python | CHROME底层原理和HTTP协议
2021-03-12 09:29
域名和IP地址-映射关系,域名映射为IP的系统叫作“域名系统”,简称DNS。
域名系统DNS是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。
域名如:dadaqianduan.cn (URL地址)
IP地址为:xx.233.xxs.12 (访问)
首先,第一步浏览器会请求DNS返回域名对应的IP,浏览器还提供了DNS数据缓存服务,如果某个域名已经被解析过了,浏览器就会缓存解析的结构,下次查询时直接使用,减少一次网络请求。拿到IP后,就需要获取端口号,如果url没有明确指出端口号,HTTP协议默认是80端口。
到这一步明白的清清楚楚了,IP和端口号。那么让我说说HTTP协议的描述,这里补充是为了更好的了解:
HTTP是一个客户端和服务器端之间请求和应答的标准,通常使用TCP协议,通过使用网页浏览器,网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口,默认端口为80。
应答的服务器上存储着一些资源,如HTML文件和图像等,源服务器;(客户端称为用户代理程序),用户代理和源服务器中间可能存在多个"中间层",比如代理服务器,网关,隧道等。
so,HTTP服务器在端口监听客户端的请求,一旦收到请求,服务器会向客户端返回一个状态,如:"HTTP/1.1 200 OK",以及返回的内容,如请求的文件,错误消息,或者其它消息。
到这里我先回答一下:浏览器发起HTTP请求流程:1.构建请求(构建请求行信息);2.查找缓存(浏览器缓存是一种在本地保存资源副本,以供下次请求时直接使用的技术);3.准备IP地址和端口;4.等待TCP队列;5.建立TCP连接;6.发送HTTP请求。
然后服务器处理请求,服务器返回请求,断开连接。
其实端口和IP地址准备好后,不一定直接建立TCP连接的,因为在Chrome中有个机制,就是同一个域名同时最多只能建立6个TCP连接,如果在同一个域名下同时有10个请求发生,那么其中就有4个请求进入排队等待状态。
如果请求数量少于6个,就直接进入建立TCP连接。
发送HTTP请求
上面都讲好了初步,那么浏览器是如何发送请求信息给服务器的呢?
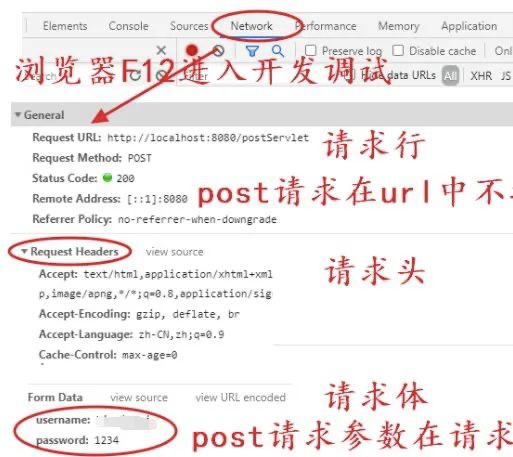
来一张post请求抓包图:
来张浏览器发送请求到服务器端接收返回的过程:
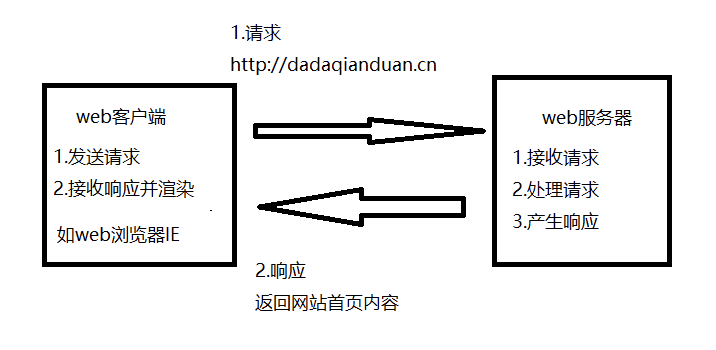
描述:用户在浏览器输入请求的url地址,浏览器内部的核心代码会将这个url进行拆分解析,最终将domain发送到DNS服务器上,DNS服务器会根据domain去查询相关的对应的ip地址,从而将IP地址返回给浏览器。
浏览器有了ip地址后就会知道这个请求是发送到哪里的。经过(局域网,交换机,路由器,主干网咯)到达服务器。
对于经常了解HTTP的朋友应该了解上述表达,那接下来看看HTTP请求数据格式(可看上图->来一张post请求抓包图):
HTTP请求数据格式:
浏览器首先向服务器发送请求行(请求方法;请求URI;HTTP协议版本)-来告诉服务器浏览器需要什么资源,常用请求方法为GET,请求头(用来告诉一些浏览器的基础信息-浏览器所使用的操作系统、浏览器内核等信息,以及当前请求的域名信息、浏览器端的Cookie信息等),请求体(如常用的POST,用于发送一些数据给服务器,准备的数据是通过请求体来发送的)。
服务器处理HTTP请求流程:
-
返回请求;
-
断开连接;
-
重定向。
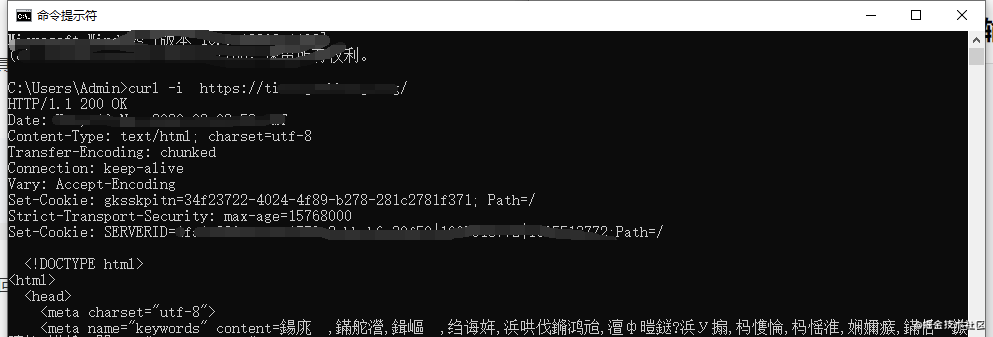
查看返回请求数据,-i,获取返回响应行(包含协议版本和状态码),响应头,响应体数据。
一般情况下,服务器向客户端返回了请求数据,就要关闭TCP连接。但其头信息中加入了该字段:Connection: Keep-Alive,让TCP连接仍然保持连接,可以继续同一个TCP连接发送请求,可以省下次请求时需要建立连接的时间。
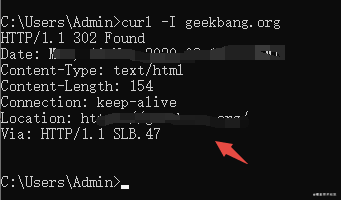
其实一般返回请求,断开连接就没了,但有一种就是你在浏览器中打开的url,发现最终的页面地址不一样,那是因为有一个重定向操作。
如图:-I表示只需要获取响应头和响应行数据
-
location字段时重定向的地址;
状态码301和302的区别
301 Moved Permanently 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。
