超酷!我不写一行代码,爬取GitHub上几万的Python库
2021-03-14 10:31
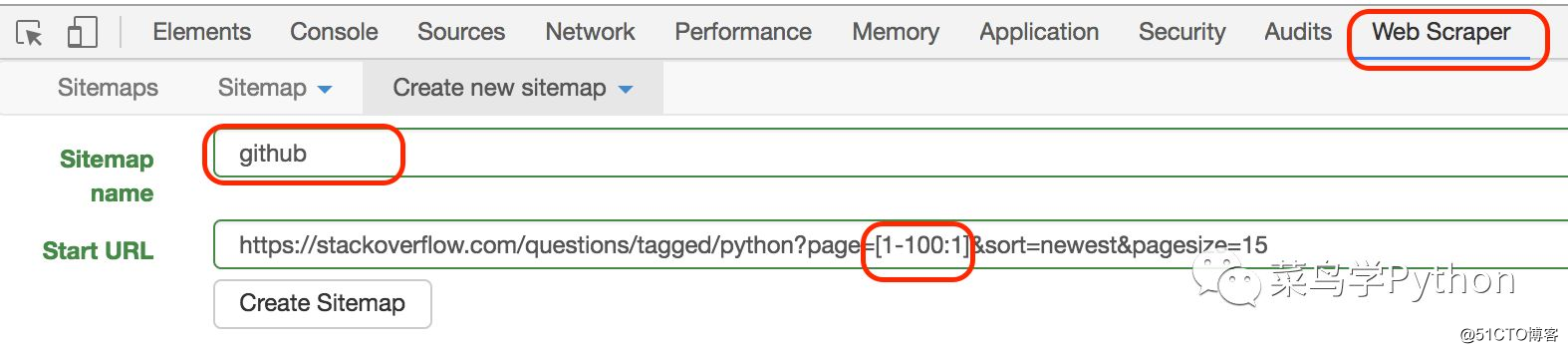
标签:delay exp rap 等等 des 还需 script 一起 rip 跟其他的第三方的数据采集器相比,WebScrapy是一款Google chrome的浏览器的插件,安装成本非常小.直接去WebScrapy官网下载,也可以在chrome里面的store下载. 安装完成之后,你就可以在你的chrome浏览器上看到一个小的蜘蛛网的图标 大名鼎鼎的Github上有很多好玩的库,有几十万个repo.爬取的方法有很多,但是用webscrape爬取非常简单,几分钟就能完成!相比之下如果写一个代码去爬取的就是非常熟练的老手,也需要半个小时才能完成,代码还需要调试。可见神器真的非常方便,成本非常的低,下面我们一步一步来讲解: 1.目标网站分析 2.url分析 3.启动Webscrapy 接着我们填入名字和url的地址,这里的url规则非常简单,我们可以直接构造出100个url的网页,名字可以随便取我们就叫github webscrapy会根据url的规则爬取每一页的内容,类似一个循环。 4.爬取每一页的内容 2).创建item 3).在item里面选择标题,时间,多少颗星 4).在item下创建标题 过程和创建item的非常类似,只是Type选择Text,然后点击Selector从上面的橘黄色的框中选标题,然后点击Done selecting,记得保存.(注意这里的Parents Selector 选的item),大家不要小看这个Parent Selector,会有大用场. 5).