nodejs实现定时爬取微博热搜
2021-03-13 11:38
我知道,那些夏天,就像青春一样回不来。 - 宋冬野 青春是回不来了,倒是要准备渡过在西安的第三个夏天了。 我发现,自己对 coding 这件事的称呼,从 emmm....敲代码,自我感觉,就像是,习惯了用 对,优雅! 改编自 子非猿,安之 coding 之乐也。 最近访问 艾特网 的时候发现请求有点慢。 后来经过一番检查,发现首页中搜索热点需要每次去爬取百度热搜的数据并当做接口返回给前端,由于是服务端渲染,接口堵塞就容易出现访问较慢的情况。 就想着对这个接口进行一次重构。 需求捋清楚以后就可以开干了。 首先得找到目标站点,如下:(微博实时热搜) https://s.weibo.com/top/summary?cate=realtimehot 创建文件夹 进入文件夹根目录 使用 创建 安装以下依赖 关于 superagent 是一个轻量级、渐进式的请求库,内部依赖 nodejs 原生的请求 api,适用于 nodejs 环境。 cherrio 是 nodejs 的抓取页面模块,为服务器特别定制的,快速、灵活、实施的 jQuery 核心实现。适合各种 Web 爬虫程序。node.js 版的 jQuery。 打开 首先在顶部引入 通过变量的方式声明热搜的 使用 打开目标站对网页中的 使用 在 接着使用 完整代码如下: 打开终端,输入 虽然代码可以运行,也能爬取到数据并存入 json 文件。 但是,每次都要手动运行,才能爬取到当前时间段的热搜数据,这一点都 最近微博热搜瓜这么多,咱可是一秒钟可都不能耽搁。我们最开始期望的是每隔多长时间 由于 定时任务我们可以使用 先安装 头部引入 用法(每分钟的第 30 秒定时执行一次): 规则参数: 6 个占位符从左到右依次代表:秒、分、时、日、月、周几
更多规则自行搭配。 使用定时任务来执行上面的请求数据,写入文件操作: 哦对,别忘了 下面贴上完整代码(可直接 ctrl c/v): 以上代码可直接集成进现有的 集成进 Serverless,作为接口返回给前端。 对接微信公众号,发送 集成进 微信机器人 ,每天在指定的时间给自己/群里发送微博热搜数据。 other...... 都看到这里啦,就很棒! 下面是咱的公众号呀 代码 github 已开源: https://github.com/isnl/weibo-hotSearch-crawler nodejs实现定时爬取微博热搜 标签:pad pre block wait eth lis 分析 attr 接下来 原文地址:https://www.cnblogs.com/twodog/p/12819886.html
The summer is coming
”
废话
敲代码 改为 写代码 了。const 定义常量的我看到别人用 var 定义的常量。写代码 这三个字,显得更为优雅一些,更像是在创作,打磨一件精致的作品。掘金站长 的一句话:
”
看完本文的收获
为何写爬虫相关的文章
解决方案
1分钟/3分钟/5分钟爬取新浪微博实时热搜(新浪微博热搜点击率更高一些).json格式的文件。json文件的内容
创建工程
初始化
weibonpm init -y 快速初始化一个项目
安装依赖
app.js文件npm i cherrio superagent -D
superagent和cherrio的介绍
”
”
代码编写
app.js ,开始完成主要功能cheerio 、superagent 以及 nodejs 中的 fs 模块const cheerio = require("cheerio");
const superagent = require("superagent");
const fs = require("fs");
url,便于后面 复用const weiboURL = "https://s.weibo.com";
const hotSearchURL = weiboURL + "/top/summary?cate=realtimehot";
superagent
superagent 发送get请求
superagent 的 get 方法接收两个参数。第一个是请求的 url 地址,第二个是请求成功后的回调函数。
回调函数有俩参数,第一个参数为 error ,如果请求成功,则返回 null,反之则抛出错误。第二个参数是请求成功后的 响应体superagent.get(hotSearchURL, (err, res) => {
if (err) console.error(err);
});
网页元素分析
DOM 元素进行一波分析。
 对
对 jQuery 比较熟的小老弟,看到下图如此简洁清晰明了的 DOM 结构,是不是有 N 种取出它每个 tr 中的数据并 push 到一个 Array 里的方法呢?
