preferred_lft forever
5、测试pkill nginx01的nginx服务
[root@nginx01 ~]# pkill nginx
#进程结束后keepalived服务也会终止
[root@nginx01 ~]# systemctl status keepalived.service
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; vendor preset: disabled)
Active: inactive (dead)
5月 05 19:16:37 nginx01 Keepalived_vrrp[41852]: Sending gratuitous ARP on ens33 for 192.168.0.100
5月 05 19:16:37 nginx01 Keepalived_vrrp[41852]: Sending gratuitous ARP on ens33 for 192.168.0.100
5月 05 19:16:37 nginx01 Keepalived_vrrp[41852]: Sending gratuitous ARP on ens33 for 192.168.0.100
5月 05 19:16:37 nginx01 Keepalived_vrrp[41852]: Sending gratuitous ARP on ens33 for 192.168.0.100
5月 05 19:21:19 nginx01 Keepalived[41850]: Stopping
5月 05 19:21:19 nginx01 systemd[1]: Stopping LVS and VRRP High Availability Monitor...
5月 05 19:21:19 nginx01 Keepalived_vrrp[41852]: VRRP_Instance(VI_1) sent 0 priority
5月 05 19:21:19 nginx01 Keepalived_vrrp[41852]: VRRP_Instance(VI_1) removing protocol VIPs.
5月 05 19:21:19 nginx01 Keepalived_healthcheckers[41851]: Stopped
5月 05 19:21:20 nginx01 systemd[1]: Stopped LVS and VRRP High Availability Monitor.
查看VIP,跳转到nginx02上了
[root@nginx02 ~]# ip ad
1: lo: mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:71:48:82 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.133/24 brd 192.168.0.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.0.100/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::915f:60c5:1086:1e04/64 scope link
valid_lft forever preferred_lft forever
6、恢复keepalived功能
[root@nginx01 ~]# systemctl start nginx
[root@nginx01 ~]# systemctl start keepalived.service
[root@nginx01 ~]# systemctl status keepalived.service
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; vendor preset: disabled)
Active: active (running) since 二 2020-05-05 19:24:30 CST; 3s ago
Process: 44012 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 44013 (keepalived)
CGroup: /system.slice/keepalived.service
├─44013 /usr/sbin/keepalived -D
├─44014 /usr/sbin/keepalived -D
└─44015 /usr/sbin/keepalived -D
验证VIP,会发现又回到了nginx01上
[root@nginx01 ~]# ip ad
1: lo: mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:ce:99:a4 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.132/24 brd 192.168.0.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.0.100/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::5663:b305:ba28:b102/64 scope link
valid_lft forever preferred_lft forever
7、Kubernetes多节点设置配置文件修改
截至目前,我们配置好了基于keepalived软件实现的nginx高可用集群,接下来需要做的一件非常重要的事情就是修改两个node节点上Kubernetes集群配置文件的所有的kubeconfig格式文件,因为之前单节点上我们指向的是master01服务器,而现在是多节点,因此如果指向的还是原先的mater01,那么当master01服务器故障时则会导致服务无法使用。因此我们需要将其指向VIP,通过LB(负载均衡)服务来实现。
[root@node01 ~]# cd /opt/kubernetes/cfg/
[root@node01 cfg]# ls
bootstrap.kubeconfig flanneld kubelet kubelet.config kubelet.kubeconfig kube-proxy kube-proxy.kubeconfig
[root@node01 cfg]# vim bootstrap.kubeconfig
[root@node01 cfg]# awk ‘NR==5‘ bootstrap.kubeconfig
server: https://192.168.0.100:6443
[root@node01 cfg]# vim kubelet.kubeconfig
[root@node01 cfg]# awk ‘NR==5‘ kubelet.kubeconfig
server: https://192.168.0.100:6443
[root@node01 cfg]# vim kube-proxy.kubeconfig
[root@node01 cfg]# awk ‘NR==5‘ kube-proxy.kubeconfig
server: https://192.168.0.100:6443
修改完成后重启node节点服务
[root@node01 cfg]# systemctl restart kubelet
[root@node01 cfg]# systemctl restart kube-proxy
[root@node01 cfg]# grep 100 *
bootstrap.kubeconfig: server: https://192.168.0.100:6443
kubelet.kubeconfig: server: https://192.168.0.100:6443
kube-proxy.kubeconfig: server: https://192.168.0.100:6443
重启之后在nginx01上查看Kubernetes的日志,是以轮循调度将请求分发出去的
[root@nginx01 ~]# tail /var/log/nginx/k8s-access.log
192.168.0.129 192.168.0.128:6443 - [05/May/2020:19:36:55 +0800] 200 1120
192.168.0.129 192.168.0.131:6443 - [05/May/2020:19:36:55 +0800] 200 1118
部署完成进行集群测试
在master01上创建pod资源进行测试
[root@master01 ~]# kubectl run nginx --image=nginx
kubectl run --generator=deployment/apps.v1beta1 is DEPRECATED and will be removed in a future version. Use kubectl create instead.