类似的我们选取库的description,多少颗,时间元素 5.开始爬取 可以看到我们非常方便的获取的Python库的名字,多少颗星,时间和描述,是不是很简单啊,现在还差最后一招,保存结果。 2). 保存结果 结论: 是不是非常的爽啊,你只要构造多个url就可以爬几万的库,webscrapy对于爬取市面上80%的页面都是非常方便和简单,不用写一行代码,分分钟搞定!对于数据分析的人员来说简直就是福音啊,但是webscrapy也是有利有弊,每一种技术都有它的使用范围.我用它有一段时间了,至少有3个缺点,欢迎大家留言跟我一起讨论. 超酷!我不写一行代码,爬取GitHub上几万的Python库 标签:delay exp rap 等等 des 还需 script 一起 rip 原文地址:https://blog.51cto.com/15009341/2553569
爬虫很有趣,很多同学都在学爬虫,其实爬虫学习有一定的成本,需要考虑静态和动态网页,有一堆的库需要掌握,复杂的需要用scrapy框架,或者用selenium爬取,甚至要考虑反爬策略。如果你不经常爬数据,偶尔用用的话,有一种神器可以非常快速的爬取,分分种上手而且效果很不错的。今天我们就来介绍一下这款神奇"WebScrapy"
安装WebScrapy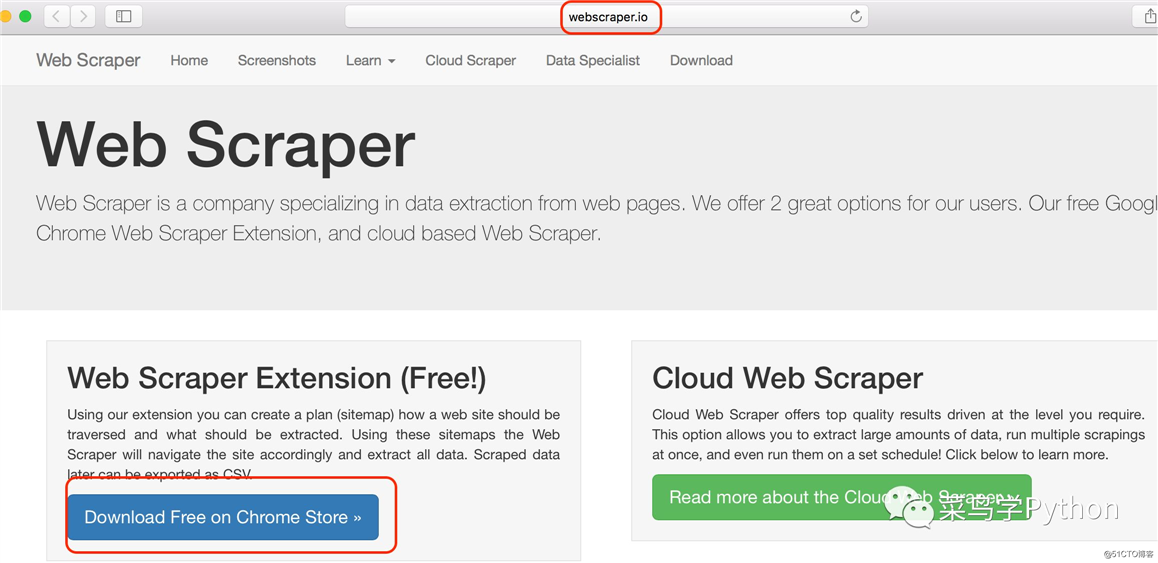
爬取Github上的Python库
Github的网站结构非常简单,也没有啥反爬虫的策略,我们在主页搜索Python就会进入Python相关的主题页面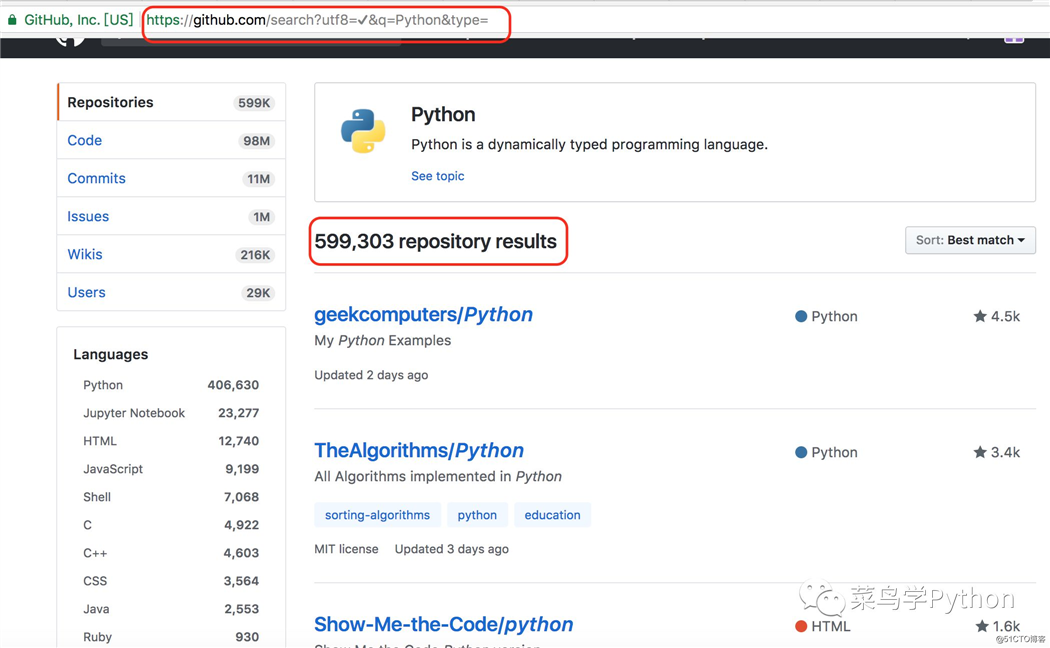
里面有关于Python的Repo近60万个,每一个都有名字,多少颗星,更新时间等等,非常工整的格式.