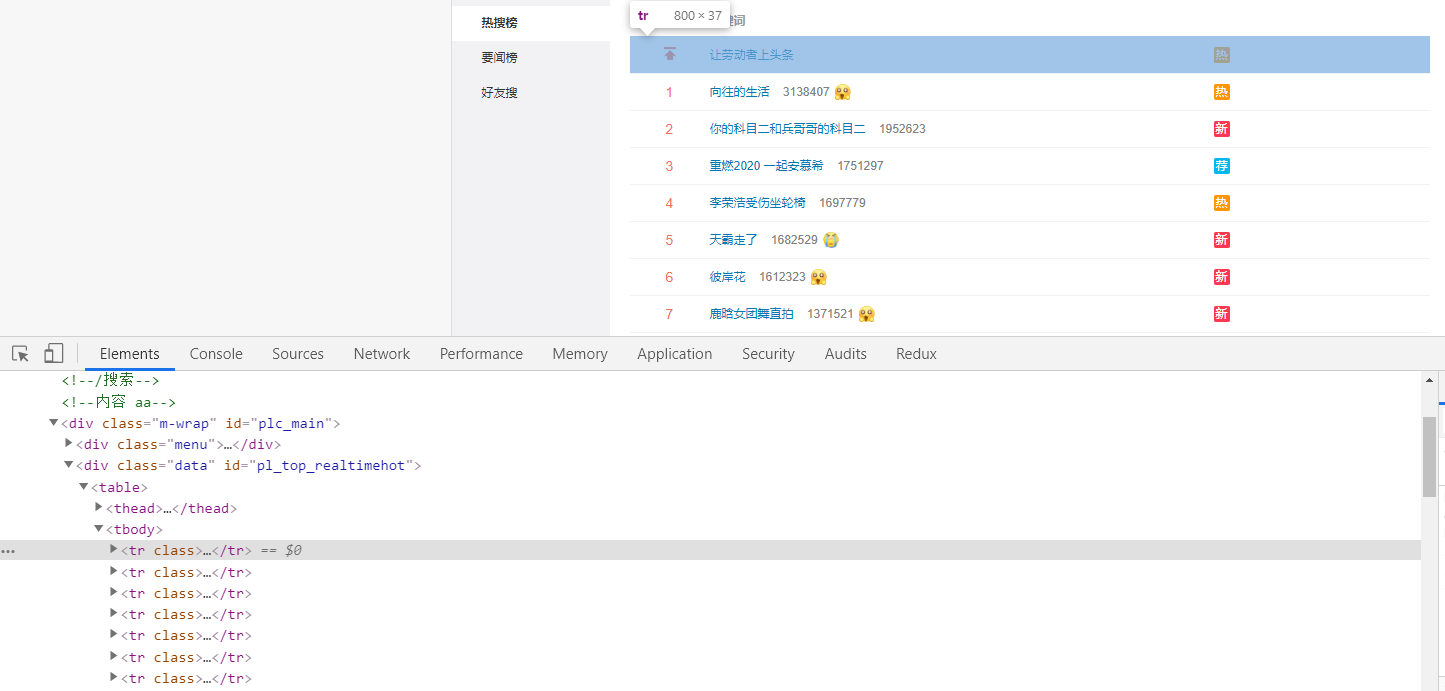 对!我们最终的目的就是要通过
对!我们最终的目的就是要通过 jQuery 的语法,遍历每个 tr ,并将其每一项的 热搜地址 、热搜内容 、 热度值 、序号 、表情等信息 push 进一个空数组中
再将它通过 nodejs 的 fs 模块,写入一个 json 文件中。

jQuery 遍历拿出数据
jQuery 的 each 方法,对 tbody 中的每一项 tr 进行遍历,回调参数中第一个参数为遍历的下标 index,第二个参数为当前遍历的元素,一般 $(this) 指向的就是当前遍历的元素。let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
cheerio 包装请求后的响应体
nodejs 中,要想向上面那样愉快的写 jQuery 语法,还得将请求成功后返回的响应体,用 cheerio 的 load 方法进行包装。const $ = cheerio.load(res.text);
写入 json 文件
nodejs 的 fs 模块,将创建好的数组转成 json字符串,最后写入当前文件目录下的 hotSearch.json 文件中(无此文件则会自动创建)。fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);
const cheerio = require("cheerio");
const superagent = require("superagent");
const fs = require("fs");
const weiboURL = "https://s.weibo.com";
const hotSearchURL = weiboURL + "/top/summary?cate=realtimehot";
superagent.get(hotSearchURL, (err, res) => {
if (err) console.error(err);
const $ = cheerio.load(res.text);
let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);
});
node app,可看到根目录下多了个 hotSearch.json 文件。
定时爬取
不人性化!定时执行爬取 操作。瓜可不能停! 接下来,对代码进行
接下来,对代码进行 小部分改造。
数据请求封装
superagent 请求是个异步方法,我们可以将整个请求方法用 Promise 封装起来,然后 每隔指定时间 调用此方法即可。function getHotSearchList() {
return new Promise((resolve, reject) => {
superagent.get(hotSearchURL, (err, res) => {
if (err) reject("request error");
const $ = cheerio.load(res.text);
let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
hotList.length ? resolve(hotList) : reject("errer");
});
});
}
node-schedule 详解
node-schedule 这个 nodejs库 来完成。
https://github.com/node-schedule/node-schedulenpm i node-schedule -D
const nodeSchedule = require("node-schedule");