302 Found 请求的资源现在临时从不同的URI响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。
字面上的区别:301是永久重定向,而302是临时重定向
302重定向是暂时的重定向,搜索引擎会抓取新的内容而保留旧的地址,因为服务器返回302,所以搜索搜索引擎认为新的网址是暂时的。
301重定向是永久的重定向,搜索引擎在抓取新的内容的同时也将旧的网址替换为了重定向之后的网址。
接下来,让我们梳理一下HTTP版本号,这一点,我相信在学习的过程中,大家也是想知道的。
HTTP/0.9:
已过时。仅支持请求方式GET,并且仅能请求访问HTML格式的资源,没有在通讯中指定版本号,且不支持请求头。
HTTP/1.0:
这是第一个在通讯中指定版本号的HTTP协议版本,增加了请求方式POST和HEAD;不再局限于0.9版本的HTML格式,根据Content-Type可以支持多种数据格式;包括状态码(status code)、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等。
1.0版本:每次TCP连接只能发送一个请求,当服务器响应后就会关闭这次连接,下一个请求需要再次建立TCP连接.
HTTP/1.1:
默认采用持续连接(TCP连接默认不关闭,可以被多个请求复用,不用声明Connection: keep-alive),能很好地配合代理服务器工作。
一个TCP连接可以允许多个HTTP请求
增加了管道机制,在同一个TCP连接里,允许多个请求同时发送,增加了并发性,进一步改善了HTTP协议的效率
1.1版规定可以不使用Content-Length字段,而使用"分块传输编码"-只要请求或回应的头信息有Transfer-Encoding字段,就表明回应将由数量未定的数据块组成。Transfer-Encoding: chunked
新增了请求方式PUT、PATCH、OPTIONS、DELETE等
-
分块传输编码:是超文本传输协议中的一种数据传输机制,允许HTTP由网页服务器发送给客户端应用的数据可以分成多个部分,分块传输编码只在HTTP协议1.1版本(HTTP/1.1)中提供。
同一个TCP连接里,所有的数据通信是按次序进行的。回应慢,会有许多请求排队,造成"队头堵塞"。
HTTP/2:
于2015年5月作为互联网标准正式发布。加了双工模式,即不仅客户端能够同时发送多个请求,服务端也能同时处理多个请求,解决了队头堵塞的问题。
使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级。
增加服务器推送的功能,不经请求服务端主动向客户端发送数据。
HTTP1.1相较于HTTP1.0协议区别:
-
缓存处理
-
带宽优化及网络连接的使用
-
错误通知的管理
-
消息在网络中的发送
-
互联网地址的维护
-
安全性及完整性
最后的最后,说第二次站点的打开为啥速度快?
原因是第一次加载页面过程中,缓存了一些耗时的数据,主要缓存有 DNS缓存 和 页面资源缓存 两个方面。
-
浏览器缓存
当第一次发送请求,服务器返回HTTP响应头给浏览器时,浏览器会通过响应头中CacheControl字段来设置是否缓存资源。通常还需设置一个缓存时间,Cache-Control:Max-age=2000,在缓存没有过期的情况下,在发送请求请求该资源,会直接返回缓存中的资源给浏览器。如果缓存过期,浏览器则会继续发起网络请求。
第四问:输入URL到页面展示发生了什么?
简单地说一下就是:
-
浏览器主进程提交url给网络进程
-
网络进程请求服务器,返回响应头行体,判断是否需要重定向
-
网络进程将页面类型的响应资源提交给渲染进程
-
渲染进程渲染结束,加载完毕
分步骤简单说一下就是:
-
首先是域名解析
-
建立TCP链接
-
建立Http请求
-
服务器处理Http请求
-
关闭TCP连接
-
浏览器解析资源
-
浏览器渲染页面
本篇文章的最后,留给你一个面试题,就是上面说到的:“从输入URL到页面展示,这中间发送了什么?”这个问题,如果面试你,你又如何回答呢?
如果你作为面试官,又该考哪些点呢?
总结
以上就是今天要讲的内容,本文简单介绍了Chrome流程,梳理了TCP与HTTP协议,了解三次握手,四次挥手流程,感谢阅读,如果你觉得这篇文章对你有帮助的话,也欢迎把它分享给更多的朋友
文章标题:python | CHROME底层原理和HTTP协议
文章链接:http://soscw.com/index.php/essay/63610.html