上面的类别有很多比如Repositories, Code这样的,我们挑其中的一种点击查看:
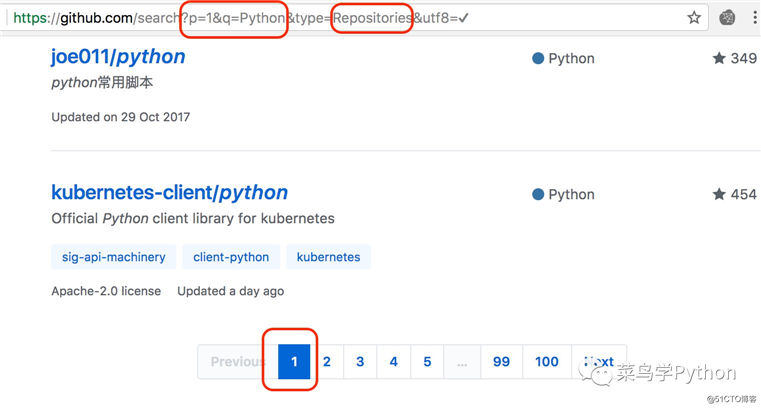
了解上面的url规则之后,其他的网页只要改改上面的参数就行了,比如第2页,
https://github.com/search?p=2&q=Python&type=Repositories&utf8=%E2%9C%93
好下面我们开始爬网页.
网页空白处点击右键选择检查,会进入我们属性网页审查元素的那个界面,在最末尾多一个webscraper菜单,点击Create sitemap创建一个sitemap