deployment.apps/nginx created
[root@master01 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-dbddb74b8-djr5h 0/1 ContainerCreating 0 14s
此时正在创建过程的状态,待会再看(30秒到1min左右即可)
[root@master01 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-dbddb74b8-djr5h 1/1 Running 0 75s
目前已经是运行状态了
我们通过kubectl工具来查看刚刚创建的pod中的nginx日志
[root@master01 ~]# kubectl logs nginx-dbddb74b8-djr5h
Error from server (Forbidden): Forbidden (user=system:anonymous, verb=get, resource=nodes, subresource=proxy) ( pods/log nginx-dbddb74b8-r5xz9)
Error的报错原因是因为权限问题,此时我们设置一下就可以了(添加匿名用户给予权限即可)
[root@master01 ~]# kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
clusterrolebinding.rbac.authorization.k8s.io/cluster-system-anonymous created
[root@master01 ~]# kubectl logs nginx-dbddb74b8-djr5h
[root@master01 ~]#
#由于没有访问,因此不会有日志生成我们来查看一下pod的网络信息
[root@master01 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
nginx-dbddb74b8-djr5h 1/1 Running 0 5m52s 172.17.91.3 192.168.0.130
[root@master01 ~]#
我们发现其建立在了130的服务器上,也就是我们的node02服务器上
此时我们可以在node02上访问一下
[root@node02 ~]# curl 172.17.91.3
Welcome to nginx!
Welcome to nginx!
If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.
For online documentation and support please refer to
nginx.org.
Commercial support is available at
nginx.com.
Thank you for using nginx.
由于我们安装了flannel组件,因此我们测试一下再node01的浏览器上访问172.17.91.3是否可以访问该网页,这里的flannel组件挂了,因此需要重新搞定一下,最后测试两个node节点的flannel可以互通(此时地址网段发生改变了)
重新执行那个flannel.sh脚本然后重载进程和重启docker服务
由于之前的flannel地址失效了,因此在master01节点上创建的pod资源分配的地址也无效了,因此可以删除,然后会自动创建新的pod资源
[root@master01 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
nginx-dbddb74b8-djr5h 1/1 Running 0 20s 172.17.91.3 192.168.0.130
[root@master01 ~]# kubectl delete pod nginx-dbddb74b8-djr5h
pod "nginx-dbddb74b8-djr5h" deleted
#新的pod资源如下
[root@master01 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
nginx-dbddb74b8-cnhsl 0/1 ContainerCreating 0 12s 192.168.0.130
[root@master01 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
nginx-dbddb74b8-cnhsl 1/1 Running 0 91s 172.17.70.2 192.168.0.130 然后我们直接在node01节点上的浏览器中访问该地址,结果截图如下:
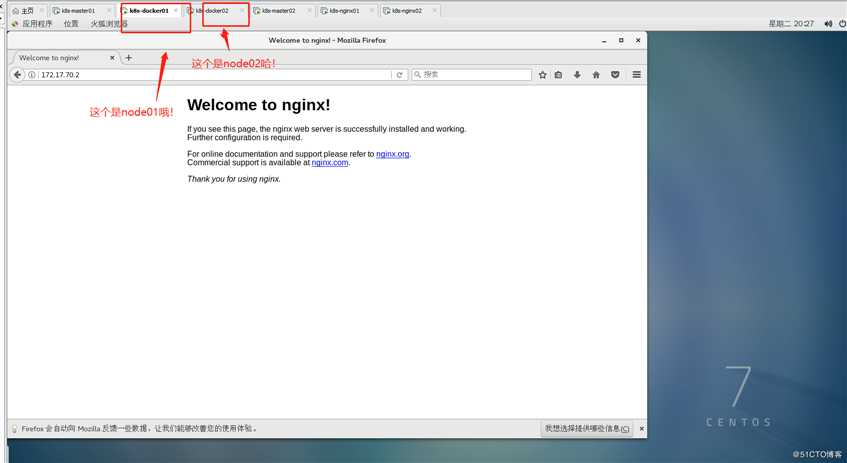
根据该图的结果表示我们的测试成功了
以上就是此次多节点以二进制方式部署的Kubernetes集群了。
总结
此次配置的过程给我的收获是在部署比较复杂的架构时需要注意文件的备份工作,每走一步验证一步,以防越做越错,尽可能在实践之前验证环境和所需开启的服务的状态,最后就是如何解决遇到的一些问题,例如方才的flannel组件挂掉问题,而且还因祸得福,验证了Kubernetes的一个特性——故障自动解决。
谢谢您的阅读!
一步一步搞定Kubernetes二进制部署(四)——多节点部署
标签:url linu RKE eset 拷贝 cli 自动 检测 flanneld
原文地址:https://blog.51cto.com/14557673/2492545
文章标题:一步一步搞定Kubernetes二进制部署(四)——多节点部署
文章链接:http://soscw.com/index.php/essay/63329.html