DataStream API
2021-03-15 00:29
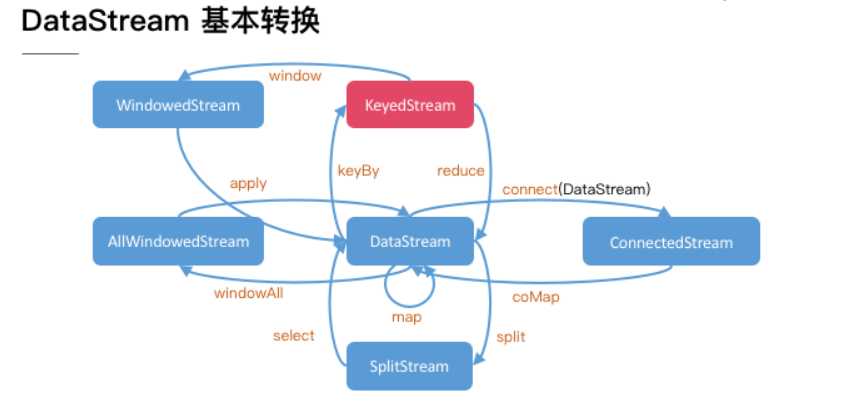
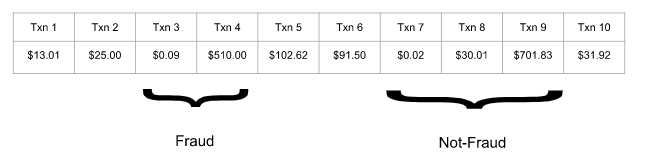
标签:执行环境 根据 main clean mic 方法 opera 表达 好的 Apache Flink 提供了 DataStream API 来实现稳定可靠的、有状态的流处理应用程序。 Flink 支持对状态和时间的细粒度控制,以此来实现复杂的事件驱动数据处理系统。 本文将搭建一个针对可疑信用卡交易行为的反欺诈检测系统。 FraudDetectionJob类定义了程序的数据流 FraudDetectionJob这个例子基本执行了flink程序的整个流程: 从source读取数据 --> processor执行数据 --> 输出数据到sink 流处理系统本身有很多自己的特点。一般来说,由于需要支持无限数据集的处理,流处理系统一般采用一种数据驱动的处理方式。它会提前设置一些算子,然后等到数据到达后对数据进行处理。为了表达复杂的计算逻辑,包括 Flink 在内的分布式流处理引擎一般采用 DAG 图来表示整个计算逻辑,其中 DAG 图中的每一个点就代表一个基本的逻辑单元,也就是前面说的算子。由于计算逻辑被组织成有向图,数据会按照边的方向,从一些特殊的 Source 节点流入系统,然后通过网络传输、本地传输等不同的数据传输方式在算子之间进行发送和处理,最后会通过另外一些特殊的 Sink 节点将计算结果发送到某个外部系统或数据库中。 所以整个flink的函数表示的数据流就是在构建DAG图。 对于实际的分布式流处理引擎,它们的实际运行时物理模型要更复杂一些,这是由于每个算子都可能有多个实例。如图 2 所示,作为 Source 的 A 算子有两个实例,中间算子 C 也有两个实例。在逻辑模型中,A 和 B 是 C 的上游节点,而在对应的物理逻辑中,C 的所有实例和 A、B 的所有实例之间可能都存在数据交换。在物理模型中,我们会根据计算逻辑,采用系统自动优化或人为指定的方式将计算工作分布到不同的实例中。只有当算子实例分布到不同进程上时,才需要通过网络进行数据传输,而同一进程中的多个实例之间的数据传输通常是不需要通过网络的。 从上面的例子中还可以看出,Flink DataStream API 的核心,就是代表流数据的 DataStream 对象。整个计算逻辑图的构建就是围绕调用 DataStream 对象上的不同操作产生新的 DataStream 对象展开的。 FraudDetector类定义了欺诈交易检测的业务逻辑 实现第一版报警程序,对于一个账户,如果出现小于 $1 美元的交易后紧跟着一个大于 $500 的交易,就输出一个报警信息。假设所处理的交易数据如下: 欺诈检测器需要在多个交易事件之间记住一些信息。仅当一个大额的交易紧随一个小额交易的情况发生时,这个大额交易才被认为是欺诈交易。 在多个事件之间存储信息就需要使用到 状态,这也是我们选择使用 KeyedProcessFunction 的原因。 它能够同时提供对状态和时间的细粒度操作,这使得我们能够在接下来的代码练习中实现更复杂的算法。 最直接的实现方式是使用一个 boolean 型的标记状态来表示是否刚处理过一个小额交易。 当处理到该账户的一个大额交易时,你只需要检查这个标记状态来确认上一个交易是是否小额交易即可。 然而,仅使用一个标记作为 FraudDetector 的类成员来记录账户的上一个交易状态是不准确的。 Flink 会在同一个 FraudDetector 的并发实例中处理多个账户的交易数据,假设,当账户 A 和账户 B 的数据被分发的同一个并发实例上处理时,账户 A 的小额交易行为可能会将标记状态设置为真,随后账户 B 的大额交易可能会被误判为欺诈交易。 当然,我们可以使用如 Map 这样的数据结构来保存每一个账户的状态,但是常规的类成员变量是无法做到容错处理的,当任务失败重启后,之前的状态信息将会丢失。 这样的话,如果程序曾出现过失败重启的情况,将会漏掉一些欺诈报警。 为了应对这个问题,Flink 提供了一套支持容错状态的原语,这些原语几乎与常规成员变量一样易于使用。 Flink 中最基础的状态类型是 ValueState,这是一种能够为被其封装的变量添加容错能力的类型。 ValueState 是一种 keyed state,也就是说它只能被用于 keyed context 提供的 operator 中,即所有能够紧随 DataStream#keyBy 之后被调用的operator。 一个 operator 中的 keyed state 的作用域默认是属于它所属的 key 的。 这个例子中,key 就是当前正在处理的交易行为所属的信用卡账户(key 传入 keyBy() 函数调用),而 FraudDetector 维护了每个帐户的标记状态。 ValueState 需要使用 ValueStateDescriptor 来创建,ValueStateDescriptor 包含了 Flink 如何管理变量的一些元数据信息。状态在使用之前需要先被注册。 状态需要使用 open() 函数来注册状态。 骗子们在小额交易后不会等很久就进行大额消费,这样可以降低小额测试交易被发现的几率。 比如,假设你为欺诈检测器设置了一分钟的超时,对于上边的例子,交易 3 和 交易 4 只有间隔在一分钟之内才被认为是欺诈交易。 