Github上的Python的库都是一个一个规整的大列表,webscrapy支持很多类型的不同网页元素的爬取,比如文本,超链接,图片,Element等等,真是用心良苦啊,考虑的非常周全.
1). 增加一个selector
选择我们的Sitemap是Github,然后开始增加一个selector
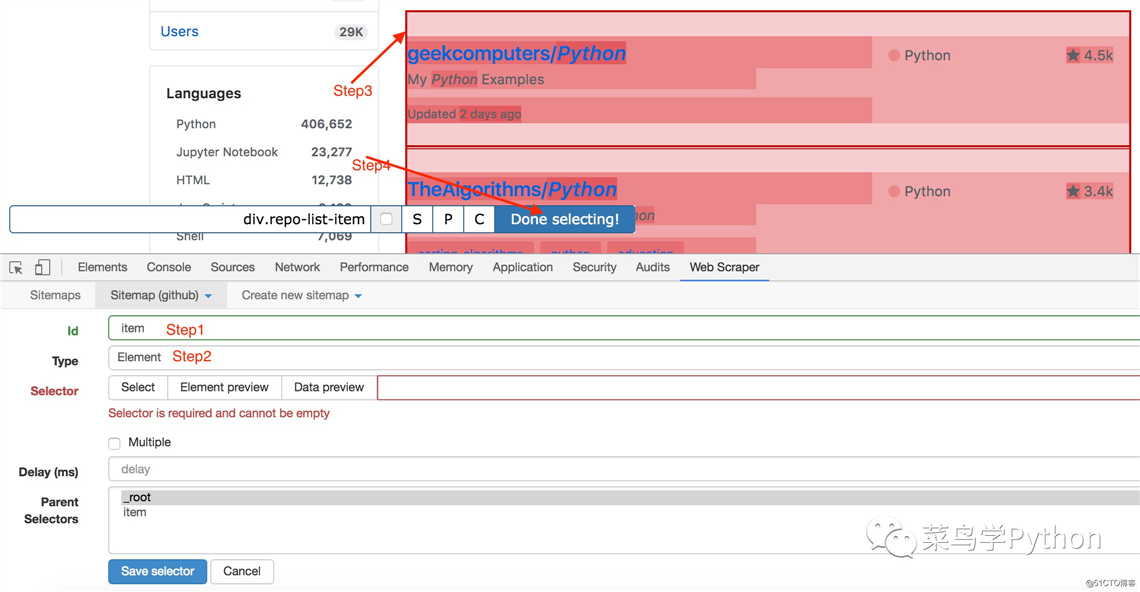
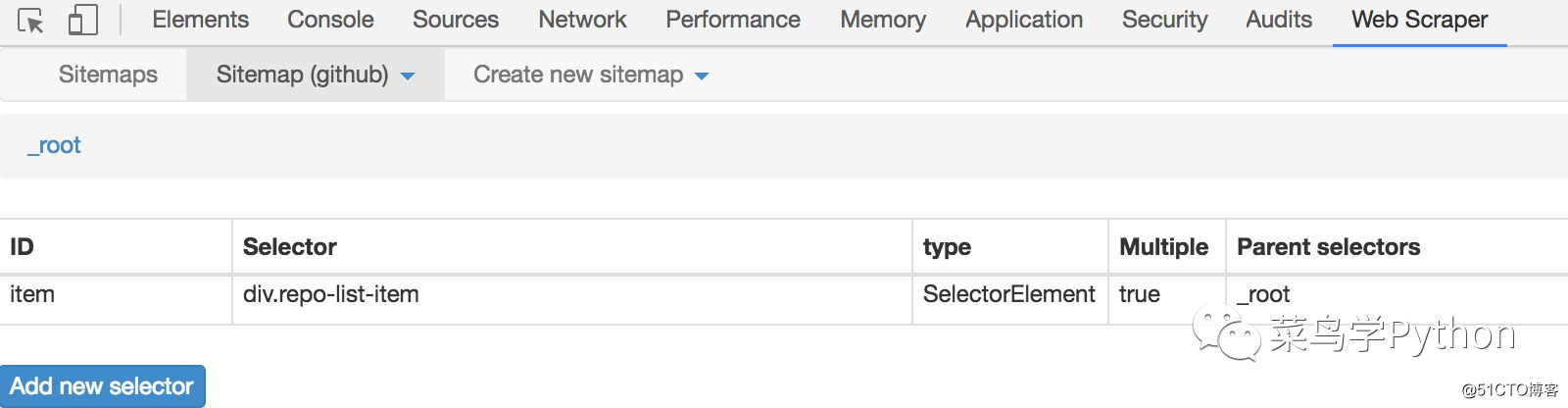
上面我创建了item,item就想是一个收纳架里面有我们需要的内容,我们只需要在这个收纳架上取我们需要的内容,比如标题,时间等等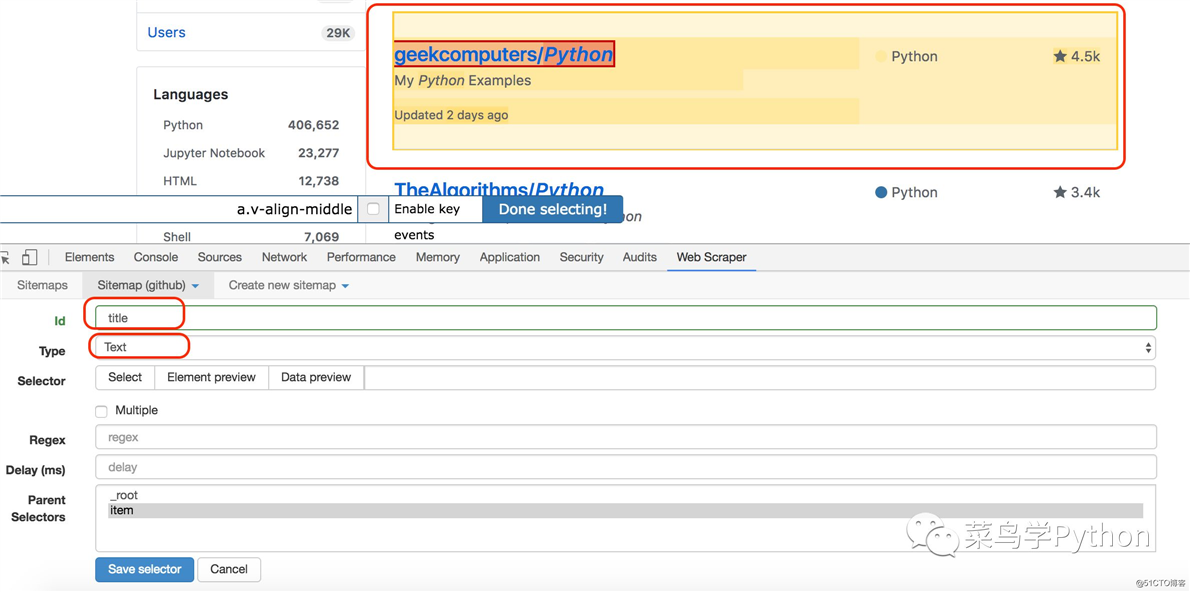