const rule = "30 * * * * *";
schedule.scheduleJob(rule, () => {
console.log(new Date());
});
* * * * * *
┬ ┬ ┬ ┬ ┬ ┬
│ │ │ │ │ │
│ │ │ │ │ └ day of week (0 - 7) (0 or 7 is Sun)
│ │ │ │ └───── month (1 - 12)
│ │ │ └────────── day of month (1 - 31)
│ │ └─────────────── hour (0 - 23)
│ └──────────────────── minute (0 - 59)
└───────────────────────── second (0 - 59, OPTIONAL)
* 表示通配符,匹配任意。当 * 为秒时,表示任意秒都会触发,其他类推。
来看一个 每小时的第20分钟20秒 定时执行的规则:20 20 * * * *
定时爬取,写入文件
nodeSchedule.scheduleJob("30 * * * * *", async function () {
try {
const hotList = await getHotSearchList();
await fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);
} catch (error) {
console.error(error);
}
});
捕获异常const cheerio = require("cheerio");
const superagent = require("superagent");
const fs = require("fs");
const nodeSchedule = require("node-schedule");
const weiboURL = "https://s.weibo.com";
const hotSearchURL = weiboURL + "/top/summary?cate=realtimehot";
function getHotSearchList() {
return new Promise((resolve, reject) => {
superagent.get(hotSearchURL, (err, res) => {
if (err) reject("request error");
const $ = cheerio.load(res.text);
let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
hotList.length ? resolve(hotList) : reject("errer");
});
});
}
nodeSchedule.scheduleJob("30 * * * * *", async function () {
try {
const hotList = await getHotSearchList();
await fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);
} catch (error) {
console.error(error);
}
});
各种玩法
express koa eggjs 或者原生的 nodejs 项目中,作为接口返回给前端。热搜 关键字即可实时获取热搜数据。点个赞 再走嘛。
程序员导航站:https://iiter.cn前端糖果屋

下一篇:关于CSS的一些问题(一)