Flink 中的 KeyedProcessFunction 允许您设置计时器,该计时器在将来的某个时间点执行回调函数。 让我们看看如何修改程序以符合我们的新要求: 要删除一个定时器,需要记录这个定时器的触发时间,这同样需要状态来实现,所以需要在标记状态后也创建一个记录定时器时间的状态。 使用已准备好的 TransactionSource 数据源运行这个代码,将会检测到账户3的欺诈行为,并输出报警信息。 能够在task manager的日志中看到下边输出: DataStream API 标签:执行环境 根据 main clean mic 方法 opera 表达 好的 原文地址:https://www.cnblogs.com/qg000/p/12458036.htmlDataStream API
例子分析
FraudDetectionJob.java
package spendreport;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.walkthrough.common.sink.AlertSink;
import org.apache.flink.walkthrough.common.entity.Alert;
import org.apache.flink.walkthrough.common.entity.Transaction;
import org.apache.flink.walkthrough.common.source.TransactionSource;
public class FraudDetectionJob {
public static void main(String[] args) throws Exception {
//设置执行环境。
//任务执行环境用于定义任务的属性、创建数据源以及最终启动任务的执行。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//创建数据源
//数据源从外部系统例如Apache Kafka、RabbitMQ等接收数据,然后将数据送到 Flink 程序中。
//这里的TransactionSource就是一个可以产生交易数据的数据源,关于数据源之后再解释
DataStream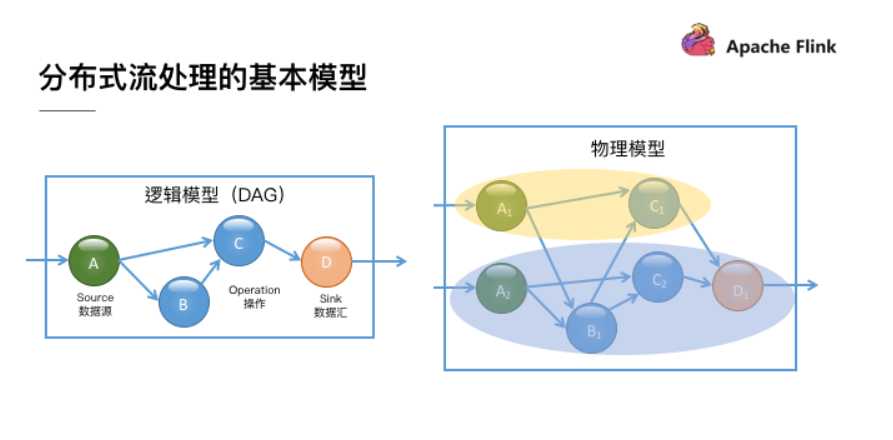
DataStream 对象
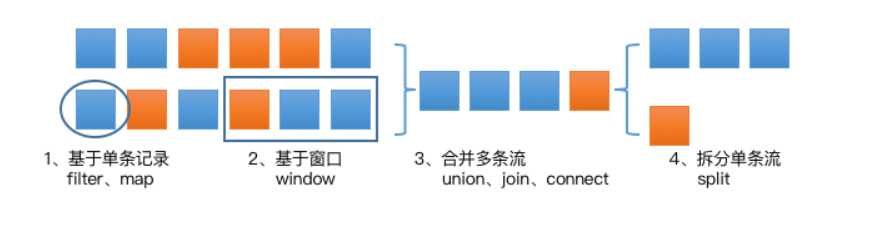
整体来说,DataStream 上的操作可以分为四类:
FraudDetector.java
package spendreport;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.walkthrough.common.entity.Alert;
import org.apache.flink.walkthrough.common.entity.Transaction;
/**
* FraudDetector是KeyedProcessFunction接口的一个实现
* KeyedProcessFunction.processElement()方法会在每个交易时间上被调用
*/
public class FraudDetector extends KeyedProcessFunction实现一个真正的应用程序
public class FraudDetector extends KeyedProcessFunction欺诈检测器v2:状态 + 时间
package spendreport;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.walkthrough.common.entity.Alert;
import org.apache.flink.walkthrough.common.entity.Transaction;
public class FraudDetector extends KeyedProcessFunction期望的结果
2019-08-19 14:22:06,220 INFO org.apache.flink.walkthrough.common.sink.AlertSink - Alert{id=3}
2019-08-19 14:22:11,383 INFO org.apache.flink.walkthrough.common.sink.AlertSink - Alert{id=3}
2019-08-19 14:22:16,551 INFO org.apache.flink.walkthrough.common.sink.AlertSink - Alert{id=3}
2019-08-19 14:22:21,723 INFO org.apache.flink.walkthrough.common.sink.AlertSink - Alert{id=3}
2019-08-19 14:22:26,896 INFO org.apache.flink.walkthrough.common.sink.AlertSink - Alert{id=3}
上一篇:Egg.js 介绍以及环境搭建