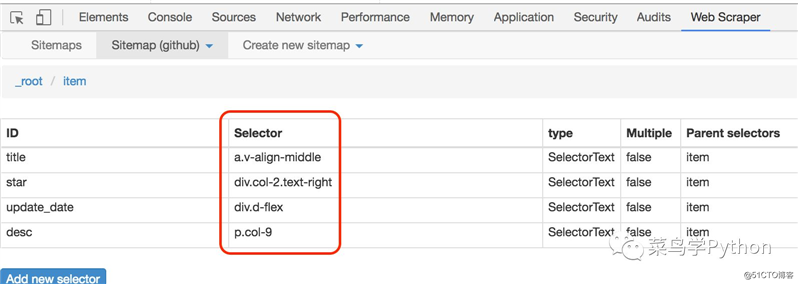
万事具备,我们可以开始愉快的爬取了,只需要点击Sitemap下面的Scrape就可以了。接着会弹出一个请求间隔时间(Request nterval ms) 2秒和页面下载等待时间(Page load delay ms)500,我们都用默认参数就可以了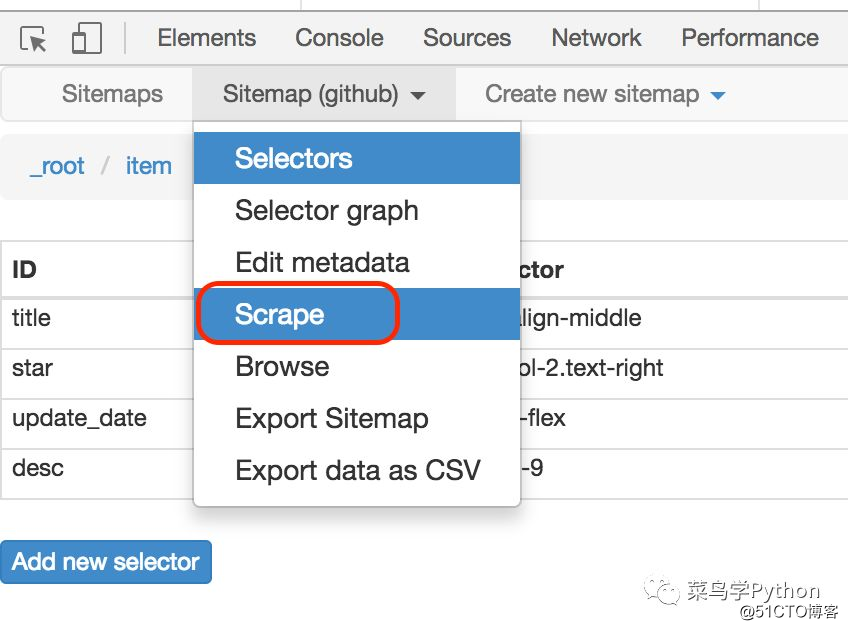
1).看运行结果
WebScrapy会从第100页开始从后往前一页一页的爬取,这个时候你可以倒杯茶,慢悠悠的边喝茶边等待结果,爬取100页大概需要几分钟的时间.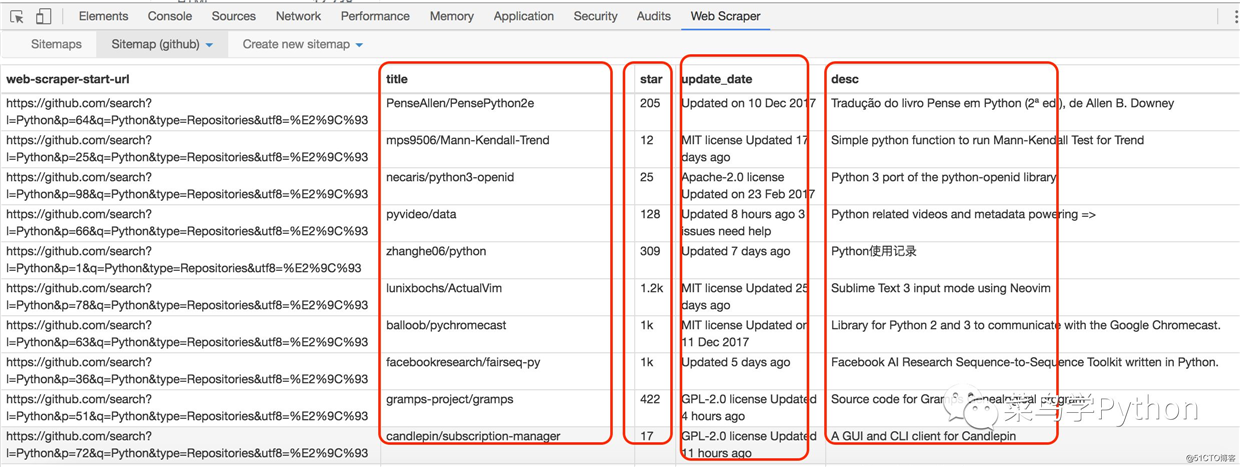
上面的结果是在内存里面的,最后我们需要保存到文件里面,webscraper已经帮我们准备好了,点击sitemap里面的Export data as CSV,然后就会自动生成一个github.csv文件,我们下载就行了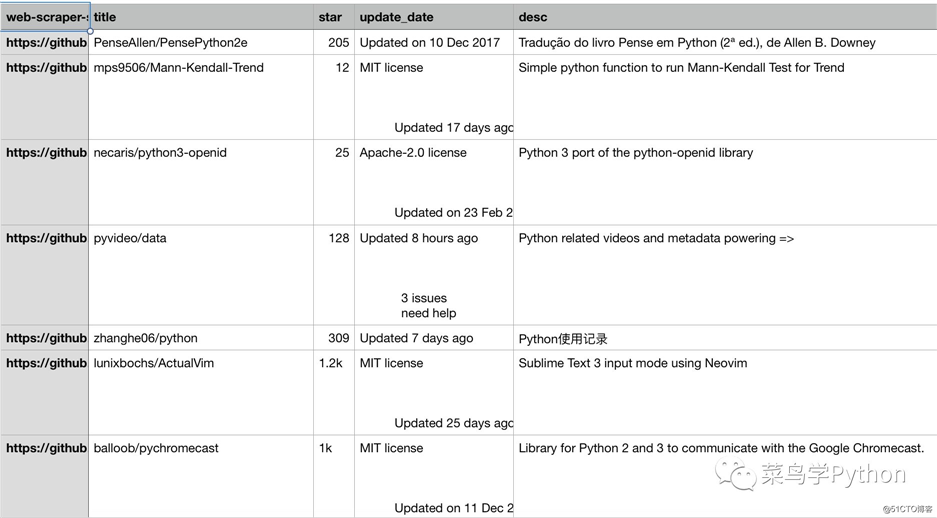
上一篇:机器学习常见算法分类汇总
下一篇:python基础-函数式编程
文章标题:超酷!我不写一行代码,爬取GitHub上几万的Python库
文章链接:http://soscw.com/index.php/essay/64534.html